
A Neural Scaling Law from Lottery Ticket Ensembling
Authors
Ziming Liu, Max Tegmark
Abstract
Neural scaling laws (NSL) refer to the phenomenon where model performance improves with scale. Sharma & Kaplan analyzed NSL using approximation theory and predict that MSE losses decay as $N^{-α}$, $α=4/d$, where $N$ is the number of model parameters, and $d$ is the intrinsic input dimension. Although their theory works well for some cases (e.g., ReLU networks), we surprisingly find that a simple 1D problem $y=x^2$ manifests a different scaling law ($α=1$) from their predictions ($α=4$). We opened the neural networks and found that the new scaling law originates from lottery ticket ensembling: a wider network on average has more "lottery tickets", which are ensembled to reduce the variance of outputs. We support the ensembling mechanism by mechanistically interpreting single neural networks, as well as studying them statistically. We attribute the $N^{-1}$ scaling law to the "central limit theorem" of lottery tickets. Finally, we discuss its potential implications for large language models and statistical physics-type theories of learning.
Concepts
The Big Picture
Every time AI researchers train a larger model, something predictable happens: the model gets better at its task, following a precise mathematical law. Double the number of parameters (the adjustable numerical settings inside a neural network) and prediction error drops by a specific amount. These neural scaling laws have become one of the most important empirical facts in modern AI, driving billion-dollar investments in ever-larger models. But we still don’t fully understand why they hold.
The standard explanation, developed by Sharma and Kaplan, treats neural networks as tools for fitting mathematical patterns to data. Pack in more parameters, and you can describe that data with finer precision, like drawing a smoother curve through a cloud of points. The math predicts that prediction error should shrink as N^(-4/d), where N is the number of parameters and d reflects how many variables describe a typical data point. It’s a clean story. It’s also sometimes completely wrong.
MIT physicists Ziming Liu and Max Tegmark ran into this problem while studying something almost embarrassingly simple: training a neural network to learn y = x². Their results revealed a hidden mechanism behind scaling laws, one that has nothing to do with fitting functions to data and everything to do with what happens when lucky sub-networks work together.
Key Insight: When neural networks scale up, they don’t just get better at approximating functions — they accumulate more “lottery ticket” sub-networks that pool their estimates, and the resulting variance reduction follows the same statistics as averaging coin flips.
How It Works
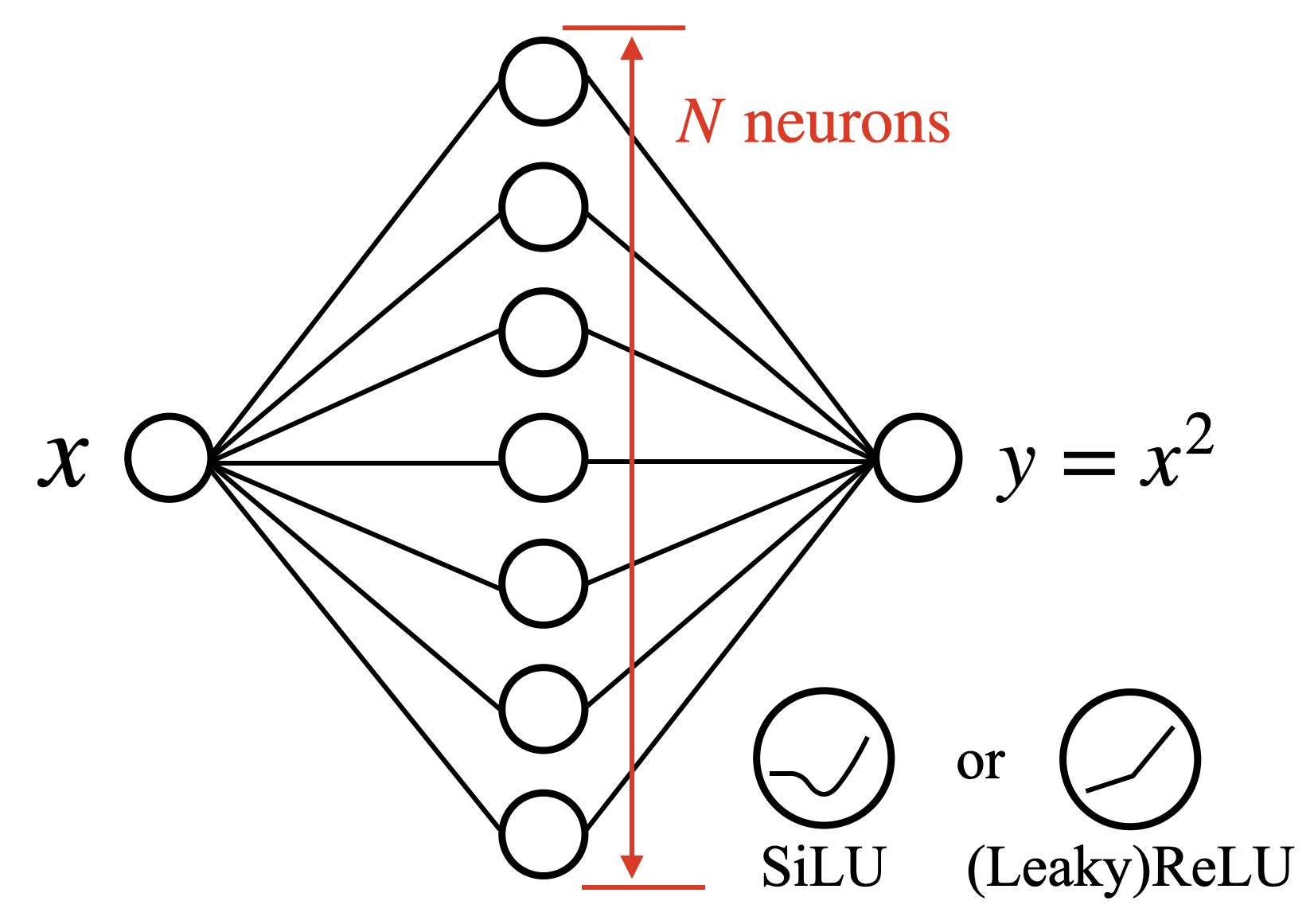
The experimental setup is deliberately stripped-down. Liu and Tegmark trained two-layer networks with a single hidden layer of width N to fit y = x² on the interval [-2, 2], testing two common activation functions:
- ReLU, a piecewise-linear function that outputs zero for negative inputs and passes positive values through unchanged
- SiLU, a smoother variant with curved transitions, increasingly popular in modern architectures
Across 1,000 random starting configurations per width, they recorded the median prediction error.
Standard fitting theory predicts loss should decay as N^(-4) for ReLU networks, since d=1 in this one-dimensional problem, giving exponent α = 4/d = 4. For small N, ReLU networks obey this law. But as networks grow wider, the scaling slows, eventually settling near N^(-1). SiLU networks show the N^(-1) slope from the start, skipping the N^(-4) phase entirely. Something other than fitting precision is controlling performance at scale.
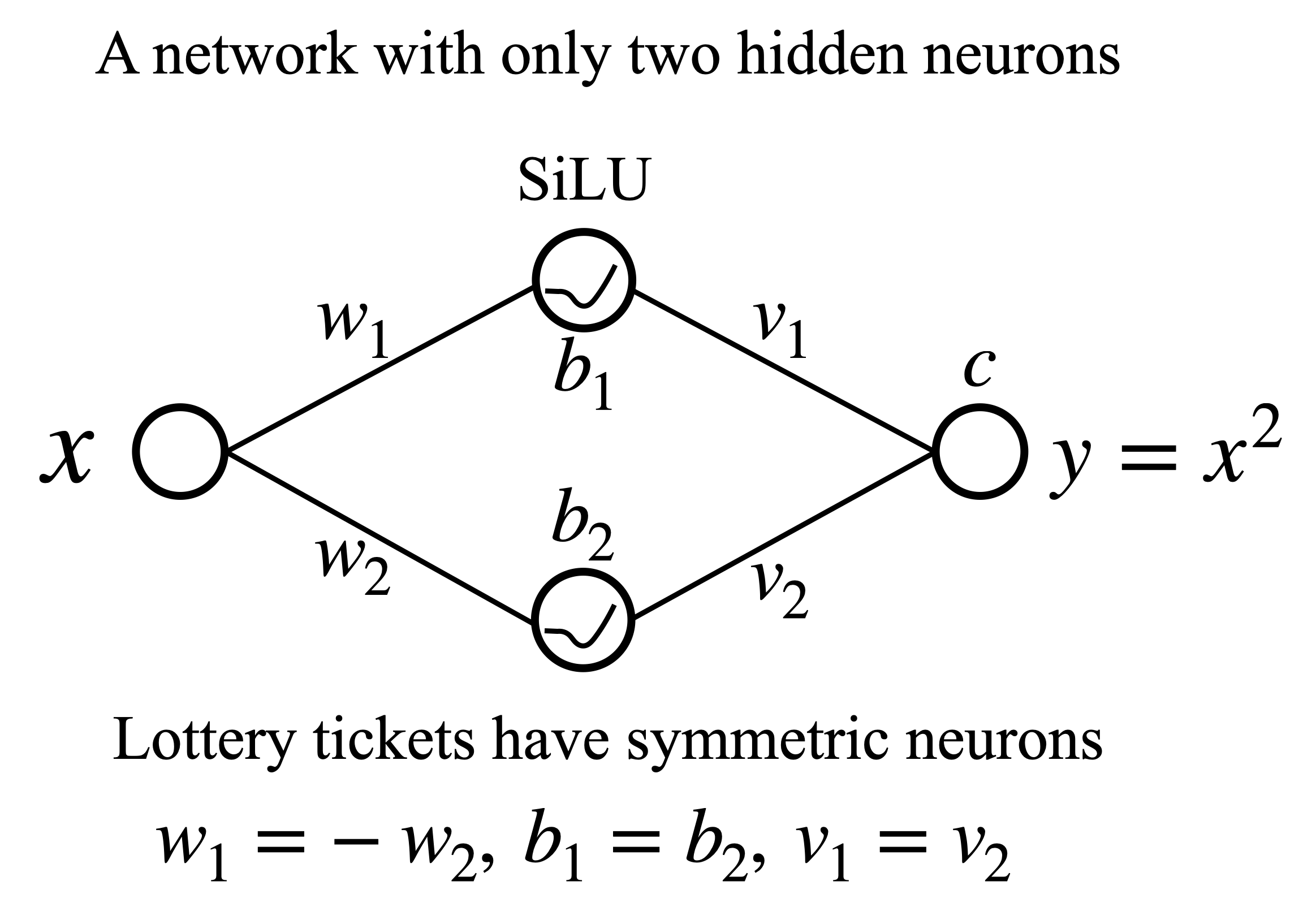
To understand why, the researchers did something increasingly rare in deep learning: they opened the networks and looked inside. In an extremely wide network (N=10,000 SiLU neurons), the learned weights and biases showed a striking pattern of symmetric neurons, pairs that are exact mirror images of each other. For nearly every neuron with parameters (w, b), a corresponding neuron existed with parameters (-w, b). This symmetry guarantees the network represents an even function, which is exactly what y = x² is.
They then trained 1,000 tiny networks with just N=2 neurons. Instead of a smooth spread of outcomes, the results showed discrete peaks, evidence that small networks converge to only a handful of distinct internal “algorithms.” The lowest-loss peak corresponded to networks that had found the symmetric neuron configuration.
Liu and Tegmark called these successful configurations lottery tickets: sub-networks that can solve the problem well on their own. As a network grows wider, it contains proportionally more lottery tickets (n ∝ N). Each produces an independent estimate of the true function, and the network’s output is effectively an average over all of them. This is lottery ticket ensembling, not a designed strategy but an emergent behavior that falls out of training.
Elementary statistics does the rest. Average n independent estimates of the same quantity and variance shrinks as 1/n. Since n grows with N, the loss shrinks as N^(-1). The central limit theorem, the principle behind why averaging many independent estimates always converges toward the truth, is now operating inside neural networks.
Why It Matters
This work pins down a regime where the standard function-fitting explanation for scaling laws breaks down. The ReLU results are particularly telling: fitting theory governs early scaling, but the mechanism switches at larger widths. If large language models operate in a similar regime, the N^(-4/d) predictions may get the scaling exponent wrong, either underestimating the gains from further scale or missing the dominant effect altogether.
The statistical physics angle is what makes this more than a curiosity. The central limit theorem is one of the most universal results in mathematics: it describes why averages of random things converge, regardless of the specific distribution. Finding it at work inside neural scaling laws suggests that macroscopic scaling behavior may emerge from the collective statistics of microscopic computational sub-structures, much as temperature and pressure emerge from the collective behavior of individual molecules.
The theory still needs refinement, and the authors say as much. But the empirical scaffolding is solid and the conceptual picture worth pursuing seriously.
Bottom Line: A surprisingly simple experiment, teaching a neural network to square a number, revealed that “bigger networks work better” sometimes has nothing to do with better approximation and everything to do with averaging over lucky sub-networks. The central limit theorem, not function approximation, may govern scaling in many practical regimes.
IAIFI Research Highlights
This work applies statistical physics reasoning (ensemble averaging and the central limit theorem) to explain a fundamental empirical pattern in deep learning, connecting two fields at the core of IAIFI's research program.
The paper identifies a new mechanism for neural scaling laws that operates independently of approximation theory, challenging prevailing models for why larger networks consistently outperform smaller ones.
By treating neural networks as physical systems where macroscopic laws emerge from microscopic statistics, this work contributes to statistical physics-style theories of learning and complexity.
Future work will test whether lottery ticket ensembling governs scaling in large language models and other high-dimensional settings; the paper is available at [arXiv:2310.02258](https://arxiv.org/abs/2310.02258).
Original Paper Details
A Neural Scaling Law from Lottery Ticket Ensembling
2310.02258
["Ziming Liu", "Max Tegmark"]
Neural scaling laws (NSL) refer to the phenomenon where model performance improves with scale. Sharma & Kaplan analyzed NSL using approximation theory and predict that MSE losses decay as $N^{-α}$, $α=4/d$, where $N$ is the number of model parameters, and $d$ is the intrinsic input dimension. Although their theory works well for some cases (e.g., ReLU networks), we surprisingly find that a simple 1D problem $y=x^2$ manifests a different scaling law ($α=1$) from their predictions ($α=4$). We opened the neural networks and found that the new scaling law originates from lottery ticket ensembling: a wider network on average has more "lottery tickets", which are ensembled to reduce the variance of outputs. We support the ensembling mechanism by mechanistically interpreting single neural networks, as well as studying them statistically. We attribute the $N^{-1}$ scaling law to the "central limit theorem" of lottery tickets. Finally, we discuss its potential implications for large language models and statistical physics-type theories of learning.