
Beyond I-Con: Exploring New Dimension of Distance Measures in Representation Learning
Authors
Jasmine Shone, Zhening Li, Shaden Alshammari, Mark Hamilton, William Freeman
Abstract
The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode similarities between data points. However, a KL-based loss may be misaligned with the true objective, and properties of KL divergence such as asymmetry and unboundedness may create optimization challenges. We present Beyond I-Con, a framework that enables systematic discovery of novel loss functions by exploring alternative statistical divergences. Key findings: (1) on unsupervised clustering of DINO-ViT embeddings, we achieve state-of-the-art results by modifying the PMI algorithm to use total variation (TV) distance; (2) supervised contrastive learning with Euclidean distance as the feature space metric is improved by replacing the standard loss function with Jenson-Shannon divergence (JSD); (3) on dimensionality reduction, we achieve superior qualitative results and better performance on downstream tasks than SNE by replacing KL with a bounded $f$-divergence. Our results highlight the importance of considering divergence choices in representation learning optimization.
Concepts
The Big Picture
Imagine you’re teaching a child to sort a pile of fruit. You could give them a rulebook that says “an apple is not an orange because they’re infinitely different,” but that extreme penalty for any mistake might make the child so afraid of errors that they just pile everything together. A gentler rulebook, one that says “an apple is somewhat different from an orange, and very different from a banana,” would produce much cleaner sorting. A new paper from MIT CSAIL puts exactly this tension to the test.
For years, machine learning researchers building representation learning systems (neural networks that organize the world into meaningful categories) have relied on a single measuring stick called KL divergence. KL divergence measures how different two probability distributions are from each other. It has a quirky property: it can become infinitely large.
That sounds like a feature. Punish really bad predictions heavily. But it turns out to be a bug. When your error penalty can blow up to infinity, your neural network learns to keep everything uncomfortably close together rather than risk placing anything too far apart.
A team led by Jasmine Shone and Zhening Li asked a pointed question: what if we just used a different measuring stick? Their answer, Beyond I-Con, shows that swapping out KL divergence for bounded alternatives doesn’t just work. It sets new state-of-the-art benchmarks across three major tasks in representation learning.
Key Insight: The machine learning field has been quietly locked into KL divergence as its default loss function, but bounded alternatives like Total Variation distance and Jensen-Shannon divergence consistently outperform it, suggesting the field has been leaving performance on the table for years.
How It Works
To understand Beyond I-Con, you first need its predecessor. The I-Con framework (Information Contrastive) was a unifying discovery: over 23 different representation learning methods, spanning contrastive learning (teaching models what things are by showing them what things are not), clustering (grouping similar things without labels), dimensionality reduction (compressing high-dimensional data into a 2D or 3D map), and more, were all secretly doing the same thing. Each was minimizing KL divergence between a “supervisory” distribution (what the data says things should look like) and a “learned” distribution (what the model currently thinks).
Beautiful in theory. But it raised an obvious follow-up: if they’re all doing the same thing, is that thing optimal?
Beyond I-Con generalizes I-Con by replacing KL divergence with any valid f-divergence, a broad family of mathematical formulas for comparing probability distributions, of which KL is just one special case. The team tested four candidates:
- KL divergence — the baseline; asymmetric, unbounded
- Total Variation (TV) distance — symmetric, bounded between 0 and 1
- Jensen-Shannon divergence (JSD) — a symmetrized, bounded variant of KL
- Hellinger distance — another bounded, symmetric option
The key distinction: KL divergence explodes to infinity as the learned probability approaches zero. TV, JSD, and Hellinger all stay bounded. That boundedness means the training algorithm isn’t catastrophically penalized for placing dissimilar things far apart, which is exactly what good representation learning should do.
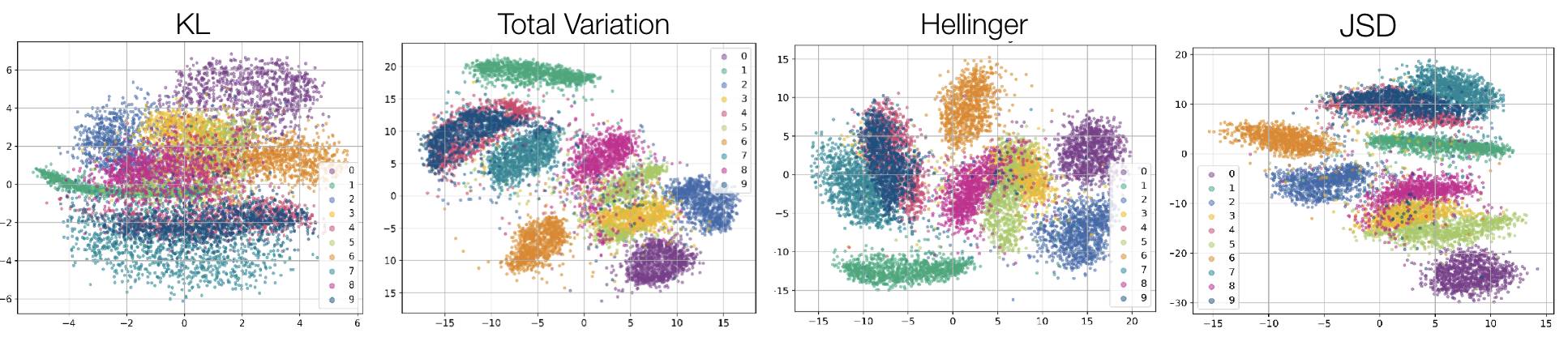
The dimensionality reduction results make this concrete. Running SNE (Stochastic Neighbor Embedding, an algorithm that compresses high-dimensional data into a 2D map) on CIFAR-10 images with KL divergence produces the classic “crowding problem”: ten color-coded classes smeared into a single overlapping blob. Swap in TV, JSD, or Hellinger, and the same algorithm produces ten cleanly separated islands. Same architecture, same data, same training procedure. Just a different measuring stick.
For unsupervised clustering (grouping images by similarity without any labels), the team modified the PMI algorithm to cluster DINO ViT embeddings on ImageNet-1K, one of the most demanding visual benchmarks in the field. Using TV distance, they beat previous results on both ViT-B/14 and ViT-L/14 models.
For supervised contrastive learning (training a model to pull similar examples together and push different ones apart), they trained on CIFAR-10 and found that JSD improved linear probe accuracy over the KL baseline consistently across multiple runs. Small numbers on a mature benchmark, but meaningful ones.
The gradient dynamics tell a similar story. With KL-based losses, training signals show violent spikes early in optimization, a sign of an unstable loss landscape. The bounded divergences train smoothly. The choice of loss function shapes the entire training trajectory.
Why It Matters
The benchmark numbers are the easy part. The deeper point is that contrastive learning methods like SimCLR, MoCo, and CLIP, which power much of modern visual AI, were designed around KL-adjacent objectives without anyone systematically testing whether KL was the right choice. Beyond I-Con shows that the choice of divergence is a genuine design axis, one that has gone essentially unexplored. If even small substitutions (KL → JSD) reliably improve performance, there may be a large and untapped design space here.
There’s a conceptual payoff too. I-Con showed that dozens of apparently different algorithms shared a hidden unity. Beyond I-Con adds a new dimension to that map: not just “which distributions are you comparing?” but “with what yardstick?” Future methods could be designed from the top down, choosing the divergence that best matches the geometry of the task, rather than inheriting KL by default.
Bottom Line: By replacing KL divergence with bounded alternatives like TV and JSD, Beyond I-Con achieves state-of-the-art clustering on ImageNet-1K and improves supervised contrastive learning on CIFAR-10, showing that one of machine learning’s most foundational assumptions deserves a second look.
IAIFI Research Highlights
This work applies tools from information geometry (the mathematical study of statistical distances) to practical deep learning, showing that theoretical choices about divergence measures have direct, measurable consequences for learned representations.
Beyond I-Con opens a new design axis for representation learning. Alternative f-divergences systematically outperform KL-based objectives across contrastive learning, clustering, and dimensionality reduction.
Better-structured representation learning benefits physics applications where neural networks must organize complex high-dimensional data, from particle physics simulations to lattice QCD, into interpretable low-dimensional embeddings.
Future work will explore tailoring divergence choices to specific data geometries and scaling these findings to larger foundation models; the paper was submitted to the Symmetry and Geometry in Neural Representations workshop at ICLR 2025. [[arXiv:2509.04734](https://arxiv.org/abs/2509.04734)]
Original Paper Details
Beyond I-Con: Exploring New Dimension of Distance Measures in Representation Learning
2509.04734
["Jasmine Shone", "Zhening Li", "Shaden Alshammari", "Mark Hamilton", "William Freeman"]
The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode similarities between data points. However, a KL-based loss may be misaligned with the true objective, and properties of KL divergence such as asymmetry and unboundedness may create optimization challenges. We present Beyond I-Con, a framework that enables systematic discovery of novel loss functions by exploring alternative statistical divergences. Key findings: (1) on unsupervised clustering of DINO-ViT embeddings, we achieve state-of-the-art results by modifying the PMI algorithm to use total variation (TV) distance; (2) supervised contrastive learning with Euclidean distance as the feature space metric is improved by replacing the standard loss function with Jenson-Shannon divergence (JSD); (3) on dimensionality reduction, we achieve superior qualitative results and better performance on downstream tasks than SNE by replacing KL with a bounded $f$-divergence. Our results highlight the importance of considering divergence choices in representation learning optimization.