
AutoSciDACT: Automated Scientific Discovery through Contrastive Embedding and Hypothesis Testing
Authors
Samuel Bright-Thonney, Christina Reissel, Gaia Grosso, Nathaniel Woodward, Katya Govorkova, Andrzej Novak, Sang Eon Park, Eric Moreno, Philip Harris
Abstract
Novelty detection in large scientific datasets faces two key challenges: the noisy and high-dimensional nature of experimental data, and the necessity of making statistically robust statements about any observed outliers. While there is a wealth of literature on anomaly detection via dimensionality reduction, most methods do not produce outputs compatible with quantifiable claims of scientific discovery. In this work we directly address these challenges, presenting the first step towards a unified pipeline for novelty detection adapted for the rigorous statistical demands of science. We introduce AutoSciDACT (Automated Scientific Discovery with Anomalous Contrastive Testing), a general-purpose pipeline for detecting novelty in scientific data. AutoSciDACT begins by creating expressive low-dimensional data representations using a contrastive pre-training, leveraging the abundance of high-quality simulated data in many scientific domains alongside expertise that can guide principled data augmentation strategies. These compact embeddings then enable an extremely sensitive machine learning-based two-sample test using the New Physics Learning Machine (NPLM) framework, which identifies and statistically quantifies deviations in observed data relative to a reference distribution (null hypothesis). We perform experiments across a range of astronomical, physical, biological, image, and synthetic datasets, demonstrating strong sensitivity to small injections of anomalous data across all domains.
Concepts
The Big Picture
Imagine searching for a counterfeit coin in a vault of a billion identical-looking ones, except the coins keep changing shape due to temperature and humidity, making “normal” impossible to define.
This is the problem facing scientists at particle colliders, astronomical observatories, and genomics labs every day. Datasets are vast, signals are faint, and the difference between a genuine discovery and a statistical fluke can define a career.
Standard anomaly-detection tools have a critical flaw: they can tell you something looks weird, but not how weird in any rigorous scientific sense. A detector that flags anomalies is useful. One that can say “this deviation has a one-in-ten-million chance of occurring by coincidence” is science. That distinction matters when you’re claiming a new particle, a novel astrophysical phenomenon, or an unexpected biological mechanism.
A team of MIT physicists at IAIFI has built AutoSciDACT (Automated Scientific Discovery with Anomalous Contrastive Testing), a general-purpose pipeline that addresses exactly this problem. It combines powerful pattern-recognition with rigorous statistical testing to make automated discovery not just sensitive, but scientifically credible.
Key Insight: AutoSciDACT doesn’t just flag anomalies; it quantifies their statistical significance using a principled hypothesis-testing framework, making machine-detected novelties compatible with the rigorous standards of scientific publication.
How It Works
AutoSciDACT runs in two phases that mirror the scientific method: first compress and represent the data intelligently, then rigorously test what you find.
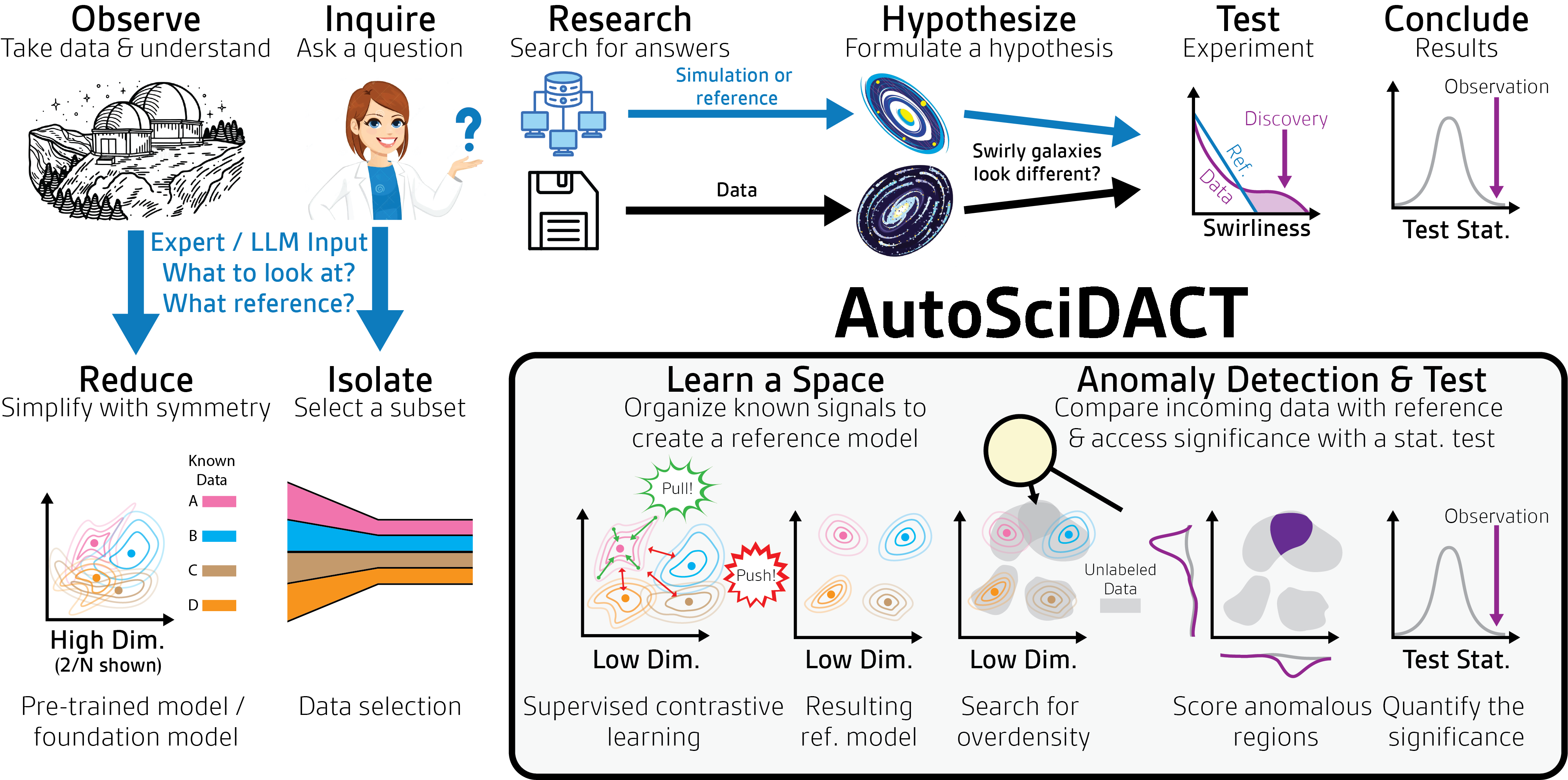
Phase 1: Contrastive Pre-Training. Raw scientific data (collision events, galaxy spectra, gene expression arrays) arrives with thousands of variables per data point, making direct analysis impossible. AutoSciDACT uses contrastive learning: train a neural network by showing it pairs of similar data points and pairs of different ones, and it learns to tell them apart without hand-labeling.
Instead of needing labeled real data, the pipeline exploits something physicists and astronomers have in abundance: high-quality simulations. These encode expert knowledge of what “normal” looks like. AutoSciDACT uses simulations to generate data augmentations (systematic variations like rotations or small perturbations) that teach the model which differences are physically meaningful and which are noise.
The result is a compact embedding: a handful of numbers capturing the essential physics of each data point while stripping away noise. This compression isn’t just a convenience. It’s what makes the next phase possible.
Phase 2: NPLM Hypothesis Testing. With embeddings in hand, AutoSciDACT deploys the New Physics Learning Machine (NPLM), a statistical test built on neural networks originally developed for high-energy physics. NPLM takes a “reference” dataset (what you’d expect if nothing unusual is happening) and checks whether the actual observed data could have come from the same source.
Rather than asking “are these distributions different?”, NPLM trains a neural network to find the most anomalous region in the compressed data, then computes how unlikely that deviation would be by pure chance. The output is a p-value: the probability this result is a fluke. Low p-values mean the anomaly is real and worth investigating.
The pipeline’s key steps:
- Collect simulated (reference) and real (observed) data
- Train a contrastive encoder using simulations and domain-guided augmentations
- Embed both datasets into low-dimensional space
- Run NPLM to identify the most anomalous region and compute statistical significance
- Report the deviation with a quantified p-value
Why It Matters
The team validated AutoSciDACT on benchmarks spanning astronomical, physical, biological, image, and synthetic datasets, all using the same pipeline architecture without domain-specific tuning beyond the augmentation strategy.
AutoSciDACT consistently detects small injections of anomalous data (sometimes just a fraction of a percent of the dataset) while maintaining tight control over false positives. The real advantage over prior methods isn’t raw sensitivity but calibration: the test statistics behave as expected under the null hypothesis, so the p-values are trustworthy, not merely suggestive.
Contrastive embeddings outperform simpler approaches for a concrete reason. Standard techniques like PCA (which finds the most variable directions in data) or autoencoders (neural networks trained to compress and reconstruct data) lose physically meaningful structure in the compression step. Contrastive embeddings preserve it. Because the network was trained to cluster physically similar things together, NPLM can find deviations that would be invisible in any naive low-dimensional representation.
The gap between “anomaly detection” and “scientific discovery” has been a persistent frustration in data-driven science. Dozens of papers have proposed sophisticated outlier-detection methods, but almost none produce outputs a scientist can act on: a number they can cite, a significance they can defend at a conference. AutoSciDACT fills that gap by treating statistical rigor as a first-class requirement rather than an afterthought.
Any domain with abundant simulation data (climate science, drug discovery, materials science, cosmology) could slot its own augmentation strategies into this framework and get a statistically trustworthy anomaly scanner. As AI becomes more embedded in scientific workflows, AutoSciDACT offers a model for doing it right: not just finding patterns, but knowing when to trust them.
Bottom Line: AutoSciDACT combines contrastive learning with rigorous hypothesis testing to produce the first general-purpose pipeline for statistically credible automated discovery, turning vague anomaly flags into quantified scientific claims across astronomy, physics, biology, and beyond.
IAIFI Research Highlights
AutoSciDACT fuses representation learning from modern machine learning with statistical hypothesis-testing frameworks developed for high-energy physics, creating a discovery pipeline applicable across multiple scientific domains.
Domain-guided contrastive pre-training, using simulations rather than labels, produces embeddings expressive enough to enable highly sensitive distribution-level anomaly detection.
By enabling statistically rigorous automated novelty detection at scale, AutoSciDACT tackles one of particle physics' core challenges: finding subtle deviations from Standard Model predictions in enormous, noisy collider datasets.
Future directions include handling systematic uncertainties and streaming data, and integrating agentic AI for automated follow-up hypothesis generation. The paper is available at [arXiv:2510.21935](https://arxiv.org/abs/2510.21935).