
A multicategory jet image classification framework using deep neural network
Authors
Jairo Orozco Sandoval, Vidya Manian, Sudhir Malik
Abstract
Jet point cloud images are high dimensional data structures that needs to be transformed to a separable feature space for machine learning algorithms to distinguish them with simple decision boundaries. In this article, the authors focus on jet category separability by particle and jet feature extraction, resulting in more efficient training of a simple deep neural network, resulting in a computational efficient interpretable model for jet classification. The methodology is tested with three to five categories of jets from the JetNet benchmark jet tagging dataset, resulting in comparable performance to particle flow network. This work demonstrates that high dimensional datasets represented in separable latent spaces lead to simpler architectures for jet classification.
Concepts
The Big Picture
Imagine standing at the edge of a fireworks display, trying to identify each shell by the shape of its burst while thousands of explosions go off simultaneously, every second. That’s roughly what physicists face at the Large Hadron Collider, where proton collisions spray cascades of particles outward at nearly the speed of light. These cascades, called jets, are the fingerprints of the fundamental particles that created them. But the fingerprints are messy, overlapping, and arriving faster than any human could ever read.
The LHC generates collision data at 40 million events per second. When the High Luminosity upgrade comes online, that torrent will swell to roughly 50 terabytes of raw particle data every second. Somewhere inside that flood are signals of top quarks, W bosons, Z bosons, gluons, and light quarks, each leaving a subtly different spray pattern in the detector. Some of those patterns look nearly identical to each other. Standard machine learning approaches either drown in the data’s complexity or require enormous, power-hungry neural networks to untangle it.
Researchers at the University of Puerto Rico, Mayaguez, took a different approach. Rather than throwing a bigger model at the problem, they asked: what if you could reorganize the data first so that jets from different sources naturally separate, and then train a simpler network on that cleaner picture?
Key Insight: Transforming raw jet data into a more “separable” feature space before classification lets a simpler neural network achieve competitive accuracy, trading raw computational power for smarter data representation.
How It Works
The raw material is a point cloud, a set of particles each described by four numbers capturing its position in the detector, its direction of travel, its energy, and its mass. Think of it as a three-dimensional scatter plot of individual raindrops in a storm, where each drop also carries metadata about its energy and direction. Straight from the detector, these point clouds look like tangled blobs. Jets from different source particles cluster in ways that make classification unreliable with simple models.
The team built a two-track pipeline:
- Particle feature extraction — A point cloud transformer with multihead attention captures each particle’s local relationships to its neighbors. Multihead attention is the same mechanism that lets large language models weigh how much each word relates to every other word in a sentence; here it encodes how particles relate in terms of energies and trajectories.
- Jet feature extraction — A 1D convolutional autoencoder processes the whole jet’s aggregate properties (type, total transverse momentum, pseudorapidity, and mass) into a compact learned representation. The autoencoder compresses data into a bottleneck layer that retains only the most important features, then reconstructs the input to verify nothing essential was lost.
After merging these two streams, the team added two handcrafted features: particle density (how tightly packed the jet’s particles are) and average intensity (the mean energy deposition). These push different jet categories further apart in the feature space before classification even begins.
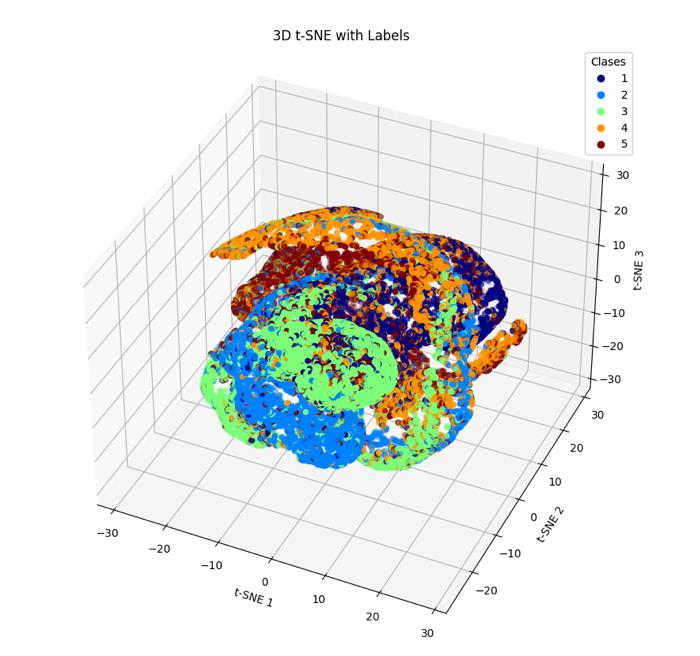
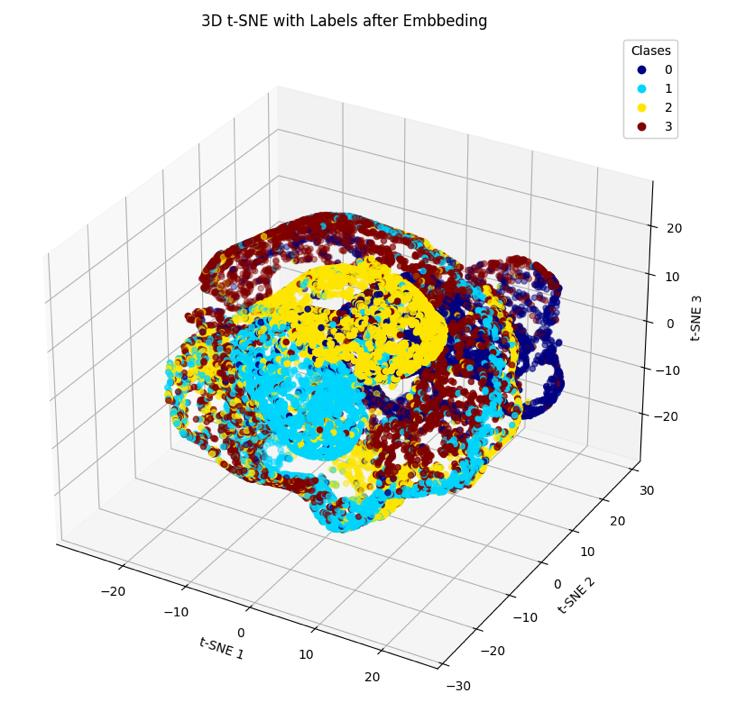
The payoff shows up in 3D plots of the embedded data. Before feature extraction, all five jet classes pile up in an undifferentiated mass. After embedding, the classes fan out into distinct clusters. Once the data looks like that, a straightforward deep neural network (DNN) can draw clean boundaries between classes. No massive transformer, no graph network needed.
Why It Matters
The team tested their framework on the JetNet benchmark dataset: 250,000 jets across five categories, with an 80/20 train-test split. For the full five-class problem (top quark, W boson, Z boson, gluon, and light quark), the model reached 75.98% overall test accuracy. Top quarks, W bosons, and Z bosons each classified above 80%. Gluons and light quarks came in at 65% and 68%, reflecting a genuine physical similarity that even expert physicists struggle to resolve.
Removing one member of that similar pair and reducing to four classes pushed accuracy to 84.00%, with top quarks hitting 88.91%. These numbers are comparable to the Particle Flow Network (PFN), a well-established and considerably more complex benchmark, but achieved with a simpler, more interpretable architecture.
Better jet tagging directly improves the LHC’s ability to identify rare processes, including potential signatures of new particles beyond the Standard Model. Every percentage point of classification accuracy translates into sharper physics reach. At the HL-LHC, where data rates become almost incomprehensible, computational efficiency stops being a nice-to-have and becomes a hard requirement.
The broader lesson here is about representation learning: how you organize data before training can matter as much as the model itself. Investing in the feature space, using transformers for local particle relationships and autoencoders for global jet properties, can replace brute-force model scaling. A well-structured feature space also enables models that researchers can actually interrogate, which matters as “black box” concerns draw increasing scrutiny in both physics and AI.
Bottom Line: By pairing a point cloud transformer with a CNN autoencoder to reorganize jet data before classification, this approach (arXiv:2407.03524) matches state-of-the-art accuracy with a simpler, more interpretable model, offering a template for efficient AI at the extreme data rates of next-generation colliders.
IAIFI Research Highlights
The work borrows attention-based deep learning from NLP and adapts it to the geometric structure of particle jets, showing that cross-domain architectural transfer can yield efficient, physics-grounded solutions.
Constructing a separable feature space through parallel transformer and autoencoder streams reduces model complexity without sacrificing classification performance. The principle applies broadly to any high-dimensional data problem where brute-force scaling hits practical limits.
Improved jet tagging accuracy sharpens physicists' ability to identify rare particle decays and probe physics beyond the Standard Model, squeezing more information from each collision event.
Future extensions could include finer-grained flavor tagging, anomaly detection for new physics searches, and real-time trigger integration at the HL-LHC. The full methodology is described in the authors' [paper](https://arxiv.org/abs/2407.03524) from the University of Puerto Rico, Mayaguez.