
A Tale of Two Symmetries: Exploring the Loss Landscape of Equivariant Models
Authors
YuQing Xie, Tess Smidt
Abstract
Equivariant neural networks have proven to be effective for tasks with known underlying symmetries. However, optimizing equivariant networks can be tricky and best training practices are less established than for standard networks. In particular, recent works have found small training benefits from relaxing equivariance constraints. This raises the question: do equivariance constraints introduce fundamental obstacles to optimization? Or do they simply require different hyperparameter tuning? In this work, we investigate this question through a theoretical analysis of the loss landscape geometry. We focus on networks built using permutation representations, which we can view as a subset of unconstrained MLPs. Importantly, we show that the parameter symmetries of the unconstrained model has nontrivial effects on the loss landscape of the equivariant subspace and under certain conditions can provably prevent learning of the global minima. Further, we empirically demonstrate in such cases, relaxing to an unconstrained MLP can sometimes solve the issue. Interestingly, the weights eventually found via relaxation corresponds to a different choice of group representation in the hidden layer. From this, we draw 3 key takeaways. (1) By viewing the unconstrained version of an architecture, we can uncover hidden parameter symmetries which were broken by choice of constraint enforcement (2) Hidden symmetries give important insights on loss landscapes and can induce critical points and even minima (3) Hidden symmetry induced minima can sometimes be escaped by constraint relaxation and we observe the network jumps to a different choice of constraint enforcement. Effective equivariance relaxation may require rethinking the fixed choice of group representation in the hidden layers.
Concepts
The Big Picture
Imagine you’re trying to find the lowest point in a mountain range, but someone has handed you a map with certain valleys deliberately hidden. You might wander for ages, convinced you’ve found the bottom of a ravine, while the true lowest valley lies just out of sight. That’s the situation facing researchers who train equivariant neural networks, AI models built to respect the symmetries of the physical world.
Equivariant networks have become workhorses of computational science, powering molecular force fields, protein structure prediction, particle physics simulations, and catalyst discovery. Their advantage: by baking known symmetries directly into the architecture, they generalize better and need far less training data. If a molecule looks the same when you rotate it, the network’s predictions should too, and equivariant models guarantee this by construction.
But practitioners have long noticed something puzzling: these models are finicky to train. Tuning settings that work for standard networks often fail. Worse, some studies found that loosening the symmetry rules (letting the network cheat on symmetry a little) actually improves performance.
That raised a sharp question: are equivariance constraints themselves creating hidden traps in the loss landscape? MIT researchers YuQing Xie and Tess Smidt set out to answer it, and what they found reframes the whole debate.
Key Insight: Enforcing equivariance requires making choices that break hidden symmetries of the underlying unconstrained model, and these broken symmetries can provably create spurious local minima that trap gradient descent.
How It Works
At the core of this paper is a theoretical analysis of loss landscape geometry, the shape of the error surface that gradient descent navigates during training. Gradient descent nudges a network’s weights toward better performance by following the steepest downhill path. To make the analysis tractable, Xie and Smidt focus on networks built with permutation representations (p-reps): a mathematical framework where internal signals transform in a structured, predictable way under symmetry operations. This class includes:
- Group convolutions
- Deep Sets
- Networks operating on spherical signals
P-rep networks can be viewed as a constrained subspace of ordinary unconstrained MLPs, making it possible to study both worlds side by side.
Central to the argument is parameter symmetry: transformations of a model’s weights that leave its function unchanged. Standard MLPs have many of these. You can permute or rescale neurons without changing what the network computes.
When you impose equivariance constraints, you carve out a lower-dimensional region of weight space. But that carving operation doesn’t eliminate the unconstrained model’s parameter symmetries. It hides them.
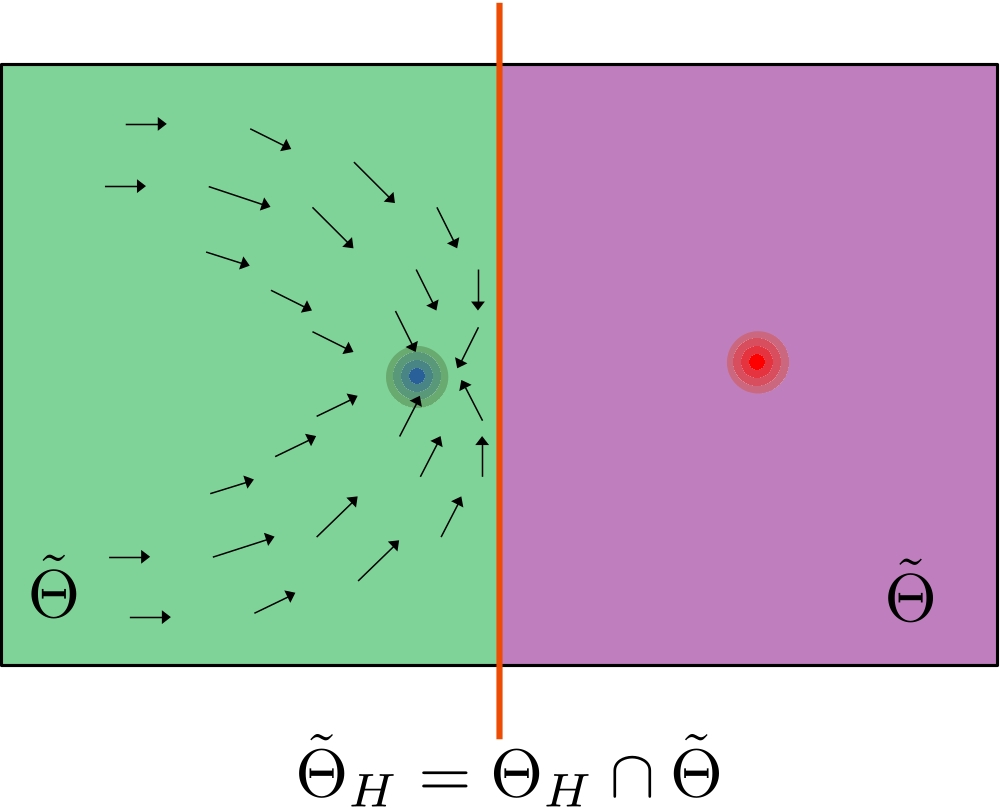
The hidden symmetries have a concrete, damaging effect. The paper proves that under certain conditions, these symmetries create critical points (places where the gradient vanishes) and even spurious minima (local minima that aren’t the global solution) within the equivariant subspace. The constrained model gets stuck not because gradient descent is bad, but because the constraint geometry has manufactured a false bottom. The global minimum exists in the unconstrained loss landscape; the equivariant subspace simply doesn’t contain it.
To test these predictions, the authors ran a teacher-student experiment: a “teacher” equivariant network generates data, and a “student” of the same architecture tries to learn it. Where the theory predicts spurious minima, the constrained student reliably gets stuck. When constraints are relaxed and the student trains as an unconstrained MLP, it escapes the trap and finds a better solution.
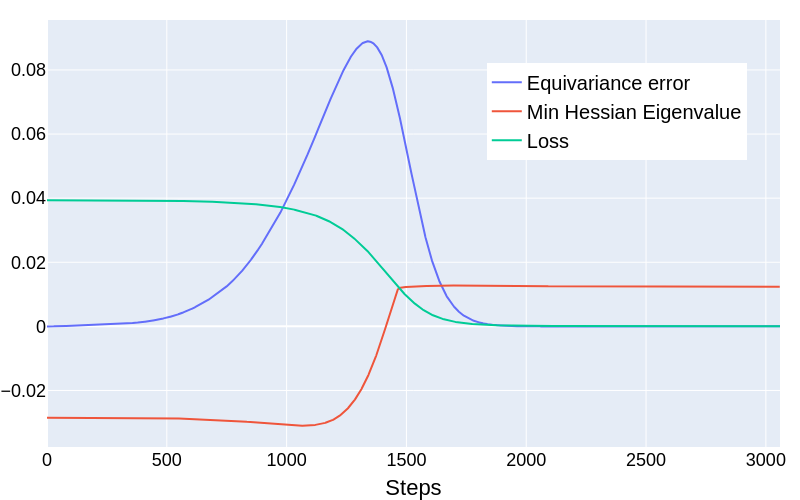
The most striking result is where the relaxed model ends up. Its weights don’t correspond to the original equivariant subspace. Instead, they correspond to a different choice of group representation in the hidden layers: a mathematically equivalent way to enforce the same equivariance with different internal wiring. Freed from the original constraint, the unconstrained model jumps to a symmetrically related subspace that the original formulation had made invisible.
The theoretical machinery involves analyzing fixed-point subspaces of the parameter symmetry group. These are regions of weight space locked in place by the combined symmetries of the constraint and the model. When these interact, certain regions become attractors that aren’t the right answer. The paper provides explicit characterizations of when these dangerous subspaces arise, giving practitioners a concrete checklist for diagnosing problematic architectures before training begins.
Why It Matters
This work shifts the framing of a longstanding debate in geometric deep learning, the field concerned with building neural networks that respect geometric structure like rotation or reflection symmetry. The question “should we relax equivariance?” has mostly been treated empirically: try it, measure the performance bump, shrug. Xie and Smidt show there’s a principled, geometry-driven answer.
Even when the ground truth is perfectly equivariant, the choice of how to enforce it can sabotage learning. That’s a fundamentally different diagnosis than “equivariance hurts.”
The implications reach across every domain that uses equivariant models. For molecular simulation and materials discovery, where equivariant networks are state of the art, training failures might sometimes be fixed not by adjusting learning rates or batch sizes, but by reconsidering which group representation the network uses in its hidden layers.
The paper also opens a new theoretical direction: using the unconstrained model as a lens to discover hidden symmetry structure that the constrained version obscures. That idea could apply well beyond equivariant networks to a much broader class of structured models.
Bottom Line: Equivariance constraints can provably manufacture spurious minima by hiding symmetries of the unconstrained model. Escaping them may require rethinking which group representation the network uses internally, not just relaxing constraints after the fact.
IAIFI Research Highlights
This work connects the mathematical theory of group representations (foundational to physics) with the practical optimization challenges of training neural networks for scientific applications like molecular simulation and particle physics.
By proving that constraint enforcement choices create spurious minima, this paper provides a rigorous theoretical explanation for why equivariant networks are harder to train than unconstrained MLPs, and offers concrete guidance for architecture design.
Equivariant networks are central tools for computing molecular force fields, protein structures, and particle physics observables; understanding and fixing their optimization failures directly improves the reliability of AI-driven physics discovery.
Future work should investigate whether hidden-symmetry traps arise in irrep-based equivariant networks and whether principled representation selection can replace ad hoc constraint relaxation; see the full theoretical treatment by Xie and Smidt at [arXiv:2506.02269](https://arxiv.org/abs/2506.02269).
Original Paper Details
A Tale of Two Symmetries: Exploring the Loss Landscape of Equivariant Models
2506.02269
["YuQing Xie", "Tess Smidt"]
Equivariant neural networks have proven to be effective for tasks with known underlying symmetries. However, optimizing equivariant networks can be tricky and best training practices are less established than for standard networks. In particular, recent works have found small training benefits from relaxing equivariance constraints. This raises the question: do equivariance constraints introduce fundamental obstacles to optimization? Or do they simply require different hyperparameter tuning? In this work, we investigate this question through a theoretical analysis of the loss landscape geometry. We focus on networks built using permutation representations, which we can view as a subset of unconstrained MLPs. Importantly, we show that the parameter symmetries of the unconstrained model has nontrivial effects on the loss landscape of the equivariant subspace and under certain conditions can provably prevent learning of the global minima. Further, we empirically demonstrate in such cases, relaxing to an unconstrained MLP can sometimes solve the issue. Interestingly, the weights eventually found via relaxation corresponds to a different choice of group representation in the hidden layer. From this, we draw 3 key takeaways. (1) By viewing the unconstrained version of an architecture, we can uncover hidden parameter symmetries which were broken by choice of constraint enforcement (2) Hidden symmetries give important insights on loss landscapes and can induce critical points and even minima (3) Hidden symmetry induced minima can sometimes be escaped by constraint relaxation and we observe the network jumps to a different choice of constraint enforcement. Effective equivariance relaxation may require rethinking the fixed choice of group representation in the hidden layers.