
Aspects of scaling and scalability for flow-based sampling of lattice QCD
Authors
Ryan Abbott, Michael S. Albergo, Aleksandar Botev, Denis Boyda, Kyle Cranmer, Daniel C. Hackett, Alexander G. D. G. Matthews, Sébastien Racanière, Ali Razavi, Danilo J. Rezende, Fernando Romero-López, Phiala E. Shanahan, Julian M. Urban
Abstract
Recent applications of machine-learned normalizing flows to sampling in lattice field theory suggest that such methods may be able to mitigate critical slowing down and topological freezing. However, these demonstrations have been at the scale of toy models, and it remains to be determined whether they can be applied to state-of-the-art lattice quantum chromodynamics calculations. Assessing the viability of sampling algorithms for lattice field theory at scale has traditionally been accomplished using simple cost scaling laws, but as we discuss in this work, their utility is limited for flow-based approaches. We conclude that flow-based approaches to sampling are better thought of as a broad family of algorithms with different scaling properties, and that scalability must be assessed experimentally.
Concepts
The Big Picture
Imagine trying to predict the mass of a proton from first principles. Not measuring it, calculating it, starting from the fundamental equations of quantum chromodynamics (QCD), the theory of quarks and gluons that hold atomic nuclei together. This ranks among the most computationally demanding problems in science.
Physicists tackle it using lattice QCD: they discretize the equations on a grid of spacetime points, then use Monte Carlo methods to sample the astronomical number of possible field configurations. As you push toward physically realistic precision, this becomes agonizingly slow. Think of exploring a mountain range while your legs grow heavier with every step.
Machine learning offers a potential escape. Researchers have been exploring whether normalizing flows, neural networks that learn to transform simple random noise into something statistically resembling real physics, could replace or augment the standard algorithm, Hybrid Monte Carlo (HMC), and sidestep its worst behavior.
Early results were promising. But all demonstrations used toy models. Can these methods actually scale to state-of-the-art lattice QCD?
A collaboration spanning MIT, NYU, DeepMind, Argonne, and Wisconsin set out to answer that rigorously. Their conclusion is both sobering and clarifying: the standard tools physicists use to assess algorithm scalability simply don’t apply to flow-based methods the same way, and that fundamentally changes how we should evaluate them.
Key Insight: Flow-based sampling algorithms for lattice QCD aren’t a single method with a single scaling curve. They’re a family of approaches, each with different properties, and scalability can only be determined by experiment, not extrapolation.
How It Works
What makes lattice QCD so hard? The standard algorithm, HMC, simulates fictitious physical dynamics: picture rolling a ball downhill through a high-dimensional energy landscape, then accepting or rejecting where it lands with a statistical test. It works, but suffers two severe problems as you approach realistic parameters:
- Critical slowing down: Computational cost grows as a power law (or worse) with decreasing lattice spacing. You need exponentially more compute to halve your discretization error.
- Topological freezing: As lattice spacings shrink, HMC’s incremental exploration gets stuck in isolated regions of configuration space, becoming blind to field configurations with different topological charge, a number characterizing the global shape of the gauge field.
Both problems stem from HMC’s fundamentally local, step-by-step way of moving through configuration space.
Normalizing flows attack both problems at once by generating configurations globally, mapping a simple base distribution directly to an approximation of the target QCD distribution. A trained flow model draws a sample, applies a learned transformation parametrized by neural networks, and produces a gauge field configuration in one shot. The reweighting factor $w(\phi) = p(\phi)/q(\phi)$ between the learned model $q$ and the true target $p$ corrects for any mismatch.
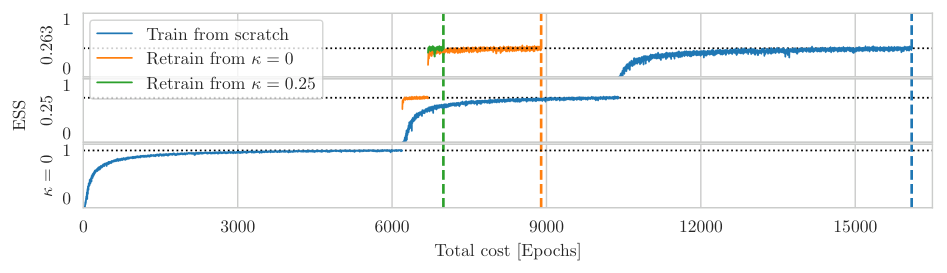
The design space is enormous. At every level (base distribution, flow transformation type, network architecture, training objective, how flows combine with other sampling steps) each decision creates a distinct algorithm with distinct scaling behavior. This is the crux of the paper’s argument.
For HMC, physicists have worked out precise cost scaling laws: equations predicting how total compute scales with lattice volume $L$, lattice spacing $a$, and quark mass $m$. Validated across decades of calculations, these laws let you extrapolate from a small test run to predict whether a larger one is feasible.
No analogous universal cost scaling law exists for flow-based methods. The scaling depends on which variant you’re using. Some components, like the number of samples needed for reliable reweighting, depend on how well the model approximates the target, which is itself a learned quantity that improves with more training. Others depend on architectural choices that don’t map cleanly onto physical parameters.
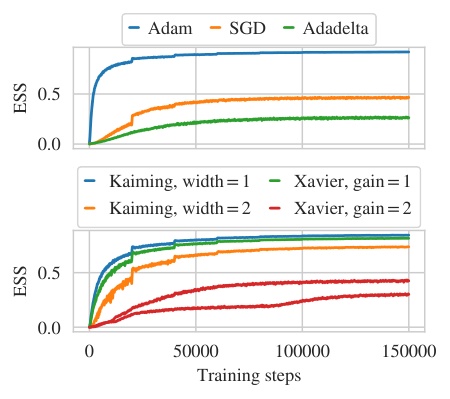
Numerical experiments drive the point home. Different flow-based approaches exhibit qualitatively different scaling with system size, quark mass, and other parameters. A scaling law fitted in one regime can be dramatically wrong when extrapolated to another. The integrated autocorrelation time, a measure of how many steps an algorithm must take before successive samples are statistically independent, is the standard efficiency metric for HMC. But it isn’t even the right quantity to minimize for flow-based samplers, since their configurations can be generated independently rather than sequentially.
The paper also draws a careful distinction between two concepts that often get conflated. Scalability asks: can this approach handle the volumes and parameters that matter for real physics? Cost scaling asks: how does cost change as you vary parameters? For HMC, these are tightly linked. For flows, they’re not. A method with poor cost scaling might still be scalable if it starts from a much lower absolute cost, or if training can be amortized across many calculations.
Why It Matters
This paper doesn’t deliver a new algorithm or a benchmark result. What it delivers is more valuable at this stage: a framework for thinking clearly about a problem the field has been arguing about somewhat loosely. As flow-based methods move from toy models toward realistic QCD calculations, the community needs to know how to evaluate them, and now has a cleaner vocabulary for that.
In practice, this means each flow architecture must be benchmarked in its target regime. No shortcuts. Some variants might shine at small lattice spacings where topological freezing cripples HMC; others might prove more cost-effective at specific quark masses or volumes. The diversity of approaches may turn out to be an advantage rather than a complication, with different physics problems calling for different flow strategies.
Hybrid algorithms that combine flows with conventional sampling steps are another natural direction, exploiting complementary strengths. How to train models efficiently, how to transfer a model trained at one set of parameters to nearby parameters, and how to handle the fermion content of full QCD all remain open questions.
Bottom Line: Flow-based sampling for lattice QCD isn’t a single gamble to assess with a single scaling curve. It’s a design space to be explored empirically. This paper provides the conceptual foundation for doing that exploration rigorously, which may prove critical as these methods mature toward state-of-the-art physics calculations.
IAIFI Research Highlights
This work directly merges deep learning methodology (normalizing flows and neural network architectures) with the precise statistical requirements of lattice QCD, providing a rigorous cross-disciplinary analysis of where ML sampling methods stand and how their performance should be measured.
The paper contributes a nuanced framework for evaluating generative model scalability in structured, high-dimensional scientific domains, where standard ML benchmarks don't apply and physical symmetries constrain the design space.
By clarifying the distinction between scalability and cost scaling for flow-based samplers, this work charts a principled path toward overcoming critical slowing down and topological freezing, the two core algorithmic bottlenecks limiting lattice QCD precision at small lattice spacings.
The authors call for experimental benchmarking of individual flow architectures across realistic QCD parameter regimes as the necessary next step; the full paper is available at [arXiv:2211.07541](https://arxiv.org/abs/2211.07541).
Original Paper Details
Aspects of scaling and scalability for flow-based sampling of lattice QCD
[2211.07541](https://arxiv.org/abs/2211.07541)
Ryan Abbott, Michael S. Albergo, Aleksandar Botev, Denis Boyda, Kyle Cranmer, Daniel C. Hackett, Alexander G. D. G. Matthews, Sébastien Racanière, Ali Razavi, Danilo J. Rezende, Fernando Romero-López, Phiala E. Shanahan, Julian M. Urban
Recent applications of machine-learned normalizing flows to sampling in lattice field theory suggest that such methods may be able to mitigate critical slowing down and topological freezing. However, these demonstrations have been at the scale of toy models, and it remains to be determined whether they can be applied to state-of-the-art lattice quantum chromodynamics calculations. Assessing the viability of sampling algorithms for lattice field theory at scale has traditionally been accomplished using simple cost scaling laws, but as we discuss in this work, their utility is limited for flow-based approaches. We conclude that flow-based approaches to sampling are better thought of as a broad family of algorithms with different scaling properties, and that scalability must be assessed experimentally.