
A theoretical approach to density-split clustering
Authors
Mathilde Pinon, Arnaud de Mattia, Étienne Burtin, Vanina Ruhlmann-Kleider, Sandrine Codis, Enrique Paillas, Carolina Cuesta-Lazaro
Abstract
We present an analytical model for density-split correlation functions, that probe galaxy clustering in different density environments. Specifically, we focus on the cross-correlation between density-split regions and the tracer density field. We show that these correlation functions can be expressed in terms of the two-point probability density function (PDF) of the density field. We derive analytical predictions using three levels of approximation for the two-point PDF: a bivariate Gaussian distribution, a bivariate shifted log-normal distribution, and a prediction based on the Large Deviation Theory (LDT) framework. For count-in-cell densities, obtained through spherical top-hat smoothing, one can leverage spherical collapse dynamics and LDT to predict the density two-point PDF in the large-separation regime relative to the smoothing radius. We validate our model against dark matter N-body simulations in real space, incorporating Poisson shot noise and galaxy bias. Our results show that the LDT prediction outperforms the log-normal approximation, and agrees with simulations on large scales within the cosmic variance of a typical DESI DR1 sample, despite relying on only one degree of freedom.
Concepts
The Big Picture
Imagine trying to understand how cities are distributed across a continent by measuring only the average population density everywhere. You’d miss everything interesting: dense urban cores, sprawling suburbs, empty countryside. Now imagine measuring how cities cluster differently depending on whether they’re surrounded by other cities or isolated in rural areas. That’s what density-split clustering does for the cosmos.
The large-scale structure of the universe isn’t uniform. Galaxies congregate into walls, filaments, and massive clusters, leaving behind vast cosmic voids. Traditional galaxy surveys measure this structure by asking a simple statistical question: on average, how likely are two galaxies to be found near each other? This “two-point” approach is useful, but it throws away a staggering amount of information.
It can’t tell you whether those nearby galaxies sit in a dense hub or a modest clump. Those are very different physical situations, but they look identical in the average. As surveys like the Dark Energy Spectroscopic Instrument (DESI) map tens of millions of galaxies across cosmic history, astronomers need sharper tools to decode what the universe is telling them.
A team of researchers from France, Arizona, MIT, and Harvard has developed an analytical model for density-split clustering, a framework that predicts how galaxy clustering behaves in different density environments without requiring expensive computer simulations as a crutch.
Key Insight: By connecting density-split statistics to the probability distribution of the density field, the researchers derived predictive equations that agree with full computer simulations of cosmic structure on cosmologically relevant scales, using just a single free parameter.
How It Works
Density-split statistics divide a survey volume into regions based on local density, sorting patches of sky from emptiest to densest, then measure how the full galaxy distribution correlates with each region separately. A dense region’s clustering pattern looks different from a void’s. That difference encodes non-Gaussian information: statistical patterns beyond what a simple average can capture, like the difference between a symmetric bell curve and a lopsided distribution with a long tail.
The key mathematical insight is that density-split correlation functions can be expressed in terms of the two-point probability density function (PDF) of the underlying density field, a map of how likely any given combination of densities is to occur at two locations some distance apart. This is richer than a correlation coefficient, which collapses that relationship to a single number.
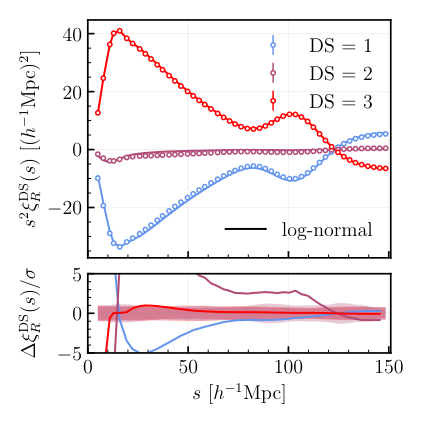
The team develops three progressively more sophisticated approximations for this two-point PDF:
- Bivariate Gaussian — The simplest assumption: density fluctuations follow a bell-curve distribution. This works at large scales where the universe hasn’t evolved much, but breaks down where gravitational collapse has made structure non-linear.
- Shifted log-normal — A better approximation that accounts for the fact that density is always greater than −1 (you can’t have negative matter). Modeling the logarithm of the density as Gaussian captures more of the universe’s true statistical character.
- Large Deviation Theory (LDT) — The most sophisticated approach, borrowed from statistical physics. LDT predicts the probability of rare, extreme events, exactly the physics governing the densest and emptiest regions of the universe. It only requires that the variance of density fluctuations be small, not the fluctuations themselves. This makes it valid even where perturbation theory (the standard tool for approximating small departures from a smooth, uniform universe) breaks down.
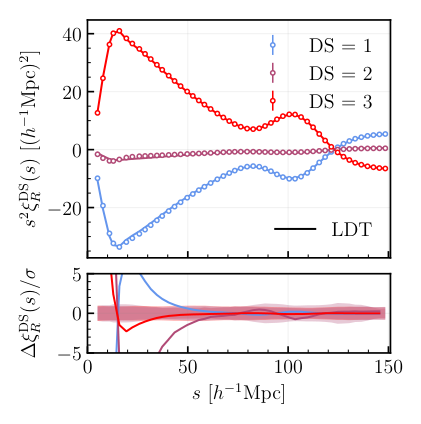
For LDT predictions to work, the team connects density-split statistics to the bias function, a quantity describing how the density at one location depends on the density at another, well-separated point. In the large-separation limit, LDT makes a sharp prediction for this bias function using spherical collapse dynamics, a classic framework for how overdense patches gravitationally contract into halos.
All three models were validated against the AbacusSummit suite of N-body simulations, large-scale computer simulations that track how gravity pulls billions of particles together over cosmic time. The comparison covered a range of density thresholds and accounted for Poisson shot noise and galaxy bias.
LDT consistently outperforms the log-normal approximation. On large scales it matches simulations within the cosmic variance of a typical DESI DR1 sample, the statistical noise floor set by having only one observable universe. It does this with a single free parameter.
Why It Matters
Previous density-split clustering analyses relied on simulation-based emulators. These are powerful tools, but they carry real costs: enormous simulation suites, implicit trust that simulations faithfully capture all relevant physics, and parameter-heavy frameworks that obscure physical interpretation. An analytical model is more transparent, faster to evaluate, and directly connected to the physics it describes.
This makes density-split clustering viable as a standard tool in the cosmological inference toolkit, sitting alongside power spectra and correlation functions for current surveys like DESI and future ones like Euclid and the Vera Rubin Observatory’s LSST. By extracting non-Gaussian information from the density field without simulation overhead, it could sharpen constraints on dark energy, neutrino mass, and the initial conditions set by inflation. The single remaining degree of freedom points toward future theoretical work, particularly extending the model to redshift space and more complex tracer populations.
Bottom Line: An analytical model for density-split clustering, grounded in Large Deviation Theory, matches N-body simulations on cosmological scales with just one free parameter, offering a physics-first alternative to computationally expensive emulators for extracting non-Gaussian information from galaxy surveys.
IAIFI Research Highlights
This work connects statistical physics (Large Deviation Theory), cosmological perturbation theory, and data science into an analytical framework for galaxy clustering statistics that previously required machine-learning-based simulation emulators.
The analytical model provides a transparent, physically interpretable alternative to black-box simulation-based inference pipelines, showing how principled statistical theory can reduce dependence on neural network emulators in scientific contexts.
By enabling precise extraction of non-Gaussian clustering information from galaxy surveys like DESI, the model tightens our ability to constrain the fundamental physics of inflation, dark energy, and structure formation.
Future extensions to redshift space and weak lensing data will make this framework immediately applicable to ongoing surveys; the paper is available at [arXiv:2501.14638](https://arxiv.org/abs/2501.14638).