
A Solvable Model of Neural Scaling Laws
Authors
Alexander Maloney, Daniel A. Roberts, James Sully
Abstract
Large language models with a huge number of parameters, when trained on near internet-sized number of tokens, have been empirically shown to obey neural scaling laws: specifically, their performance behaves predictably as a power law in either parameters or dataset size until bottlenecked by the other resource. To understand this better, we first identify the necessary properties allowing such scaling laws to arise and then propose a statistical model -- a joint generative data model and random feature model -- that captures this neural scaling phenomenology. By solving this model in the dual limit of large training set size and large number of parameters, we gain insight into (i) the statistical structure of datasets and tasks that lead to scaling laws, (ii) the way nonlinear feature maps, such as those provided by neural networks, enable scaling laws when trained on these datasets, (iii) the optimality of the equiparameterization scaling of training sets and parameters, and (iv) whether such scaling laws can break down and how they behave when they do. Key findings are the manner in which the power laws that occur in the statistics of natural datasets are extended by nonlinear random feature maps and then translated into power-law scalings of the test loss and how the finite extent of the data's spectral power law causes the model's performance to plateau.
Concepts
The Big Picture
Imagine you’re baking bread and notice something strange: every time you double the flour, the loaf gets exactly 30% better. Every time. Double again, another 30%.
This clockwork predictability is exactly what AI researchers discovered about large language models. Whether you scale up the number of learned, adjustable settings inside a model (called parameters), the amount of training data, or the computing power used to train it, performance improves in a precise mathematical rhythm called a power law. These are neural scaling laws, and they’ve reshaped how the entire AI industry plans its future.
But nobody could explain why. Why should a language model trained on internet text follow the same mathematical pattern as earthquake intensities or city size distributions? It felt almost too tidy, a suspicious regularity without a theoretical explanation.
A team of physicists and AI researchers has now built that explanation. In a paper from MIT and McGill, Alexander Maloney, Daniel Roberts, and James Sully construct a solvable theoretical model that reproduces neural scaling laws from first principles. Think of it as the physics of learning: the same way physicists derived the gas laws from microscopic atomic collisions, this team derives scaling laws from the statistical structure of data and models.
Key Insight: Neural scaling laws aren’t magic. They emerge from a specific mathematical structure in natural datasets (power-law spectral statistics) that gets amplified and preserved by nonlinear neural networks. When that structure runs out, the scaling stops.
How It Works
The framework has two interlocking pieces: a generative data model describing the statistical patterns baked into training data, and a random feature model standing in for how a neural network layer transforms raw inputs into useful internal representations.
The first piece is about data. Real-world datasets, whether text, images, or physical measurements, aren’t random noise. Their statistical structure, decomposed into its most important underlying patterns (think of sorting music by frequency, from bass to treble), follows a power law. The most important patterns are far more common than the second-most-important, which are more common than the third, in a precise mathematical ratio. This is the hidden skeleton of natural data.
The second piece is what neural networks actually do with that structure. When a network applies its nonlinear transformations, it doesn’t passively relay the data’s structure. It extends the spectral power law. The feature map, the transformation converting raw inputs into a space where patterns are easier to separate, pushes the power law to cover more of the representation space as you add parameters. A telescope that not only magnifies what’s already visible but reveals new stars past the edge of the original image.
Here’s the mechanism, step by step:
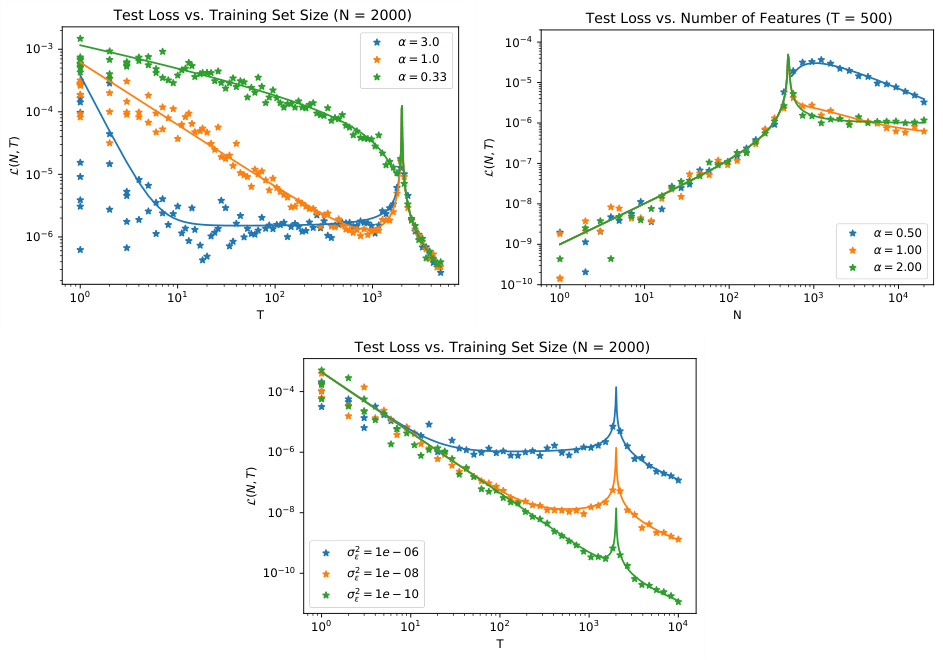
- Data has a spectral power law: The eigenvalues of the data’s covariance matrix decay as a power law, $\lambda_k \sim k^{-\alpha}$ for some exponent $\alpha$.
- Feature maps extend this: Passing data through a nonlinear feature map pushes the power law further into feature space, covering more “modes.”
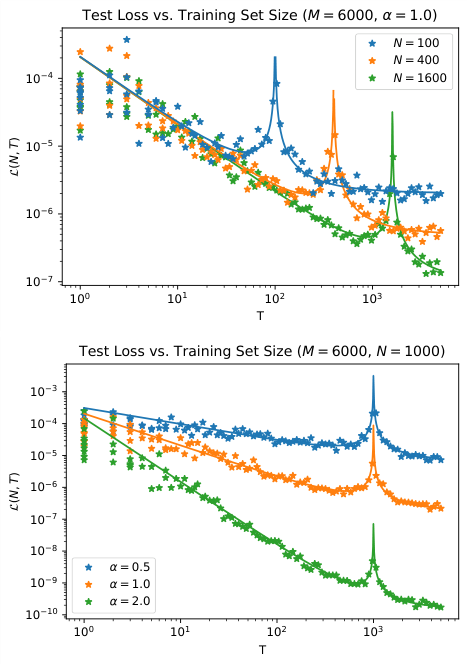
- Test loss inherits the structure: In the large-$N$, large-$P$ regime, the test loss becomes a power-law function of both dataset size $N$ and parameter count $P$.
- Equiparameterization is optimal: The sweet spot is scaling $N \propto P$, keeping data volume and model size in lockstep. This equiparameterization is theoretically optimal, consistent with empirical recipes like Chinchilla scaling.
The team solves their model analytically in the “dual limit” where both $N$ and $P$ grow large together, allowing exact solutions to emerge. This requires resolvent methods from random matrix theory, a branch of mathematical physics for analyzing the statistical behavior of large matrices. The result is an exact expression for test loss as a function of both resources simultaneously.
Why It Matters
The most practically significant result is the prediction of when scaling laws break down. The data’s spectral power law has finite extent; there are only so many meaningful modes in any dataset. Model performance eventually plateaus, and more parameters and more data won’t help once you’ve exhausted the useful statistical structure. This gives researchers a principled way to ask: have we extracted everything we can from this data distribution, or is there still room to scale?
The work also reframes a longstanding puzzle about why transformers obey scaling laws so robustly. The answer, this framework suggests, lies in the quality of spectral extension a given architecture provides, how effectively it amplifies and continues the underlying power-law structure into its internal representations. Architectures that better extend the data’s power law will exhibit cleaner, more persistent scaling. That’s a testable hypothesis, and it points toward a concrete design criterion: optimize not just for accuracy, but for spectral extension.
There’s a broader point here too. A relatively simple statistical model, with no attention mechanisms, no tokenizers, and no fine-tuning, can reproduce the same broad scaling patterns seen in GPT-class models. Scaling laws look like deep structural features of the learning problem itself, not accidents of architecture or training procedure.
Bottom Line: By treating neural networks the way physicists treat thermodynamic systems, building simple models that capture the essential statistics, Maloney, Roberts, and Sully have given the AI community its first rigorous theoretical lens for understanding why scaling works, when it stops, and how to push it further.
IAIFI Research Highlights
This work imports methods from theoretical physics (random matrix theory and statistical mechanics) to derive the empirical scaling laws governing modern AI, a direct example of the IAIFI mission to connect physics and AI research.
The paper provides the first analytically solvable model reproducing neural scaling laws as a function of both dataset size and parameter count, giving a theoretical foundation for practical decisions about compute, data, and model capacity.
Power-law statistics are ubiquitous in physical systems, and this framework shows they also organize machine learning behavior, tightening the mathematical connections between statistical physics and learning theory.
Future work can test whether architectures like transformers achieve superior spectral extension, and whether these results extend beyond regression to classification and generative tasks. The paper is available at [arXiv:2210.16859](https://arxiv.org/abs/2210.16859).
Original Paper Details
A Solvable Model of Neural Scaling Laws
[2210.16859](https://arxiv.org/abs/2210.16859)
Alexander Maloney, Daniel A. Roberts, James Sully
Large language models with a huge number of parameters, when trained on near internet-sized number of tokens, have been empirically shown to obey neural scaling laws: specifically, their performance behaves predictably as a power law in either parameters or dataset size until bottlenecked by the other resource. To understand this better, we first identify the necessary properties allowing such scaling laws to arise and then propose a statistical model -- a joint generative data model and random feature model -- that captures this neural scaling phenomenology. By solving this model in the dual limit of large training set size and large number of parameters, we gain insight into (i) the statistical structure of datasets and tasks that lead to scaling laws, (ii) the way nonlinear feature maps, such as those provided by neural networks, enable scaling laws when trained on these datasets, (iii) the optimality of the equiparameterization scaling of training sets and parameters, and (iv) whether such scaling laws can break down and how they behave when they do. Key findings are the manner in which the power laws that occur in the statistics of natural datasets are extended by nonlinear random feature maps and then translated into power-law scalings of the test loss and how the finite extent of the data's spectral power law causes the model's performance to plateau.