
A Resource Model For Neural Scaling Law
Authors
Jinyeop Song, Ziming Liu, Max Tegmark, Jeff Gore
Abstract
Neural scaling laws characterize how model performance improves as the model size scales up. Inspired by empirical observations, we introduce a resource model of neural scaling. A task is usually composite hence can be decomposed into many subtasks, which compete for resources (measured by the number of neurons allocated to subtasks). On toy problems, we empirically find that: (1) The loss of a subtask is inversely proportional to its allocated neurons. (2) When multiple subtasks are present in a composite task, the resources acquired by each subtask uniformly grow as models get larger, keeping the ratios of acquired resources constants. We hypothesize these findings to be generally true and build a model to predict neural scaling laws for general composite tasks, which successfully replicates the neural scaling law of Chinchilla models reported in arXiv:2203.15556. We believe that the notion of resource used in this paper will be a useful tool for characterizing and diagnosing neural networks.
Concepts
The Big Picture
Imagine you’re running a small restaurant kitchen. You have a limited number of cooks, and every dish on the menu needs someone to prepare it. The kitchen has to decide how to divide labor.
Add more cooks, and every dish gets a little better. As you keep hiring, each station grows proportionally. The salad station never hogs all the new talent; the pasta cooks get their fair share too.
This is a surprisingly accurate metaphor for how neural networks scale. For years, researchers have noticed a consistent pattern: as you make AI models bigger, their performance improves in a smooth, predictable way, following a neural scaling law. Double the parameters, and the model’s error drops by a reliable amount.
But why? What’s actually happening inside the network as it grows? Various explanations have been proposed over the years, and none of them have quite stuck.
Researchers at MIT and IAIFI have now proposed an answer rooted in a simple physical intuition: neurons are resources, and the tasks a network must learn are consumers competing for them.
Key Insight: When a neural network grows larger, every subtask it has learned receives a proportional share of new neurons. Because each individual subtask improves as 1/N with more neurons, the whole model’s performance improves predictably as a power law.
How It Works
The team built their framework from the ground up, starting with the simplest possible case: a single task.
They trained a one-hidden-layer network to regress the function y = x², adding sparsity regularization, a penalty that pressures the network to use as few neurons as possible. A hyperparameter α controls the tradeoff: set it low, and the network manages with a handful of neurons; crank it up, and it drafts more of the hidden layer into service.
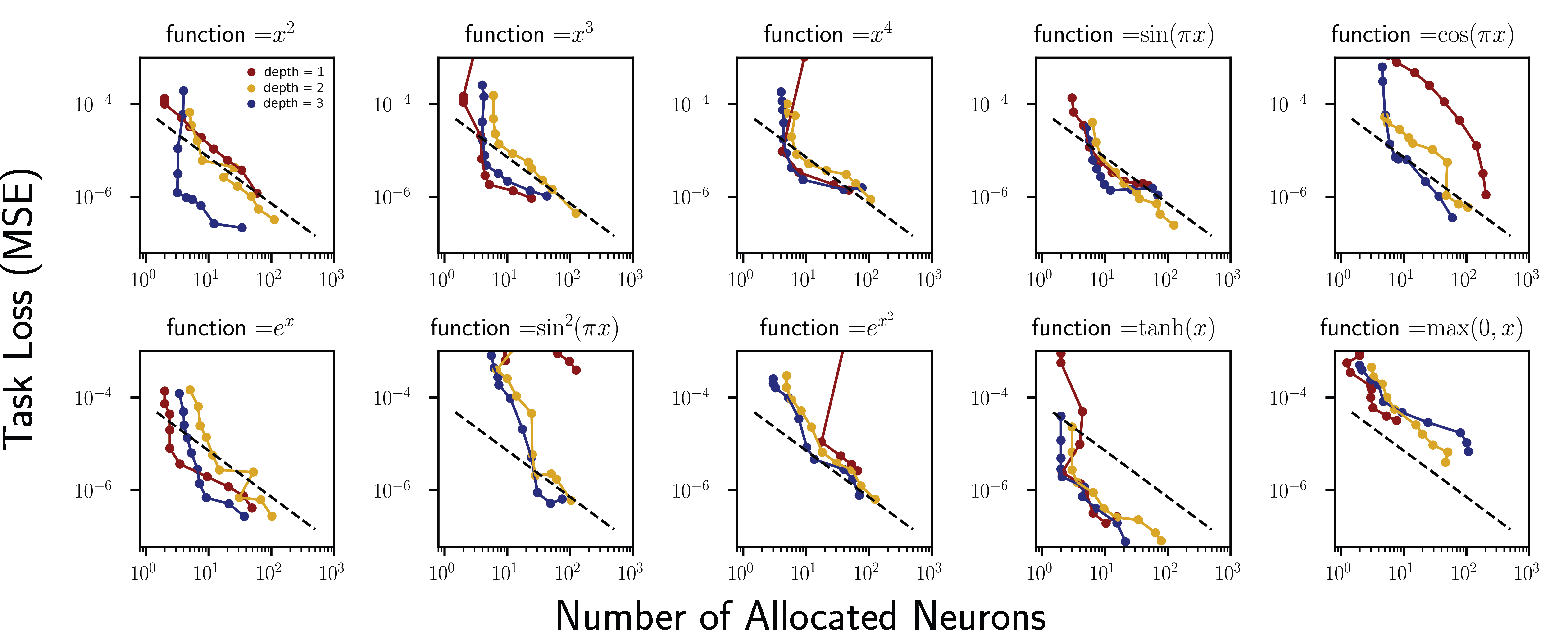
The result was clean. Count the allocated neurons (those with nonzero weights above a threshold of 10⁻³), plot them against task loss, and you get a power law with exponent −1. Double the neurons devoted to the task and the loss halves. This is Resource Model Hypothesis 1: for a single subtask, loss scales as ℓ ∼ N⁻¹.
A single task isn’t how real models work, though. Language modeling involves thousands of simultaneous competencies. So the researchers asked: what happens when multiple subtasks compete for the same neuron pool?
They constructed composite tasks in two configurations:
- Parallel: subtasks run simultaneously (do A and B at the same time)
- Series: subtasks chain together (do A, then feed the result into B)
Then they tracked how neuron allocation shifted as the network grew.
The answer was the homogeneous growth hypothesis: network growth is uniform across subtasks. As total size increases, every subtask acquires more neurons, and the ratios stay constant. The salad station and the pasta station both grow at the same rate. No subtask monopolizes new capacity. If Task A had twice the neurons of Task B in a small model, it still has twice the neurons in a model ten times larger.
Combining both findings yields a clean prediction. Each subtask’s loss scales as N⁻¹ and all subtasks grow proportionally, so the total composite loss also scales as N_total⁻¹.
Why It Matters
The real test of any theory is whether it predicts something real. The researchers made an ambitious leap: they used the resource model to derive the scaling law for large language models and compared it to Chinchilla (arXiv:2203.15556), the landmark 2022 study that showed loss scales with parameters as ℓ ∝ N_p⁻⁰·³⁴.
The derivation goes through a chain of physical assumptions. A neural network with N neurons per layer and L layers has roughly N_p ∝ N² × L total parameters. Under optimal compute scaling, L ∝ N, giving N_p ∝ N³. Substitute into ℓ ∝ N⁻¹ and you get ℓ ∝ N_p⁻¹/³ ≈ N_p⁻⁰·³³.
That’s not a fit. That’s a derivation, from first principles, matching Chinchilla’s observed exponent of 0.34 within rounding.
Beyond scaling laws, the resource framework opens a new diagnostic lens. If you can measure how neurons are allocated across subtasks, you can ask whether a model is efficiently distributing capacity or whether certain skills are being starved while others hoard neurons. This connects to the growing field of mechanistic interpretability, where researchers map the circuits inside neural networks. The resource model gives that effort a quantitative backbone.
Open questions remain. The homogeneous growth hypothesis was validated on toy problems; does it hold in full-scale transformers? Are there tasks where growth is not homogeneous, say when subtasks conflict? Can the resource framework predict which subtasks get prioritized when data is limited?
Bottom Line: By treating neurons as finite resources that subtasks compete for, MIT and IAIFI researchers derived the famous Chinchilla scaling law from first principles, while providing a mechanistic picture of how AI models grow.
IAIFI Research Highlights
This work imports concepts from resource competition in biology and economics into deep learning theory, showing that physical intuitions about resource allocation can explain one of AI's most persistent empirical puzzles.
The resource model provides the first principled, mechanistic derivation of compute-optimal scaling laws and offers a way to diagnose how neural networks distribute capacity across learned skills.
The framework connects mechanistic interpretability to quantitative predictions, tying abstract scaling observations to the concrete structure of neurons and modules inside trained networks.
Future work could extend the homogeneous growth hypothesis to large transformers and test whether resource ratios can diagnose capability gaps. The paper builds on the Chinchilla results of Hoffmann et al. ([arXiv:2203.15556](https://arxiv.org/abs/2203.15556)).
Original Paper Details
A Resource Model For Neural Scaling Law
[2402.05164](https://arxiv.org/abs/2402.05164)
Jinyeop Song, Ziming Liu, Max Tegmark, Jeff Gore