
Adaptive Length Image Tokenization via Recurrent Allocation
Authors
Shivam Duggal, Phillip Isola, Antonio Torralba, William T. Freeman
Abstract
Current vision systems typically assign fixed-length representations to images, regardless of the information content. This contrasts with human intelligence - and even large language models - which allocate varying representational capacities based on entropy, context and familiarity. Inspired by this, we propose an approach to learn variable-length token representations for 2D images. Our encoder-decoder architecture recursively processes 2D image tokens, distilling them into 1D latent tokens over multiple iterations of recurrent rollouts. Each iteration refines the 2D tokens, updates the existing 1D latent tokens, and adaptively increases representational capacity by adding new tokens. This enables compression of images into a variable number of tokens, ranging from 32 to 256. We validate our tokenizer using reconstruction loss and FID metrics, demonstrating that token count aligns with image entropy, familiarity and downstream task requirements. Recurrent token processing with increasing representational capacity in each iteration shows signs of token specialization, revealing potential for object / part discovery.
Concepts
The Big Picture
Imagine reading a novel and mentally giving equal attention to every sentence — whether it’s “The cat sat” or a densely packed paragraph describing a six-way intersection during rush hour. No human brain works this way. We automatically allocate more effort to complex, unfamiliar, or information-rich scenes.
Computer vision systems have done exactly the opposite for decades. In AI, images get broken into small units called tokens — data slots the system uses to describe what it sees. Whether it’s a blank sky or a crowded city street, these systems assign the same fixed number of tokens to every image.
This wastes computation and limits capability. A single leaf gets the same 256 tokens as a baroque cathedral interior. Text systems figured out something better long ago, giving more descriptive space to complex ideas. Vision is only now catching up.
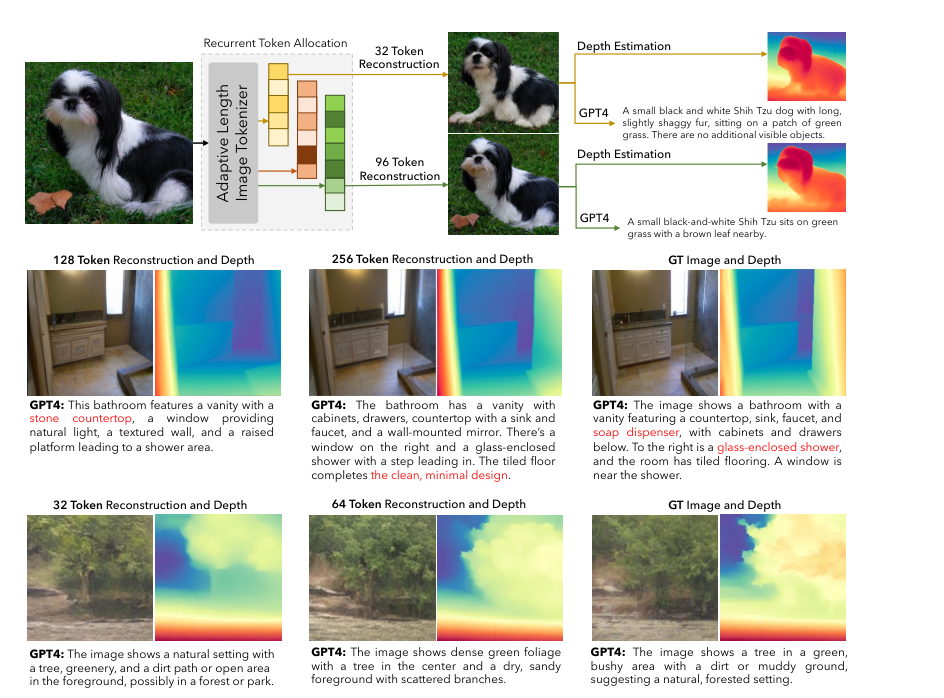
Researchers at MIT CSAIL have built a system that brings this adaptive logic to image understanding. Their tokenizer converts images into tokens that scale with content: as few as 32 for simple images, up to 256 for complex ones. The system makes multiple passes through each image, adding descriptive capacity where the image actually demands it — by processing images through iterative “recurrent rollouts” that let the model learn to allocate exactly as many tokens as needed.
How It Works
The core innovation is ALIT (Adaptive Length Image Tokenizer).
Processing starts by converting an input image into 2D image tokens — a standard grid-based representation, like a patchwork of small image crops that preserve the scene’s spatial structure.
ALIT then distills these into far more compact 1D latent tokens — flexible, compressed representations that capture the image’s meaning without being locked into the original grid. Where 2D tokens are like a map with fixed coordinates, 1D latent tokens are more like a list of key observations about the scene.
Rather than doing this in one shot, ALIT cycles through multiple recurrent rollouts:
- Initialize: Start with a small set of learnable 1D latent tokens (as few as 32). These adapt during training to better capture image content.
- Attend and update: A latent-distillation encoder lets these latent tokens absorb and refine information from the image grid.
- Add capacity: Each new iteration introduces fresh latent tokens, expanding the model’s representational budget.
- Dynamic halting: Image regions already well-captured get masked out and skipped. The system stops processing what it already understands.
The decoder reverses this process, reconstructing the original 2D image tokens from the 1D latents. Reconstruction quality becomes the feedback signal: the model learns which regions need more tokens, when to stop, and how to specialize. Training uses a self-supervised reconstruction objective — no labeled data required. The model simply tries to rebuild images from compressed representations, and the error from that rebuilding shapes it toward intelligent allocation.
Why It Matters
The results go beyond compression efficiency. When ALIT processes a complex bathroom scene, it naturally allocates more tokens than for a simple outdoor shot of a single tree — and the difference is meaningful, not arbitrary. Feed the bathroom image 32 tokens and you get a blurry approximation; give it 64 and architectural details snap into focus. This emerges from the training objective itself, not from hand-tuned parameters.
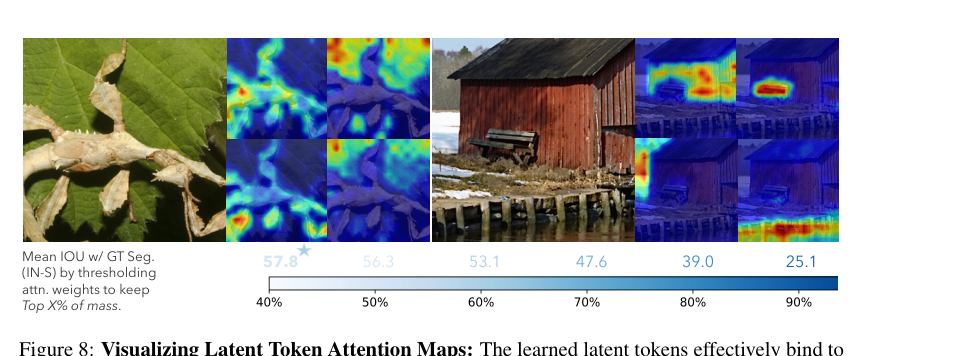
There’s also an emergent phenomenon the authors call token specialization. As ALIT recurses through iterations, different latent tokens begin to “own” different parts of the scene — individual objects, parts, even textures.
This points toward something researchers have long pursued: unsupervised object discovery, where a vision system carves a scene into meaningful components without being told what objects are. The recurrent, iterative structure appears to encourage this decomposition naturally.
For multimodal language models (systems that process both text and images), adaptive tokenization addresses a real bottleneck. The image side currently demands so many tokens that it slows inference and inflates memory usage. A tokenizer that compresses simple images aggressively while preserving detail for complex ones could make these systems far more efficient, and better calibrated to what actually matters in a scene.
IAIFI Research Highlights
This work advances a principle shared across cognitive science, information theory, and AI — that intelligent systems should allocate representational resources proportional to information content, with deep roots in physics-inspired compression and entropy theory.
ALIT introduces the first recurrent, variable-length image tokenizer trained end-to-end via self-supervised reconstruction, demonstrating that token count can align automatically with image complexity across a range from 32 to 256 tokens.
The emergent token specialization observed during recurrent processing suggests a pathway toward unsupervised object and part discovery — a capability directly relevant to scientific imaging tasks where identifying structures without labeled training data is critical.
Future work may extend ALIT to video, 3D data, and integration with large multimodal models; code and the full paper are available from the authors at MIT CSAIL, with the arXiv preprint ([arXiv:2411.02393](https://arxiv.org/abs/2411.02393)) as the primary reference.