
Anomaly preserving contrastive neural embeddings for end-to-end model-independent searches at the LHC
Authors
Kyle Metzger, Lana Xu, Mia Sodini, Thea K. Arrestad, Katya Govorkova, Gaia Grosso, Philip Harris
Abstract
Anomaly detection - identifying deviations from Standard Model predictions - is a key challenge at the Large Hadron Collider due to the size and complexity of its datasets. This is typically addressed by transforming high-dimensional detector data into lower-dimensional, physically meaningful features. We tackle feature extraction for anomaly detection by learning powerful low-dimensional representations via contrastive neural embeddings. This approach preserves potential anomalies indicative of new physics and enables rare signal extraction using novel machine learning-based statistical methods for signal-independent hypothesis testing. We compare supervised and self-supervised contrastive learning methods, for both MLP- and Transformer-based neural embeddings, trained on the kinematic observables of physics objects in LHC collision events. The learned embeddings serve as input representations for signal-agnostic statistical detection methods in inclusive final states. We achieve significant improvement in discovery power for both rare new physics signals and rare Standard Model processes across diverse final states, demonstrating its applicability for efficiently searching for diverse signals simultaneously. We study the impact of architectural choices, contrastive loss formulations, supervision levels, and embedding dimensionality on anomaly detection performance. We show that the optimal representation for background classification does not always maximize sensitivity to new physics signals, revealing an inherent trade-off between background structure preservation and anomaly enhancement. We demonstrate that combining compression with domain knowledge for label encoding produces the most effective data representation for statistical discovery of anomalies.
Concepts
The Big Picture
Imagine searching for a single misspelled word in every book ever printed, not knowing what word you’re looking for, or even what language it might be in. That’s roughly the challenge physicists face at the Large Hadron Collider. Every second, the LHC produces roughly 40 million proton collisions, and somewhere buried in that avalanche of data might be a particle or interaction that rewrites the textbook on fundamental physics. The catch: you don’t know what it looks like.
This is the core problem of model-independent anomaly detection, hunting for signs of new physics without a specific theory to guide the search. Standard approaches compress the LHC’s raw sensor data into a handful of physically meaningful numbers: particle energies, momenta (direction and force of motion), masses, and directions. But measurements hand-picked to capture known physics might inadvertently discard exactly the subtle patterns that signal something genuinely new.
A new study from MIT and ETH Zürich, led by Kyle Metzger and collaborators at IAIFI, takes a different route: let the machine learn its own compact representation of collision events, one built from the ground up to preserve anomalies rather than smooth them away.
Key Insight: Contrastive neural embeddings can learn low-dimensional representations of LHC collision data that are far more sensitive to rare new physics signals than classical feature engineering, but only when the right balance is struck between organizing background events and leaving room for anomalies to stand out.
How It Works
The core idea borrows from contrastive learning, a technique that teaches a neural network what “similar” and “different” mean without explicit labels. The network sees pairs or groups of events and learns to map them into a compact geometric space where events that look alike cluster together and unusual events get pushed to the outskirts.
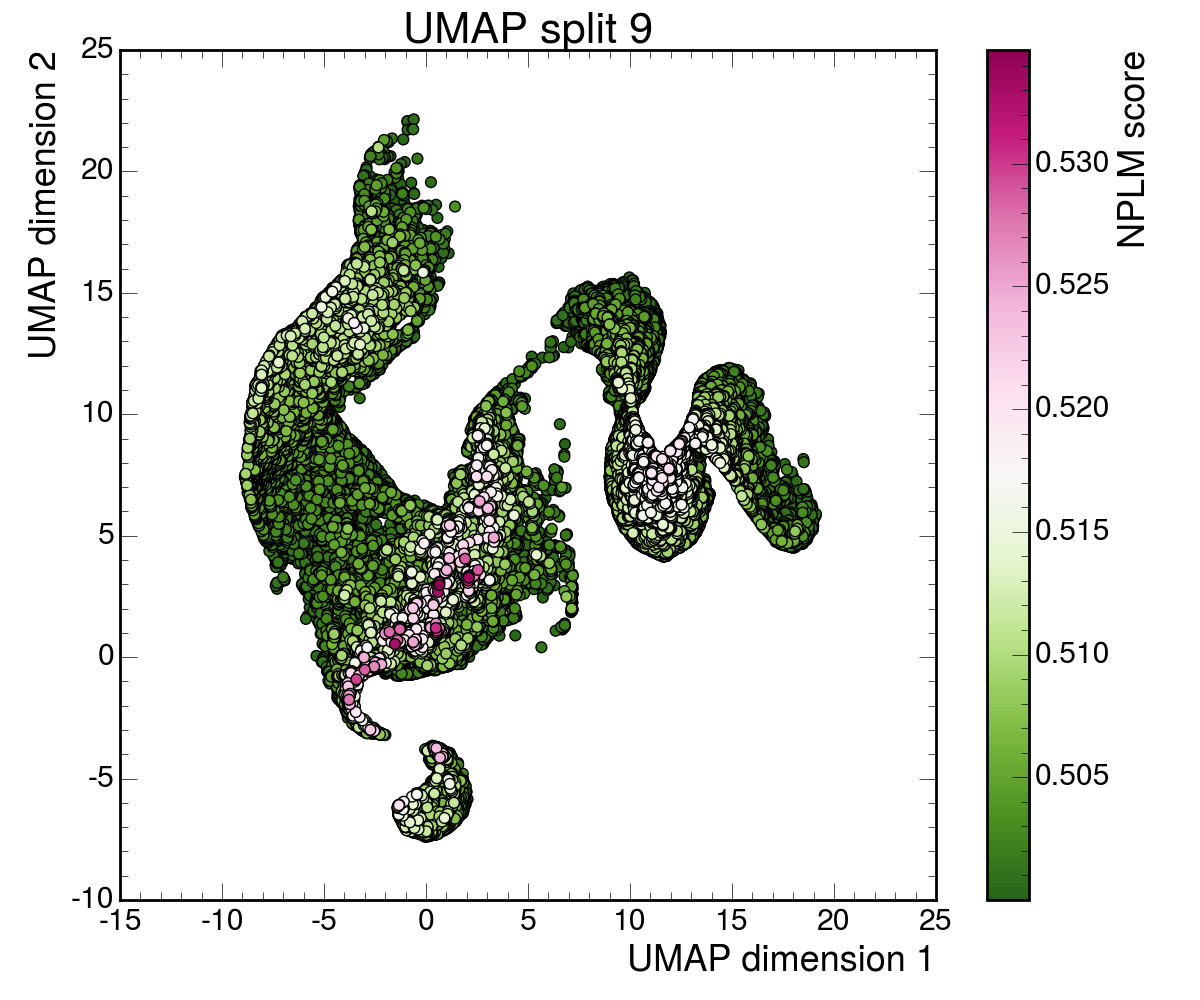
The researchers trained two flavors of contrastive embeddings (compact mathematical fingerprints of each collision event):
- Supervised contrastive learning, where physics labels like particle types and process categories guide the clustering.
- Self-supervised contrastive learning, where the network discovers structure on its own by randomly dropping or perturbing particle objects within an event to create different “views” of the same underlying collision.
Both were tested with two neural architectures. Multilayer perceptrons (MLPs) are a classic type of neural network that processes a fixed set of particle-level features. Transformers, the same architecture behind modern language models, treat each collision event as a variable-length sequence of physics objects and capture relationships between particles more naturally.
The inputs are measured properties of motion (energies, directions, and masses) of reconstructed physics objects: jets (sprays of particles from quark or gluon scattering), leptons (fundamental particles like electrons and muons), and missing energy (a signature of particles that escape the detector unseen). The network compresses all of this into an embedding with as few as 4 to 16 dimensions.
These embeddings feed into signal-agnostic statistical detection methods, algorithms that scan for unusual clusters in the embedding space without being told what signal to look for. Tested against a suite of benchmark new-physics signals and rare Standard Model processes, the contrastive embeddings consistently outperform hand-crafted features, achieving substantially higher sensitivity to injected rare signals at fixed false-positive rates.
Why It Matters
The most interesting finding here isn’t a benchmark number. It’s a conceptual warning. The researchers identified an inherent tension between two goals that might seem aligned: learning to classify background events accurately and learning to detect anomalies.
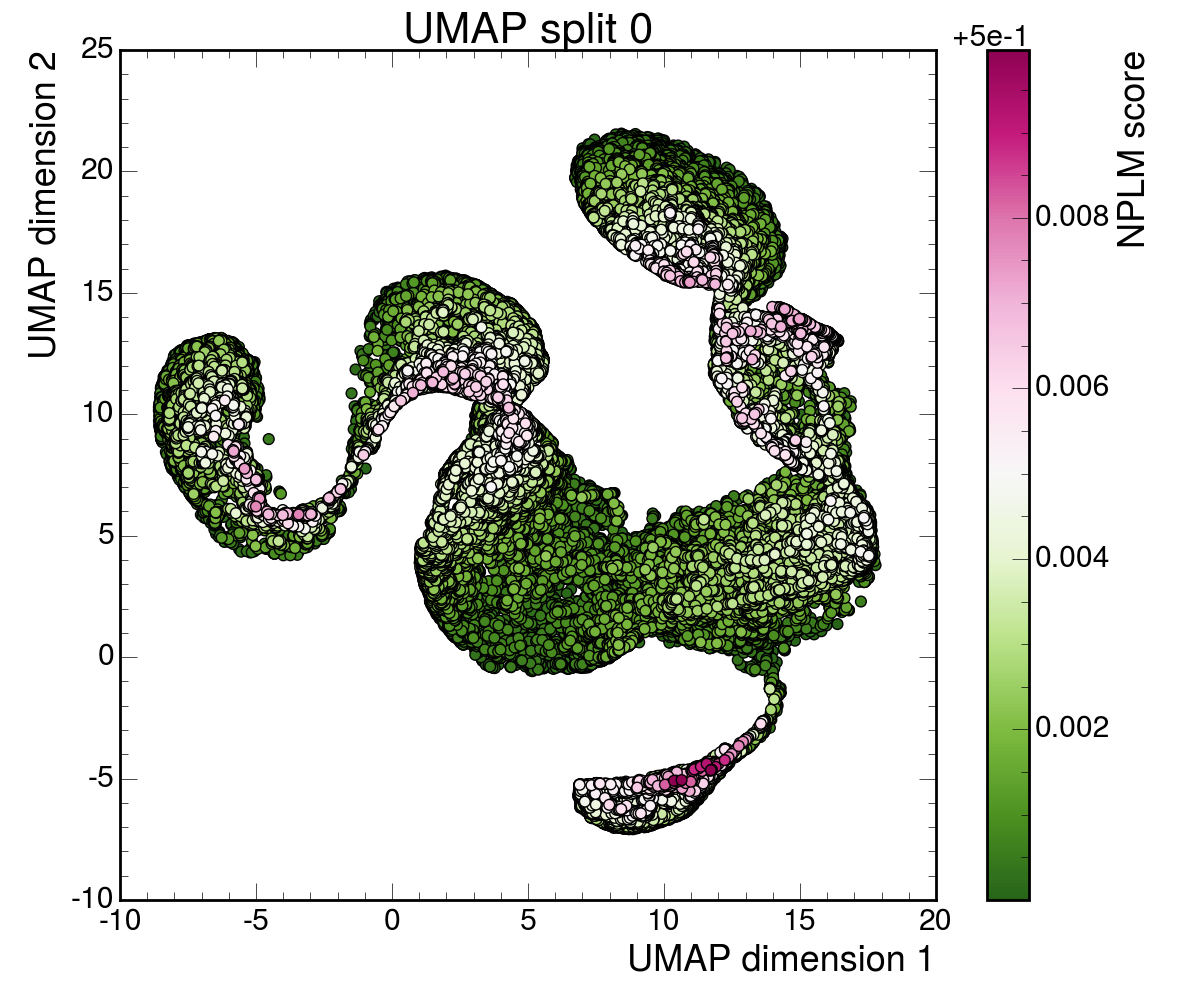
When you optimize a representation to organize known background processes as cleanly as possible, you inadvertently suppress the very irregularities that make new physics stand out. A perfectly organized background leaves no room for the unexpected. Put differently, the best representation for known physics is not the best representation for discovering unknown physics. That’s a subtle but consequential distinction, and it should shape how future searches are designed.
The sweet spot lies in combining two things: data compression (forcing the network to be selective about what it preserves) and domain knowledge (using physics-motivated labels to guide which background structures get organized). Supervised labels without compression risk encoding too much background detail. Compression without guidance can lose signal-relevant structure. Together, they produce embeddings that strike the right balance.
The LHC’s Run 3 is generating data at unprecedented rates, and the High-Luminosity LHC upgrade will push this further still. Model-independent searches are increasingly viewed as essential complements to targeted searches, but their power depends entirely on the quality of the representation feeding into them. A single trained embedding can simultaneously search for diverse signals across different final states, covering the full complexity of LHC collision data at once.
Open questions remain. How do these embeddings behave under detector systematics and real experimental noise? Can self-supervised versions be deployed in real-time trigger systems to catch anomalies before data is written to disk? The path from benchmark study to deployed LHC analysis is long, but the direction is clear.
Bottom Line: By learning compact, anomaly-preserving representations of LHC collision events through contrastive training, researchers have built a more sensitive radar for new physics, one that searches broadly across diverse signals without needing to know what it’s looking for.
IAIFI Research Highlights
The work adapts contrastive representation learning techniques from computer vision and NLP to the specific demands of high-energy physics anomaly detection, tailoring both self-supervised and supervised contrastive objectives to the structure of LHC collision data.
The study reveals a fundamental trade-off between background classification performance and anomaly sensitivity in learned representations, an insight applicable to any ML system tasked with open-ended anomaly detection in complex domains.
The contrastive embeddings yield significant gains in discovery power for rare new physics signals at the LHC, expanding the toolkit for model-independent searches that could reveal physics beyond the Standard Model.
Next steps include deploying these embeddings in real-time LHC trigger systems and testing their robustness under realistic experimental conditions; the full study is available at [arXiv:2502.15926](https://arxiv.org/abs/2502.15926).
Original Paper Details
Anomaly preserving contrastive neural embeddings for end-to-end model-independent searches at the LHC
2502.15926
["Kyle Metzger", "Lana Xu", "Mia Sodini", "Thea K. Arrestad", "Katya Govorkova", "Gaia Grosso", "Philip Harris"]
Anomaly detection - identifying deviations from Standard Model predictions - is a key challenge at the Large Hadron Collider due to the size and complexity of its datasets. This is typically addressed by transforming high-dimensional detector data into lower-dimensional, physically meaningful features. We tackle feature extraction for anomaly detection by learning powerful low-dimensional representations via contrastive neural embeddings. This approach preserves potential anomalies indicative of new physics and enables rare signal extraction using novel machine learning-based statistical methods for signal-independent hypothesis testing. We compare supervised and self-supervised contrastive learning methods, for both MLP- and Transformer-based neural embeddings, trained on the kinematic observables of physics objects in LHC collision events. The learned embeddings serve as input representations for signal-agnostic statistical detection methods in inclusive final states. We achieve significant improvement in discovery power for both rare new physics signals and rare Standard Model processes across diverse final states, demonstrating its applicability for efficiently searching for diverse signals simultaneously. We study the impact of architectural choices, contrastive loss formulations, supervision levels, and embedding dimensionality on anomaly detection performance. We show that the optimal representation for background classification does not always maximize sensitivity to new physics signals, revealing an inherent trade-off between background structure preservation and anomaly enhancement. We demonstrate that combining compression with domain knowledge for label encoding produces the most effective data representation for statistical discovery of anomalies.