
A Lorentz-Equivariant Transformer for All of the LHC
Authors
Johann Brehmer, Víctor Bresó, Pim de Haan, Tilman Plehn, Huilin Qu, Jonas Spinner, Jesse Thaler
Abstract
We show that the Lorentz-Equivariant Geometric Algebra Transformer (L-GATr) yields state-of-the-art performance for a wide range of machine learning tasks at the Large Hadron Collider. L-GATr represents data in a geometric algebra over space-time and is equivariant under Lorentz transformations. The underlying architecture is a versatile and scalable transformer, which is able to break symmetries if needed. We demonstrate the power of L-GATr for amplitude regression and jet classification, and then benchmark it as the first Lorentz-equivariant generative network. For all three LHC tasks, we find significant improvements over previous architectures.
Concepts
The Big Picture
Imagine teaching a GPS to navigate while it doesn’t know the Earth is round. Every route it calculates ignores the curvature underlying every measurement. The GPS still works, sort of, but it wastes enormous effort relearning the same geometric facts for every journey. Something very similar has been happening with machine learning at the Large Hadron Collider.
At the LHC, every particle collision sprays debris at near light speed. The governing geometry isn’t the flat space of everyday experience. It’s Minkowski spacetime, the four-dimensional framework of special relativity where time and space intertwine. The rules describing how measurements change as particles move are called Lorentz transformations, and they mix time and space coordinates together in precise, predictable ways.
Standard neural networks know nothing about this geometry. They can learn it from data, but doing so wastes training examples and makes models brittle when conditions shift.
A team spanning CERN, MIT, Heidelberg, and Amsterdam has built the fix: L-GATr, the Lorentz-Equivariant Geometric Algebra Transformer. A network is equivariant under a symmetry when its outputs transform exactly as its inputs do. Rotate a particle configuration, and the model’s predictions rotate accordingly, with no extra work. L-GATr applies this principle to Lorentz symmetry, achieving state-of-the-art performance across three fundamentally different LHC tasks simultaneously.
Key Insight: By encoding Lorentz symmetry directly into a transformer’s building blocks using geometric algebra, L-GATr learns particle physics more efficiently and accurately than any previous architecture, for regression, classification, and generation.
How It Works
The mathematical engine at L-GATr’s core is the spacetime geometric algebra Cl(1,3), built for the geometry of special relativity. Ordinary algebra operates on numbers; linear algebra on vectors. Geometric algebra goes further, defining a geometric product that generates higher-dimensional objects: bivectors (oriented areas, like the plane swept by a rotating particle) and trivectors (oriented volumes), all within one unified framework. The algebra is built from four basis vectors satisfying the Minkowski metric, so it naturally captures the relativistic geometry of particle collisions.
Every particle’s four-momentum (energy plus three momentum components) maps into this algebra as a multivector: an element of a 16-dimensional space spanning scalars, vectors, bivectors, pseudovectors, and pseudoscalars. When a Lorentz transformation boosts a particle into a new reference frame, every multivector transforms predictably. The network never has to learn this; it’s guaranteed by construction.
Building equivariant layers required rethinking three standard transformer ingredients:
- Linear maps: The authors derived the most general linear map between multivector spaces that stays equivariant under all Lorentz transformations.
- Attention: Inner products used to compute attention scores become Lorentz-invariant contractions between multivectors, preserving relativistic geometry through every attention head.
- Layer normalization: Standard LayerNorm computes norms that break Lorentz invariance. L-GATr replaces it with a normalization that respects the full multivector structure.
One elegant feature: L-GATr can break Lorentz symmetry when the physics demands it. Real LHC detectors have a preferred beam axis, so they aren’t fully Lorentz-symmetric objects. By injecting a fixed reference vector representing the beam direction, L-GATr restricts itself to only the symmetries the beam geometry actually permits.
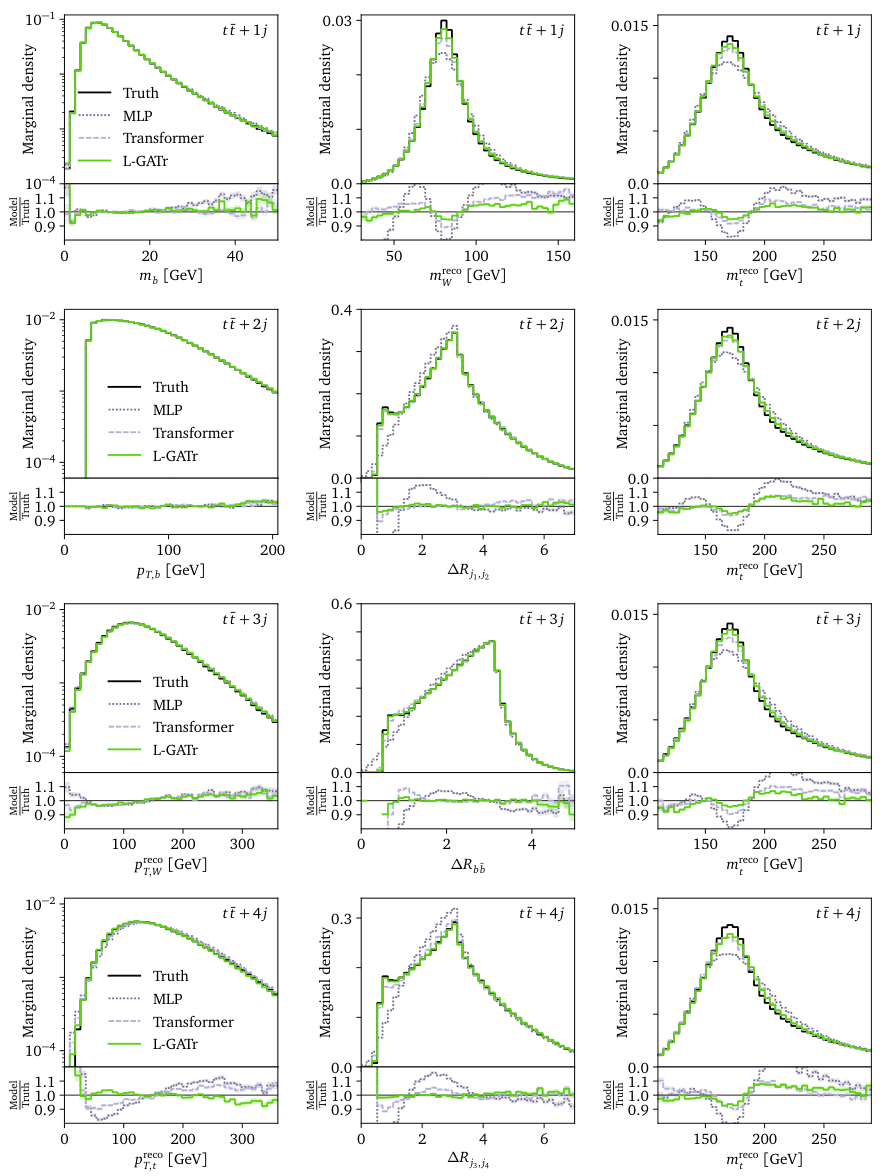
The team benchmarked L-GATr on three distinct tasks. For amplitude regression (predicting the quantum mechanical probability of a scattering process), L-GATr tackled the notoriously complex case of a Z boson produced alongside five gluons, achieving significantly lower error than previous methods. For jet tagging (classifying the particle showers erupting from the collision point), L-GATr with pre-training outperformed both equivariant and non-equivariant architectures. And for event generation, L-GATr became the first Lorentz-equivariant generative network, embedded inside a diffusion model that progressively refines random noise into structured outputs, generating full LHC collision events including top-antitop quark pairs produced with four additional jets.
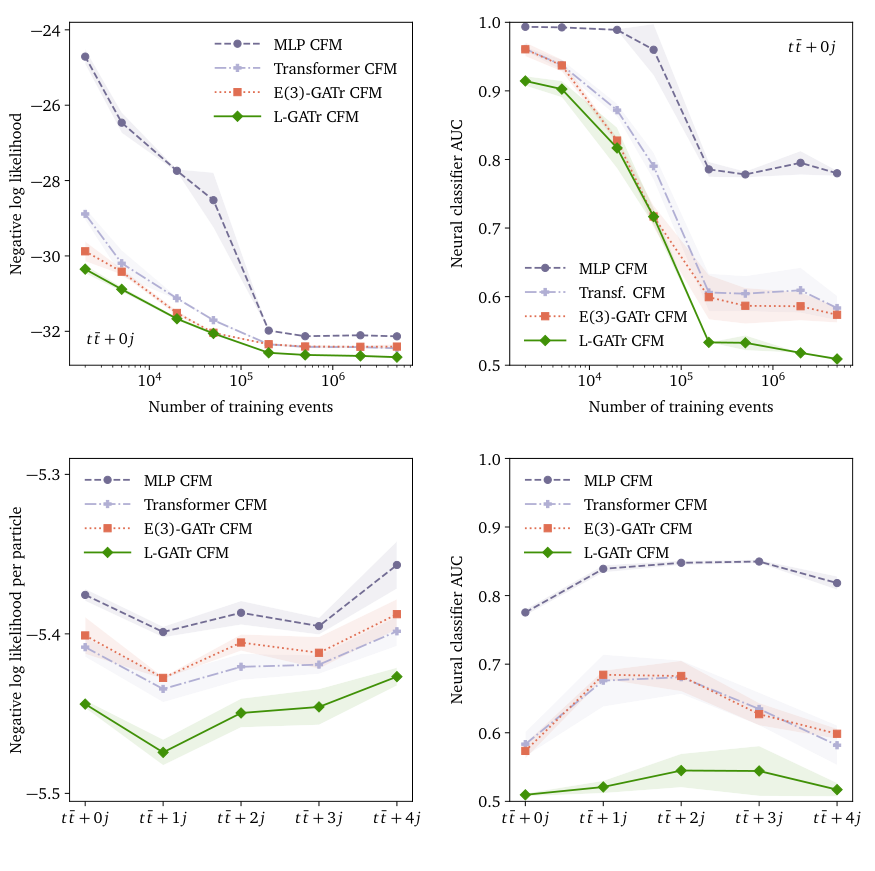
The generative result is the one to watch. Event generators are the backbone of modern particle physics: every comparison between theory and data depends on realistic simulations. Prior generative networks for LHC events ignored Lorentz symmetry entirely. L-GATr’s equivariant diffusion generator matches or beats all baselines in reproducing particle momentum distributions, including rare high-momentum tails where standard generators have historically fallen short.
Why It Matters
The LHC will run for decades. The High-Luminosity upgrade will produce data rates far beyond today’s, and every efficiency gain in ML models translates directly into more physics extracted from the same collisions. Encoding known physics into a model’s design, rather than hoping it discovers that physics from data, pays off most in exactly the precision regime that modern particle physics demands.
L-GATr also points toward something more general: geometric algebra as a universal language for physics-aware AI. The original GATr architecture handles Euclidean geometry; L-GATr extends it to relativistic spacetime. The pattern is the same in both cases. Match a network’s internal representations to the actual geometry of the problem, whether Euclidean or Minkowski, and you get better models that need less data.
Open questions remain. The current implementation handles the exact Lorentz group; extending to discrete symmetries like parity (whether a process looks the same in a mirror) requires additional care. Scaling to higher particle multiplicities will test the architecture’s limits. And deploying equivariant transformers in real-time LHC triggers, where inference must complete in microseconds, is still an engineering challenge. These are tractable problems, and the team’s benchmarking infrastructure provides a clear foundation for follow-on work.
Bottom Line: L-GATr proves that encoding Lorentz symmetry mathematically, not approximately, into a transformer architecture produces best-in-class results for regression, classification, and generation at the LHC, setting a new standard for physics-aware machine learning.
IAIFI Research Highlights
This work fuses abstract mathematical physics (geometric algebra and Lorentz group representation theory) with modern deep learning to produce practical tools for experimental particle physics at the world's leading collider.
L-GATr introduces new equivariant transformer building blocks, including Lorentz-invariant attention and multivector layer normalization, generalizing geometric algebra transformers from Euclidean space to relativistic spacetime.
By achieving state-of-the-art performance on amplitude regression, jet tagging, and event generation simultaneously, L-GATr gives the LHC community a single versatile architecture capable of improving precision across the full experimental pipeline.
Future directions include real-time deployment in LHC triggers, extension to discrete symmetries like parity, and application to higher-multiplicity final states; the full work is available at [arXiv:2411.00446](https://arxiv.org/abs/2411.00446).
Original Paper Details
A Lorentz-Equivariant Transformer for All of the LHC
2411.00446
["Johann Brehmer", "Víctor Bresó", "Pim de Haan", "Tilman Plehn", "Huilin Qu", "Jonas Spinner", "Jesse Thaler"]
We show that the Lorentz-Equivariant Geometric Algebra Transformer (L-GATr) yields state-of-the-art performance for a wide range of machine learning tasks at the Large Hadron Collider. L-GATr represents data in a geometric algebra over space-time and is equivariant under Lorentz transformations. The underlying architecture is a versatile and scalable transformer, which is able to break symmetries if needed. We demonstrate the power of L-GATr for amplitude regression and jet classification, and then benchmark it as the first Lorentz-equivariant generative network. For all three LHC tasks, we find significant improvements over previous architectures.