
A universal compression theory for lottery ticket hypothesis and neural scaling laws
Authors
Hong-Yi Wang, Di Luo, Tomaso Poggio, Isaac L. Chuang, Liu Ziyin
Abstract
When training large-scale models, the performance typically scales with the number of parameters and the dataset size according to a slow power law. A fundamental theoretical and practical question is whether comparable performance can be achieved with significantly smaller models and substantially less data. In this work, we provide a positive and constructive answer. We prove that a generic permutation-invariant function of $d$ objects can be asymptotically compressed into a function of $\operatorname{polylog} d$ objects with vanishing error, which is proved to be the optimal compression rate. This theorem yields two key implications: (Ia) a large neural network can be compressed to polylogarithmic width while preserving its learning dynamics; (Ib) a large dataset can be compressed to polylogarithmic size while leaving the loss landscape of the corresponding model unchanged. Implication (Ia) directly establishes a proof of the dynamical lottery ticket hypothesis, which states that any ordinary network can be strongly compressed such that the learning dynamics and result remain unchanged. (Ib) shows that a neural scaling law of the form $L\sim d^{-α}$ can be boosted to an arbitrarily fast power law decay, and ultimately to $\exp(-α' \sqrt[m]{d})$.
Concepts
The Big Picture
Imagine learning to recognize cats. You don’t need ten million examples; a few dozen will do. Yet today’s largest AI language models train on roughly a trillion words to reach human-level fluency, while a child masters language after hearing perhaps a hundred million words by age ten. That’s a ten-thousand-fold efficiency gap. Something fundamental is being wasted.
That waste shows up in neural scaling laws, the observed pattern that AI performance improves only as a slow, diminishing-returns curve as you add more data or computing power. To halve a language model’s error, you typically need to multiply your dataset tenfold or more. It’s a brutal tax on compute and energy, and until now no one had a clear explanation for whether it could be escaped.
A team from Princeton, MIT, Tsinghua, and UCLA now offers a mathematical proof that it can. Their theorem shows that any well-behaved function of d objects (data points or neurons) can be compressed to use only a tiny, slowly-growing fraction of those objects with negligible error. This simultaneously proves the lottery ticket hypothesis, the idea that large AI models secretly contain much smaller models that work just as well, and shows that the slow improvement rates governing AI training can be beaten.
The hidden symmetry in both neural networks and datasets means that most of their content is mathematically redundant. This redundancy can be provably eliminated, shrinking a trillion-element system down to perhaps a million elements without changing what it computes.
How It Works
The entire argument rests on one observation: permutation symmetry, the property that swapping any two elements leaves the result unchanged. When you measure how wrong a model is, you sum a penalty over every training example. Shuffle the data in any order and the total stays the same: the examples are interchangeable. Inside a neural network layer, swapping any two neurons (along with their weights) leaves the output identical.
This symmetry makes compression possible. Any permutation-symmetric function has a deep set representation: each input passes through the same feature detector, all results are summed, then a final function reads out the answer, written compactly as h(Σ g(wᵢ)). Under this structure, the key result is that when d objects live in an m-dimensional space and the function is smooth, those objects inevitably crowd together as d grows large.
Dense clusters mean redundancy. You can prune redundant elements and the error shrinks to zero. Here’s how the compression works:
- Identify crowding: As d → ∞, objects pack into a fixed bounded region, forming clusters by a pigeonhole argument.
- Select representatives: Use a geometric covering to pick O(polylog d) representatives approximating every cluster.
- Reweight: Assign each representative a weight proportional to its cluster size, preserving the function’s value.
- Bound the error: Because h and g are Taylor-expandable, error decays as exp(−α′ · d^(1/m)), faster than any power law.
The team also proves this compression rate is optimal.
Why It Matters
The dynamical lottery ticket hypothesis. The original lottery ticket hypothesis (Frankle & Carlin, 2019) proposed that large networks contain small “winning ticket” subnetworks trainable in isolation to similar accuracy. The dynamical version asks something harder: can you find a subnetwork that not only reaches the same final accuracy but follows the same training trajectory throughout?
The compression theorem says yes. A neural network’s forward pass is permutation-symmetric in its neurons, so any network of width d can be compressed to width O(polylog d). A trillion-neuron layer gets replaced by a few-million-neuron layer with identical learning dynamics, not just identical final performance.
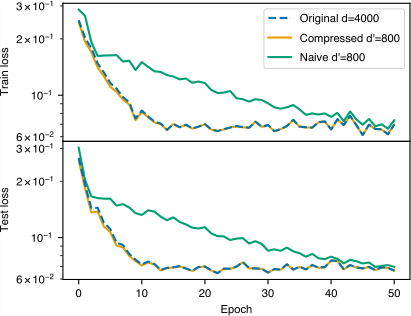
Faster scaling laws. Since the training loss is also permutation-symmetric in the data points, the same compression applies to data: a dataset of d examples can be pruned to O(polylog d) coreset examples, a carefully reweighted subset that preserves the full shape of the loss landscape.
This doesn’t just shift the scaling exponent. It changes the functional form entirely. A standard scaling law L ∝ d^(−α) becomes, after compression, L ∝ exp(−α′ · d^(1/m)). Exponential beats polynomial by an infinite margin. In numerical experiments, tasks that required millions of examples converge with far fewer, losses dropping faster than any power law predicts.
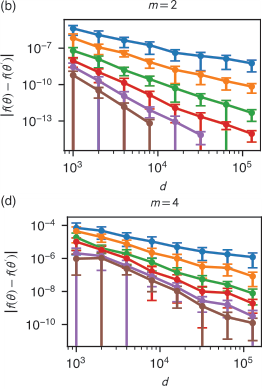
The AI field has largely accepted power-law scaling as a fact of life, planning exaflop training runs and petabyte datasets accordingly. But this result suggests that acceptance was premature. The slow power law reflects not a fundamental limit of learning, but a failure to exploit mathematical structure already present in every dataset and every network.
For physics-inspired AI, the result hits close to home. Permutation symmetry is a physicist’s bread and butter: it underlies Bose-Einstein statistics, identical-particle indistinguishability, and the symmetry principles organizing the Standard Model. The authors’ framework for compressing symmetric functions by exploiting redundancy is essentially the same logic physicists use when reducing a many-body problem to its irreducible representations. The connection between statistical learning theory and symmetry-based physics runs both ways.
Open questions remain. The smoothness assumption formally excludes ReLU networks, though numerical experiments suggest the conclusions hold regardless. Extending the theory to non-smooth architectures, attention mechanisms, and finite (rather than asymptotic) d would be the next steps. The real prize is translating the theoretical coreset construction into a practical training algorithm that achieves exponential scaling on real benchmarks.
Bottom Line: By proving that permutation symmetry makes both neural networks and datasets compressible to polylogarithmic size, this work establishes the dynamical lottery ticket hypothesis and shows that the slow power laws governing AI scaling are not fundamental limits but an efficiency gap waiting to be closed.
IAIFI Research Highlights
This work translates a physicist's intuition about symmetry and redundancy into a rigorous mathematical theory of neural network compression. The permutation symmetries shared by physics and machine learning turn out to be the key to improving data efficiency by orders of magnitude.
The paper provides the first proof of the dynamical lottery ticket hypothesis and a constructive theorem showing that neural scaling laws can be transformed from slow power-law decay into exponential decay, with direct implications for reducing the compute and data costs of training large models.
The compression framework applies symmetry-reduction principles, familiar from the physics of identical particles and group theory, to neural network learning dynamics, creating a new mathematical link between statistical physics and deep learning theory.
Future work will extend the theory to non-smooth architectures and develop practical coreset-construction algorithms that realize exponential scaling on real-world benchmarks; the full paper with proofs is available at [arXiv:2510.00504](https://arxiv.org/abs/2510.00504).