
Any-Order Flexible Length Masked Diffusion
Authors
Jaeyeon Kim, Lee Cheuk-Kit, Carles Domingo-Enrich, Yilun Du, Sham Kakade, Timothy Ngotiaoco, Sitan Chen, Michael Albergo
Abstract
Masked diffusion models (MDMs) have recently emerged as a promising alternative to autoregressive models over discrete domains. MDMs generate sequences in an any-order, parallel fashion, enabling fast inference and strong performance on non-causal tasks. However, a crucial limitation is that they do not support token insertions and are thus limited to fixed-length generations. To this end, we introduce Flexible Masked Diffusion Models (FlexMDMs), a discrete diffusion paradigm that simultaneously can model sequences of flexible length while provably retaining MDMs' flexibility of any-order inference. Grounded in an extension of the stochastic interpolant framework, FlexMDMs generate sequences by inserting mask tokens and unmasking them. Empirically, we show that FlexMDMs match MDMs in perplexity while modeling length statistics with much higher fidelity. On a synthetic maze planning task, they achieve $\approx 60 \%$ higher success rate than MDM baselines. Finally, we show pretrained MDMs can easily be retrofitted into FlexMDMs: on 16 H100s, it takes only three days to fine-tune LLaDA-8B into a FlexMDM, achieving superior performance on math (GSM8K, $58\% \to 67\%$) and code infilling performance ($52\% \to 65\%$).
Concepts
The Big Picture
Imagine teaching someone to write by handing them a blank page with a fixed number of slots — say, exactly 47 blanks — and telling them to fill in words in any order they like. That’s essentially how today’s best “masked diffusion” language models work. They’re remarkably flexible about the order in which they fill in words, but completely rigid about how many words there will be.
That constraint matters enormously in practice. Real language doesn’t know in advance how long it needs to be. A math problem might need two steps or twenty. A code snippet might require three lines or three hundred. Forcing a model to pre-commit to a length is like asking a novelist to declare the exact word count before writing a single sentence.
A team of researchers from Harvard, MIT, Microsoft Research, and IAIFI has now cracked this problem. Their new framework — FlexMDMs (Flexible Masked Diffusion Models) — preserves everything that makes masked diffusion powerful while finally letting the model decide length on the fly.
Key Insight: FlexMDMs are the first masked diffusion models that can generate sequences of variable length while provably retaining the any-order, parallel generation that makes masked diffusion fast and powerful.
How It Works
Standard Masked Diffusion Models (MDMs) work by a process of hide-and-reveal: take a clean piece of text, progressively replace words with a special [MASK] placeholder, then train a neural network to reverse the process — predicting the original words at masked positions. At inference time, the model starts from a fully masked sequence and iteratively fills it in, in any order it chooses.
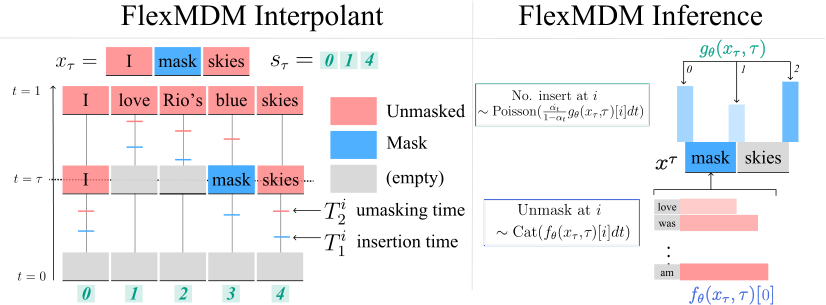
The “any order” part is a genuine superpower. Unlike autoregressive models (like GPT) — which must generate text strictly left-to-right, committing to each word before writing the next — MDMs can fill in the middle of a sentence first, then the beginning, then the end. This makes them faster and surprisingly effective at tasks where structure doesn’t flow left-to-right, like planning, code infilling (completing code that has gaps in the middle), and mathematical reasoning.
The catch: the model must start from a fixed-length masked sequence. If you want a 50-word output, you start with 50 masks. FlexMDMs fix this with a deceptively elegant move.
The core idea: instead of starting from a fully masked sequence of fixed length, FlexMDMs start from an empty string and proceed via two interleaved operations:
- Insertion — the model predicts how many new
[MASK]tokens to insert at each step, using a learned function gθ that outputs an expected insertion count based on what’s already been written - Unmasking — the model predicts what clean token should replace each existing mask, using the standard MDM posterior fθ
The result is a generation process that sculpts both content and length simultaneously. A sequence grows from nothing, acquiring structure and tokens in tandem, until the model decides it’s done.
The theoretical machinery underpinning this is non-trivial. The researchers ground FlexMDMs in continuous-time Markov chains (CTMCs) — a framework for systems that can jump between states at any moment in time, rather than only at fixed clock ticks — and introduce a new mathematical object called a joint interpolant. This extends the stochastic interpolant framework pioneered in part by IAIFI’s Michael Albergo, which provides a principled way to construct a probability path between two distributions.
Crucially, the researchers prove that FlexMDMs don’t just work empirically; they’re theoretically sound. Under perfect training, the model samples from the true data distribution and retains the any-order generation property. Getting both guarantees simultaneously required a continuous-time perspective — tracking changes moment-by-moment rather than in fixed steps — which is necessary to correctly capture how length evolves during generation.
Why It Matters
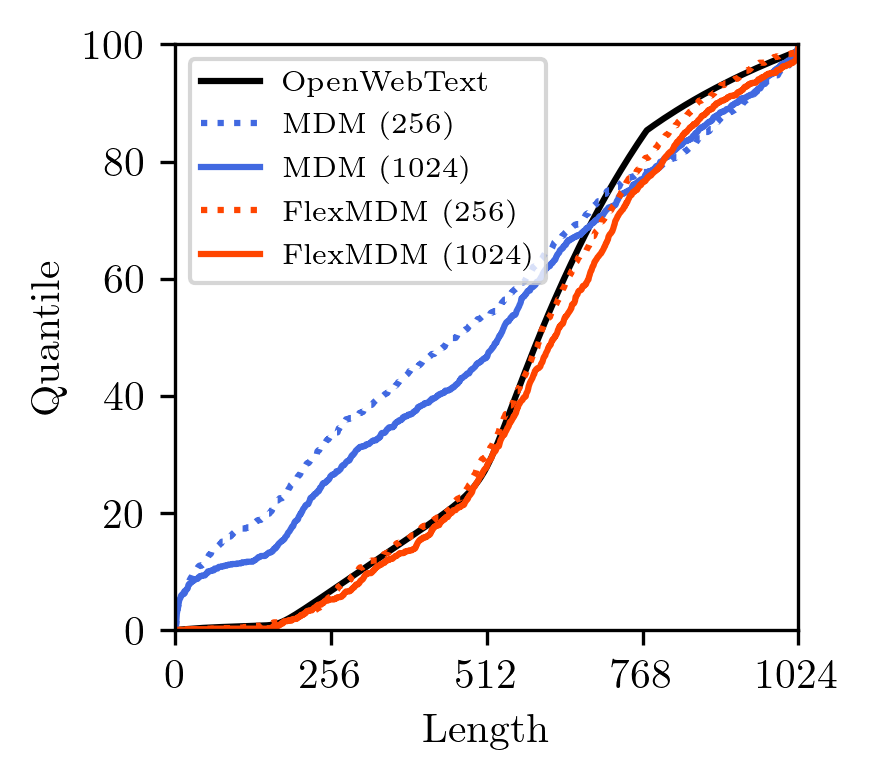
When trained on OpenWebText, FlexMDMs match standard MDMs on perplexity — the baseline measure of language quality — while dramatically outperforming them on length fidelity. Old MDMs, forced to assume a fixed length, had to hallucinate length from outside the model. FlexMDMs learn the length distribution from data, like any other aspect of language.
On a synthetic maze-planning task, where variable-length solution paths are the norm, FlexMDMs achieve roughly 60% higher success rates than MDM baselines. Planning is exactly the kind of task where you don’t know the answer length in advance, and that flexibility shows up directly in performance.
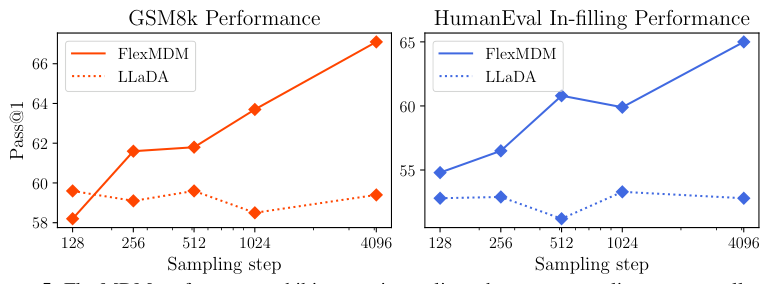
Perhaps most practically important: you don’t need to train a FlexMDM from scratch. The researchers took LLaDA-8B — a publicly available 8-billion parameter MDM — and fine-tuned it into a FlexMDM using just 16 H100 GPUs over three days. The retrofitted model improved math reasoning on GSM8K (a standard test of grade-school math word problems) from 58% to 67%, and code infilling from 52% to 65%. Those aren’t incremental gains; they represent a qualitative jump in capability enabled entirely by unlocking variable-length generation.
This opens a clear path for the broader research community. The enormous investment that has gone into training large MDMs doesn’t have to be discarded — it can be upgraded. FlexMDMs are a framework, not a model, and existing models can adopt it at modest cost.
The work also raises fascinating open questions. How does the insertion schedule interact with different types of content? Can FlexMDMs extend to multimodal settings — AI systems that work with more than one type of data, like text combined with images or audio — where “length” might mean image resolution or audio duration? The stochastic interpolant framework has already proven remarkably fertile ground, and this paper suggests it has more to give.
Bottom Line: FlexMDMs solve a fundamental limitation of masked diffusion — the inability to generate variable-length sequences — while preserving speed and any-order flexibility. Fine-tuning an existing 8B-parameter model in just three days yields double-digit gains on math and code tasks.
IAIFI Research Highlights
This work applies rigorous mathematical machinery from stochastic processes — continuous-time Markov chains and the stochastic interpolant framework developed at IAIFI — to solve a core limitation in large language model generation, exemplifying the institute's mission of bringing physics-inspired mathematics to frontier AI.
FlexMDMs are the first theoretically grounded masked diffusion framework capable of variable-length generation with any-order inference, directly improving state-of-the-art performance on math reasoning and code infilling benchmarks.
The joint interpolant formalism introduced here extends the stochastic interpolant framework in a mathematically principled way, contributing new theoretical tools that could inform generative modeling across physics simulation and beyond.
The ability to retrofit existing large MDMs into FlexMDMs at modest computational cost suggests rapid near-term adoption; the full paper and theoretical derivations are available on arXiv (arXiv:2602.09093).