
A Poisson Process AutoDecoder for X-ray Sources
Authors
Yanke Song, Victoria Ashley Villar, Juan Rafael Martinez-Galarza, Steven Dillmann
Abstract
X-ray observing facilities, such as the Chandra X-ray Observatory and the eROSITA, have detected millions of astronomical sources associated with high-energy phenomena. The arrival of photons as a function of time follows a Poisson process and can vary by orders-of-magnitude, presenting obstacles for common tasks such as source classification, physical property derivation, and anomaly detection. Previous work has either failed to directly capture the Poisson nature of the data or only focuses on Poisson rate function reconstruction. In this work, we present Poisson Process AutoDecoder (PPAD). PPAD is a neural field decoder that maps fixed-length latent features to continuous Poisson rate functions across energy band and time via unsupervised learning. PPAD reconstructs the rate function and yields a representation at the same time. We demonstrate the efficacy of PPAD via reconstruction, regression, classification and anomaly detection experiments using the Chandra Source Catalog.
Concepts
The Big Picture
Imagine trying to understand a conversation where most of the words have been dropped. You might catch a few syllables here, a phrase there, and from these sparse fragments, you need to reconstruct what was said, classify the speaker, and flag anything unusual. That’s roughly the challenge astronomers face when studying X-ray sources in the night sky.
X-ray telescopes like NASA’s Chandra X-ray Observatory don’t capture smooth, continuous streams of light. They detect individual photons, tiny packets of high-energy light, arriving one by one. For faint sources, a telescope might collect only a handful of photons across an entire observation. Yet those photons carry real information: which type of object is emitting them (a neutron star? a black hole? a galaxy?), how the emission changes over time, and whether anything unusual is happening.
With facilities like Chandra, XMM-Newton, and eROSITA collectively cataloging roughly two million X-ray sources, automated intelligent analysis isn’t optional anymore.
A team from Harvard, the Center for Astrophysics, and Stanford has developed a new framework called the Poisson Process AutoDecoder (PPAD). The name reflects the core idea: photons from an X-ray source arrive randomly in time, but at a predictable average rate, a pattern mathematicians call a Poisson process. Rather than treating this randomness as noise to work around, PPAD learns to describe and categorize sources directly from it.
Key Insight: PPAD learns compact, useful descriptions of X-ray sources directly from raw photon arrival data, without ever needing human-assigned labels, by modeling the data as what it actually is: a Poisson process.
How It Works
When a photon arrives at Chandra’s detector, the telescope records two things: when it arrived and how much energy it had. This produces what astronomers call an event file, a list of timestamps and energies.
The underlying process is Poisson: each photon arrives unpredictably, but the average arrival rate tells you something real about the source. Think of raindrops hitting a window. Each drop is random, but the rate per minute reflects actual weather. Traditional machine learning approaches sidestep all of this by binning data into histograms, turning the list into a grid of counts. That destroys information, especially for faint sources where a single bin might contain zero or one photon.
PPAD takes a different path. At its heart is a neural field, a neural network that represents a continuous, smooth function rather than a discrete lookup table. Instead of counting photons per bin, PPAD learns a smooth function that, given any moment in time and any energy band, outputs the expected photon arrival rate. The model captures fine structure in source variability without committing to any particular time resolution.
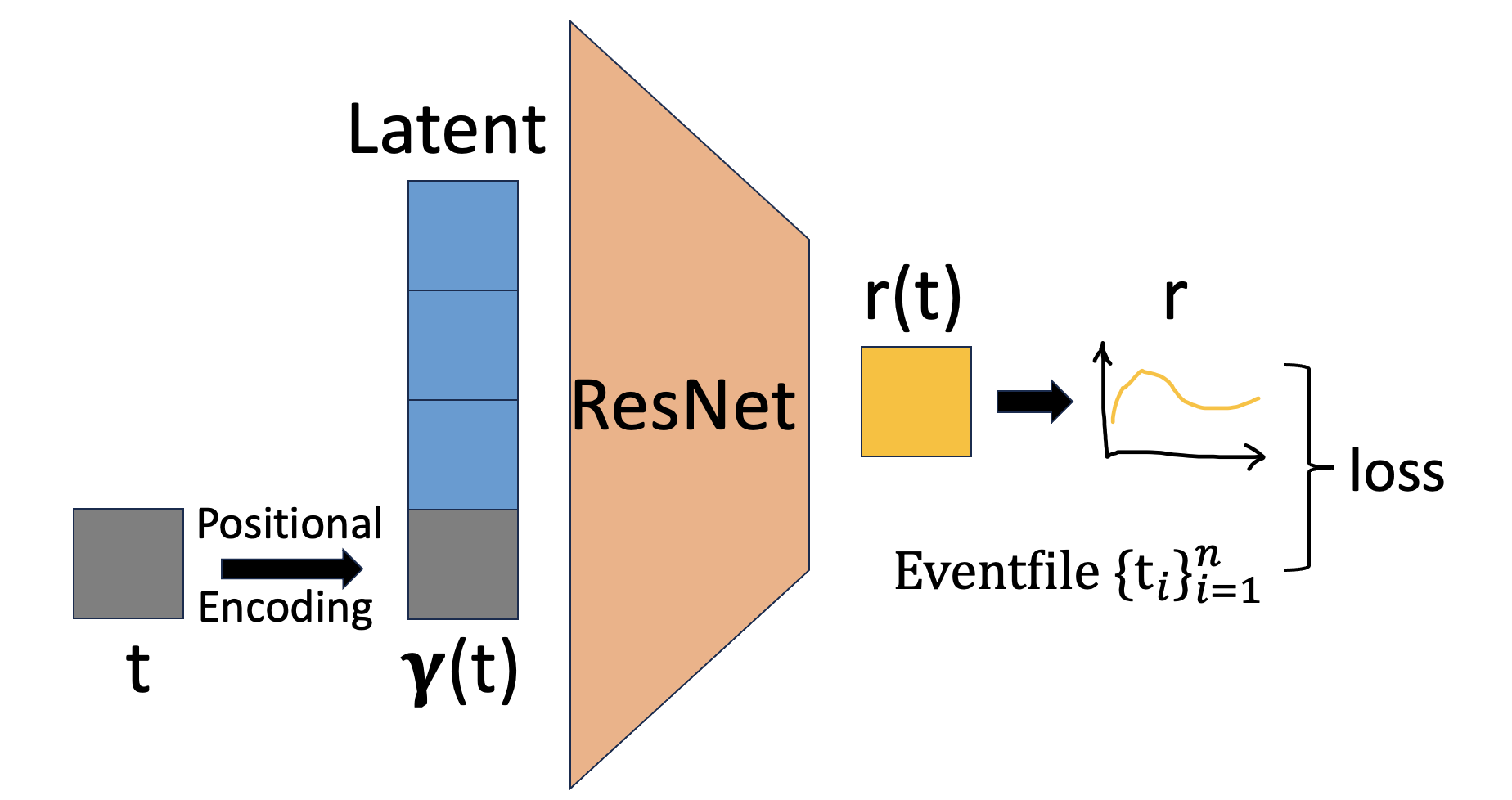
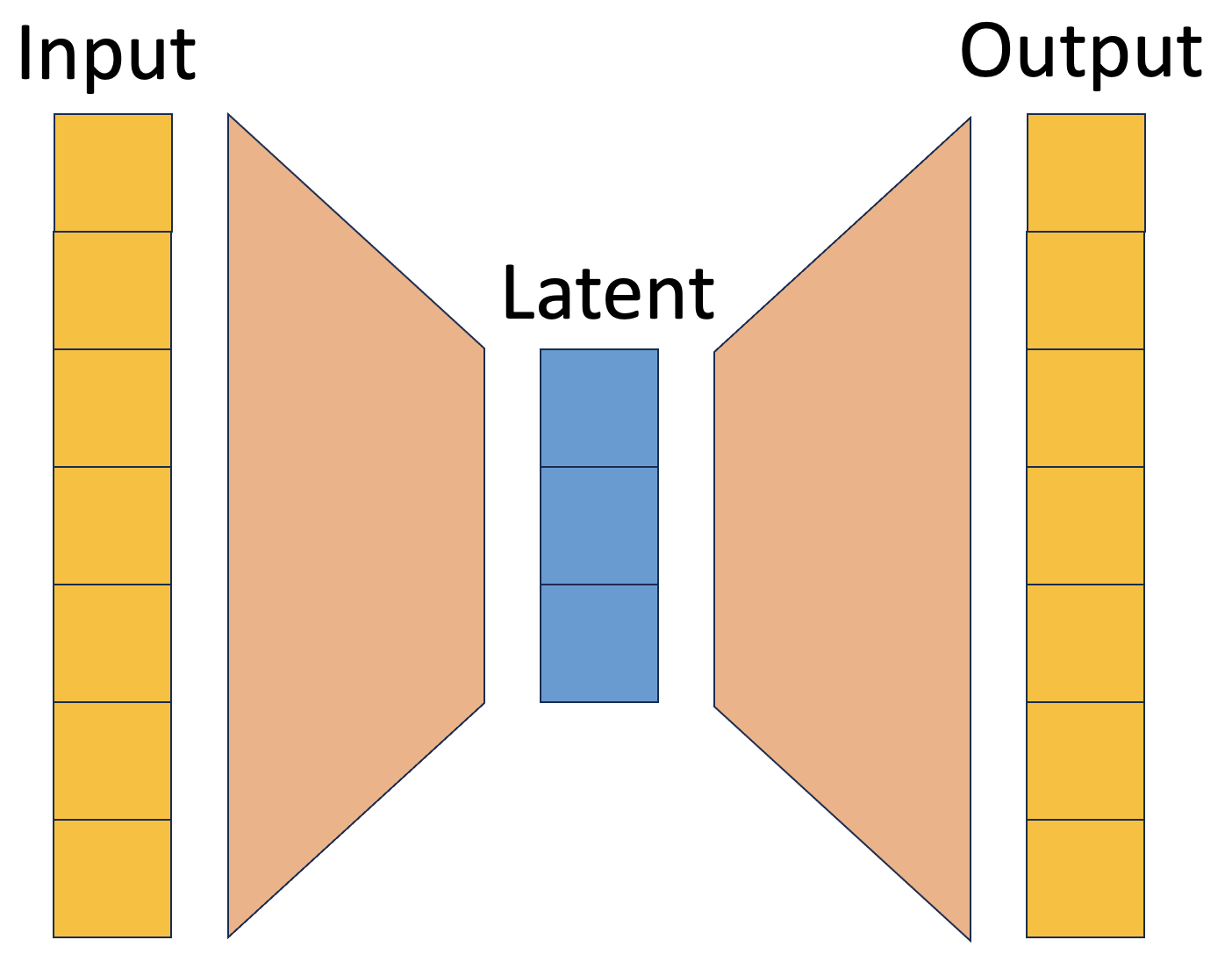
The learning architecture uses an autodecoder, a twist on the familiar autoencoder worth understanding. In a standard autoencoder, an encoder compresses input data into a latent vector (a compact list of numbers that acts as a fingerprint for the input), and a decoder reconstructs the data from that fingerprint. PPAD drops the encoder entirely. Each X-ray source gets its own learnable latent vector that starts random and gets refined during training.
A single shared decoder network takes these latent vectors and tries to reproduce the original photon arrival patterns, optimizing both its own weights and all the latent vectors at once. When training converges, each latent vector has become a compact, meaningful description of its source, learned without any labels.
The loss function is what makes this physically principled. Rather than mean squared error (which assumes Gaussian noise), PPAD uses a Poisson log-likelihood, the statistically correct way to score predictions for count data. A total variation penalty encourages the reconstructed rate functions to be smooth rather than artificially spiky.
Results on the Chandra Source Catalog hold up across multiple tasks:
- Reconstruction: PPAD accurately recovers light curves and spectral shapes even for faint sources with very few photons, outperforming binning-based approaches.
- Regression: Learned latent representations correlate strongly with physical properties like X-ray luminosity and spectral hardness, properties that normally require specialized analysis.
- Classification: When tested on sources with known types, the latent vectors cluster meaningfully, allowing simple classifiers to distinguish source classes with competitive accuracy.
- Anomaly detection: Unusual sources whose photon arrival patterns don’t fit the general population register as outliers in latent space, enabling automated flagging.
Why It Matters
The payoff here is twofold. For astronomers, PPAD is a practical tool that scales: feed millions of raw event files in, get a structured, searchable catalog of source representations out, ready for any downstream science task. No labels required. No manual feature engineering. No bin-size choices that might wash out real physical signals.
The framework is especially useful for rare or surprising objects, the serendipitous discoveries that large surveys occasionally turn up. Anomaly detection in latent space can flag them automatically, without anyone having to know what to look for in advance.
For the machine learning side, PPAD shows how matching your statistical model to the data-generating process can dramatically improve learned representations. The Poisson likelihood isn’t a physics-specific trick; it’s the right tool whenever your data consists of event counts, whether that’s click-stream analysis, neuroscience spike trains, or particle physics detections. The autodecoder architecture also offers a useful alternative to encoder-based approaches when the input data lacks fixed structure.
Open questions remain. The current work focuses on the Chandra Source Catalog; extending PPAD to the larger eROSITA dataset, or to multi-telescope joint observations, is an obvious next step. Adding multi-wavelength data (optical, radio, infrared) could yield richer representations still. And as the next generation of X-ray facilities comes online, the need for exactly this kind of scalable, principled automated analysis will only grow.
Bottom Line: PPAD turns the statistical challenge of sparse X-ray photon data into a feature rather than a bug, learning physically meaningful source representations directly from raw event files — no labels, no binning, no approximations of the underlying physics.
IAIFI Research Highlights
This work connects neural field methods from computer vision with Poisson statistics from physics, producing a tool that respects the quantum nature of light detection while deploying modern representation learning techniques.
PPAD shows that replacing generic loss functions with domain-appropriate likelihoods substantially improves learned representations, an approach applicable to any count-data domain well beyond astrophysics.
By enabling scalable, label-free analysis of millions of X-ray sources, PPAD accelerates discovery at major observatories and lowers the barrier to identifying new classes of high-energy astrophysical phenomena.
Future extensions to multi-telescope and multi-wavelength datasets could make PPAD a standard tool for next-generation X-ray astronomy; the paper is available at [arXiv:2502.01627](https://arxiv.org/abs/2502.01627).