
A reconfigurable neural network ASIC for detector front-end data compression at the HL-LHC
Authors
Giuseppe Di Guglielmo, Farah Fahim, Christian Herwig, Manuel Blanco Valentin, Javier Duarte, Cristian Gingu, Philip Harris, James Hirschauer, Martin Kwok, Vladimir Loncar, Yingyi Luo, Llovizna Miranda, Jennifer Ngadiuba, Daniel Noonan, Seda Ogrenci-Memik, Maurizio Pierini, Sioni Summers, Nhan Tran
Abstract
Despite advances in the programmable logic capabilities of modern trigger systems, a significant bottleneck remains in the amount of data to be transported from the detector to off-detector logic where trigger decisions are made. We demonstrate that a neural network autoencoder model can be implemented in a radiation tolerant ASIC to perform lossy data compression alleviating the data transmission problem while preserving critical information of the detector energy profile. For our application, we consider the high-granularity calorimeter from the CMS experiment at the CERN Large Hadron Collider. The advantage of the machine learning approach is in the flexibility and configurability of the algorithm. By changing the neural network weights, a unique data compression algorithm can be deployed for each sensor in different detector regions, and changing detector or collider conditions. To meet area, performance, and power constraints, we perform a quantization-aware training to create an optimized neural network hardware implementation. The design is achieved through the use of high-level synthesis tools and the hls4ml framework, and was processed through synthesis and physical layout flows based on a LP CMOS 65 nm technology node. The flow anticipates 200 Mrad of ionizing radiation to select gates, and reports a total area of 3.6 mm^2 and consumes 95 mW of power. The simulated energy consumption per inference is 2.4 nJ. This is the first radiation tolerant on-detector ASIC implementation of a neural network that has been designed for particle physics applications.
Concepts
The Big Picture
Imagine a camera with six million pixels firing 40 million times per second. Every second, it generates more raw data than any cable on Earth can carry. That’s the situation facing the CMS experiment at CERN’s Large Hadron Collider, where a new energy-measuring detector called the High-Granularity Calorimeter (HGCAL) is being built for an upgrade that will push the LHC to its highest-ever proton collision rates. The physics opportunities are real, but the data problem threatens to choke them off before a single interesting event can be recorded.
For decades, physicists handled this with simple filters at the detector edge: discarding readings below a minimum signal threshold, dropping quiet channels, keeping only the loudest hits. These brute-force approaches throw away data indiscriminately. What if, instead, you could deploy a tiny artificial brain directly on the detector, one smart enough to compress data intelligently, preserve the physics that matters, and survive years of punishing radiation? A team of researchers from Fermilab, MIT, CERN, and a dozen other institutions just showed how to do it.
Their result: the first radiation-tolerant, on-detector application-specific integrated circuit (ASIC), a custom-designed silicon chip running a neural network purpose-built for particle physics. Smaller than a fingernail, it runs a machine learning algorithm at the heart of one of the world’s most complex scientific instruments.
Key Insight: By embedding a reconfigurable neural network autoencoder directly into detector hardware, the team achieves intelligent, physics-preserving data compression at the source, cutting the data transmission bottleneck before it even begins.
How It Works
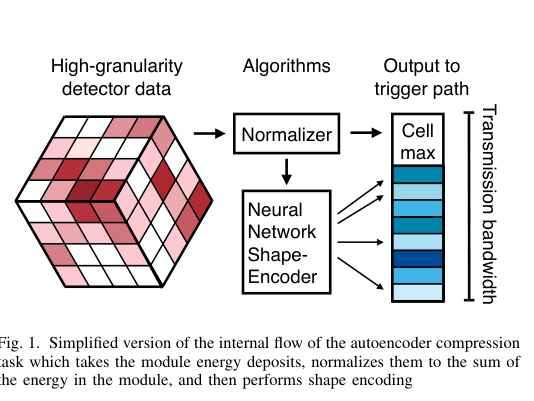
The core algorithm is an autoencoder, a neural network that learns to squeeze data through a narrow bottleneck and reconstruct it on the other side. Think of it like describing a painting over the phone: you can’t transmit every brushstroke, so you learn to capture the essence. The autoencoder encodes the HGCAL’s calorimeter energy deposits into a compact representation for transmission off-detector, where downstream systems can decode it or analyze the compressed form directly.
What makes this design clever isn’t just that it compresses data. It does so reconfigurably. The neural network architecture is fixed in silicon, but the weights, the learned parameters that define what the network actually does, are stored in programmable memory. Swap the weights, and you swap the compression algorithm.
Different regions of the HGCAL use different sensor shapes and see different patterns of particle cascades, so each chip can be individually tuned after manufacturing. Beam conditions change? Update the weights. Detector aging shifts the calibration? Update the weights. No new chip required.
Getting a neural network onto a chip this small and power-constrained demanded aggressive optimization:
- Quantization-aware training: Instead of standard 32-bit floating point, the network was trained assuming low-precision integer arithmetic from the start, shrinking the silicon footprint without wrecking accuracy.
- High-level synthesis (HLS): The team used the hls4ml framework to translate a trained neural network directly into hardware description language, automating chip design work that would otherwise take years of manual effort.
- Radiation-hardened gate selection: The chip was fabricated using a 65-nanometer process, with every logic gate chosen from a library validated to survive 200 million rads of ionizing radiation, the brutal dose detector electronics will absorb over the HL-LHC’s lifetime.
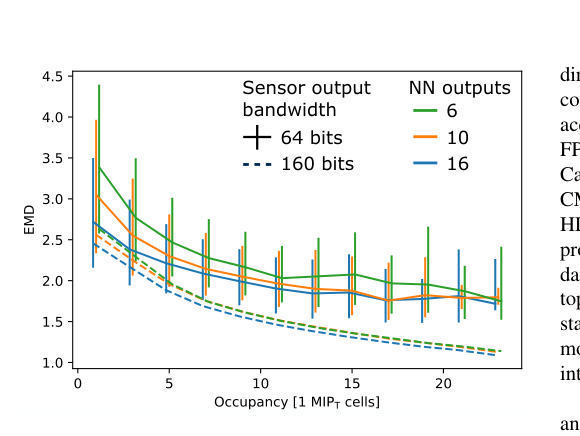
The resulting chip is compact: 3.6 mm² total area, 95 mW of power consumption, and just 2.4 nanojoules per inference. One complete compression of an HGCAL trigger data packet uses roughly the same energy as lifting a grain of sand by a millimeter. The chip has to do this 40 million times per second.
Why It Matters
The HL-LHC will collide protons at unprecedented rates, and the HGCAL’s fine-grained imaging will be critical for distinguishing rare collision events from the overwhelming flood of ordinary ones. That’s how you get precision measurements of the Higgs boson and other key physics targets. But none of it works if the data can’t leave the detector. Intelligent on-detector compression isn’t a convenience; it’s what makes the physics program viable.
On the AI side, the work shows that modern machine learning tools are mature enough to go from algorithm to radiation-hardened silicon for the harshest operating environments imaginable. The hls4ml workflow and quantization-aware training used here amount to a template for deploying neural networks at the extreme edge: in satellites, medical implants, anywhere that power, size, and radiation tolerance are non-negotiable.
The reconfigurability angle deserves attention too. A single chip design, mass-produced once, can serve dozens of different detector regions simply by loading different weights. Hardware designers in other fields should be paying attention.
Bottom Line: This team built and validated the first radiation-tolerant on-detector neural network ASIC for particle physics, showing that machine learning can survive and operate at the literal frontier of experimental science.
IAIFI Research Highlights
This work connects modern deep learning (autoencoder architectures, quantization-aware training) with the hardware constraints of experimental particle physics, producing a chip that satisfies both physics performance requirements and the extreme engineering limits of detector front-end electronics.
The paper advances edge AI by showing an end-to-end automated path from trained neural network to radiation-hardened ASIC hardware via hls4ml, giving other teams a reusable workflow for deploying ML models in power- and area-constrained environments.
The reconfigurable on-detector neural network enables the CMS HGCAL to intelligently compress its 40 MHz trigger data stream, preserving the calorimetric energy profiles needed for real-time event selection at the HL-LHC without overwhelming off-detector bandwidth.
Future directions include deploying this design in actual CMS hardware and extending the approach to other detector subsystems; the full paper is available at [arXiv:2105.01683](https://arxiv.org/abs/2105.01683).
Original Paper Details
A reconfigurable neural network ASIC for detector front-end data compression at the HL-LHC
2105.01683
["Giuseppe Di Guglielmo", "Farah Fahim", "Christian Herwig", "Manuel Blanco Valentin", "Javier Duarte", "Cristian Gingu", "Philip Harris", "James Hirschauer", "Martin Kwok", "Vladimir Loncar", "Yingyi Luo", "Llovizna Miranda", "Jennifer Ngadiuba", "Daniel Noonan", "Seda Ogrenci-Memik", "Maurizio Pierini", "Sioni Summers", "Nhan Tran"]
Despite advances in the programmable logic capabilities of modern trigger systems, a significant bottleneck remains in the amount of data to be transported from the detector to off-detector logic where trigger decisions are made. We demonstrate that a neural network autoencoder model can be implemented in a radiation tolerant ASIC to perform lossy data compression alleviating the data transmission problem while preserving critical information of the detector energy profile. For our application, we consider the high-granularity calorimeter from the CMS experiment at the CERN Large Hadron Collider. The advantage of the machine learning approach is in the flexibility and configurability of the algorithm. By changing the neural network weights, a unique data compression algorithm can be deployed for each sensor in different detector regions, and changing detector or collider conditions. To meet area, performance, and power constraints, we perform a quantization-aware training to create an optimized neural network hardware implementation. The design is achieved through the use of high-level synthesis tools and the hls4ml framework, and was processed through synthesis and physical layout flows based on a LP CMOS 65 nm technology node. The flow anticipates 200 Mrad of ionizing radiation to select gates, and reports a total area of 3.6 mm^2 and consumes 95 mW of power. The simulated energy consumption per inference is 2.4 nJ. This is the first radiation tolerant on-detector ASIC implementation of a neural network that has been designed for particle physics applications.