
Bootstrapped Reward Shaping
Authors
Jacob Adamczyk, Volodymyr Makarenko, Stas Tiomkin, Rahul V. Kulkarni
Abstract
In reinforcement learning, especially in sparse-reward domains, many environment steps are required to observe reward information. In order to increase the frequency of such observations, "potential-based reward shaping" (PBRS) has been proposed as a method of providing a more dense reward signal while leaving the optimal policy invariant. However, the required "potential function" must be carefully designed with task-dependent knowledge to not deter training performance. In this work, we propose a "bootstrapped" method of reward shaping, termed BSRS, in which the agent's current estimate of the state-value function acts as the potential function for PBRS. We provide convergence proofs for the tabular setting, give insights into training dynamics for deep RL, and show that the proposed method improves training speed in the Atari suite.
Concepts
The Big Picture
Imagine learning to navigate a new city with only one piece of feedback: whether you’ve reached your destination. No street signs that feel familiar, no sense of getting closer, just wandering until you stumble onto the right address. This is the predicament facing reinforcement learning agents in sparse-reward environments: feedback arrives so rarely that learning grinds to a near-halt, burning through millions of trial-and-error steps for marginal progress.
One elegant solution, potential-based reward shaping (PBRS), gives agents a richer stream of intermediate rewards without corrupting the goal they’re supposed to achieve. The catch: you must hand-craft a “potential function” (a mathematical map encoding how valuable each state is) that demands detailed prior knowledge of the task. For complex environments, that knowledge simply isn’t available.
A new paper from researchers at UMass Boston, San José State, and Texas Tech has a simple fix: let the agent build its own map as it learns.
The result is Bootstrapped Reward Shaping (BSRS), a self-improving reward signal that requires no external task knowledge, changes only a single line of existing code, and demonstrably accelerates learning across both simple grid-worlds and complex Atari video games.
Key Insight: Instead of needing a perfect map before you start, BSRS lets the agent use whatever map it has right now, then updates that map as it gets smarter. The reward signal and the agent’s knowledge co-evolve together.
How It Works
PBRS, formalized by Ng, Harada, and Russell in 1999, works by adding a shaping bonus to every transition: a reward boost based on how much more valuable the new state is compared to the old one. If these bonuses are derived from a potential function Φ(s), they mathematically cancel out over complete trajectories, leaving the optimal policy unchanged. The agent still learns the right behavior; it just gets there faster because intermediate steps feel more informative.
The ideal potential function is the optimal state-value function V*(s) — a number encoding exactly how much long-term reward an agent can expect from any given state. But finding V* requires solving the very problem you’re trying to solve. A perfectly circular dependency.
BSRS cuts this knot with a pragmatic move. Rather than waiting for the optimal value function, the algorithm uses the current estimate V⁽ⁿ⁾(s) (whatever the agent believes about state values right now) as the potential function. This estimate starts rough and improves over time, so the reward shaping improves as the agent does.
The mechanics in practice:
- The agent maintains its value function estimate V⁽ⁿ⁾ through standard Q-learning updates — a classic algorithm where the agent tracks expected future rewards for each action in each state.
- At each step, instead of the raw environment reward r(s, a), the agent receives a shaped reward:
r̃ = r(s,a) + γV⁽ⁿ⁾(s') - V⁽ⁿ⁾(s) - As training progresses, V⁽ⁿ⁾ becomes more accurate and the shaping bonuses converge toward zero, leaving the true reward signal intact.
- In the deep RL setting, the value estimate comes from the agent’s neural network, with the target network (a periodically updated copy of the main network used to stabilize training) providing a stabilizing lag.
The convergence proof for the tabular setting (where the state space is small enough to store as a lookup table, rather than approximate with a neural network) is nontrivial. Because the potential function changes at every step, standard PBRS guarantees don’t automatically apply. The authors show that under standard Q-learning assumptions, BSRS converges to the same optimal policy, and they characterize the effective update rules that emerge from coupling reward shaping with value learning.
Why It Matters
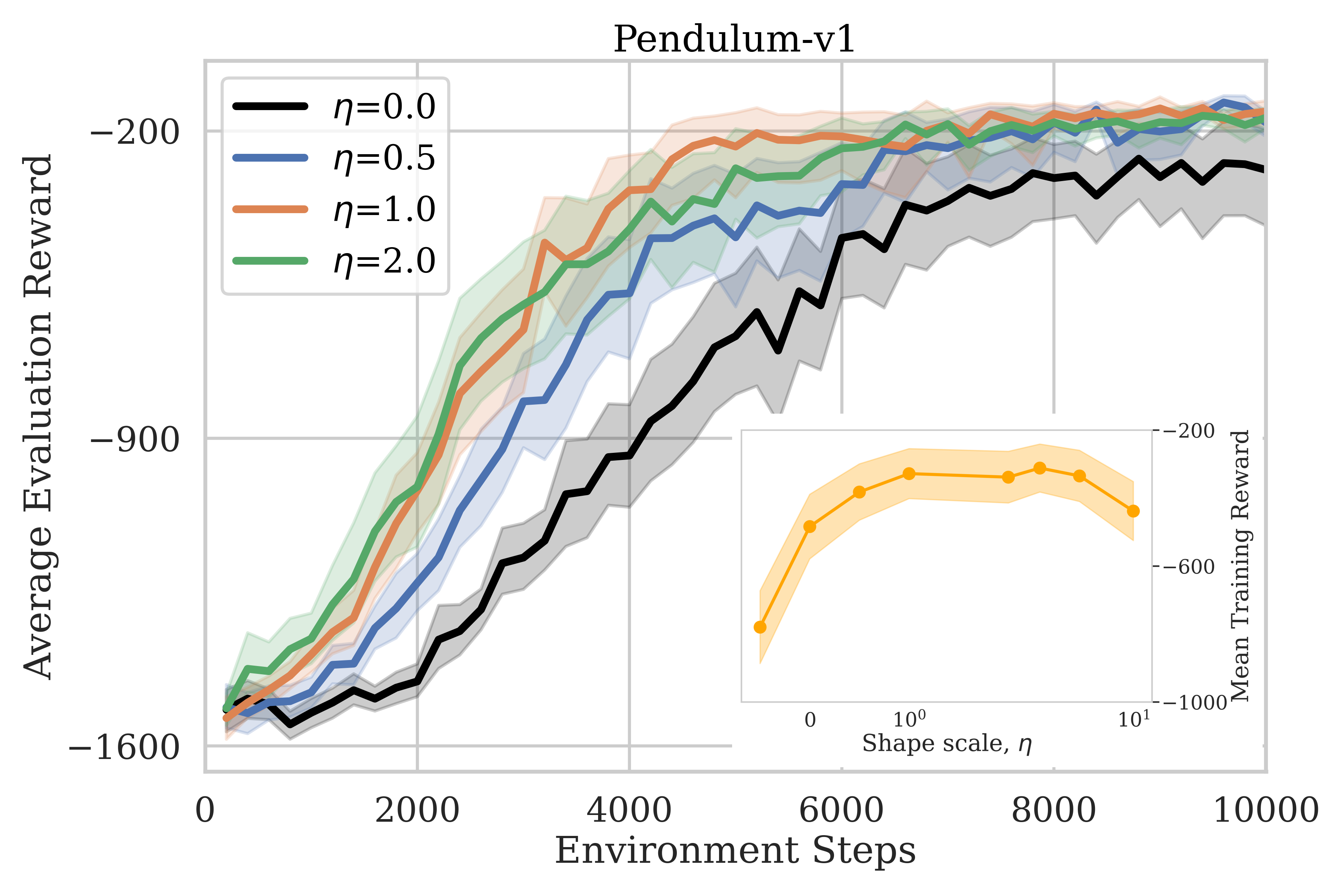
The experimental results validate the theory across multiple difficulty levels. In tabular grid-worlds with sparse rewards, BSRS agents converge significantly faster than vanilla Q-learning, particularly in larger state spaces where reward signals are hardest to stumble upon.
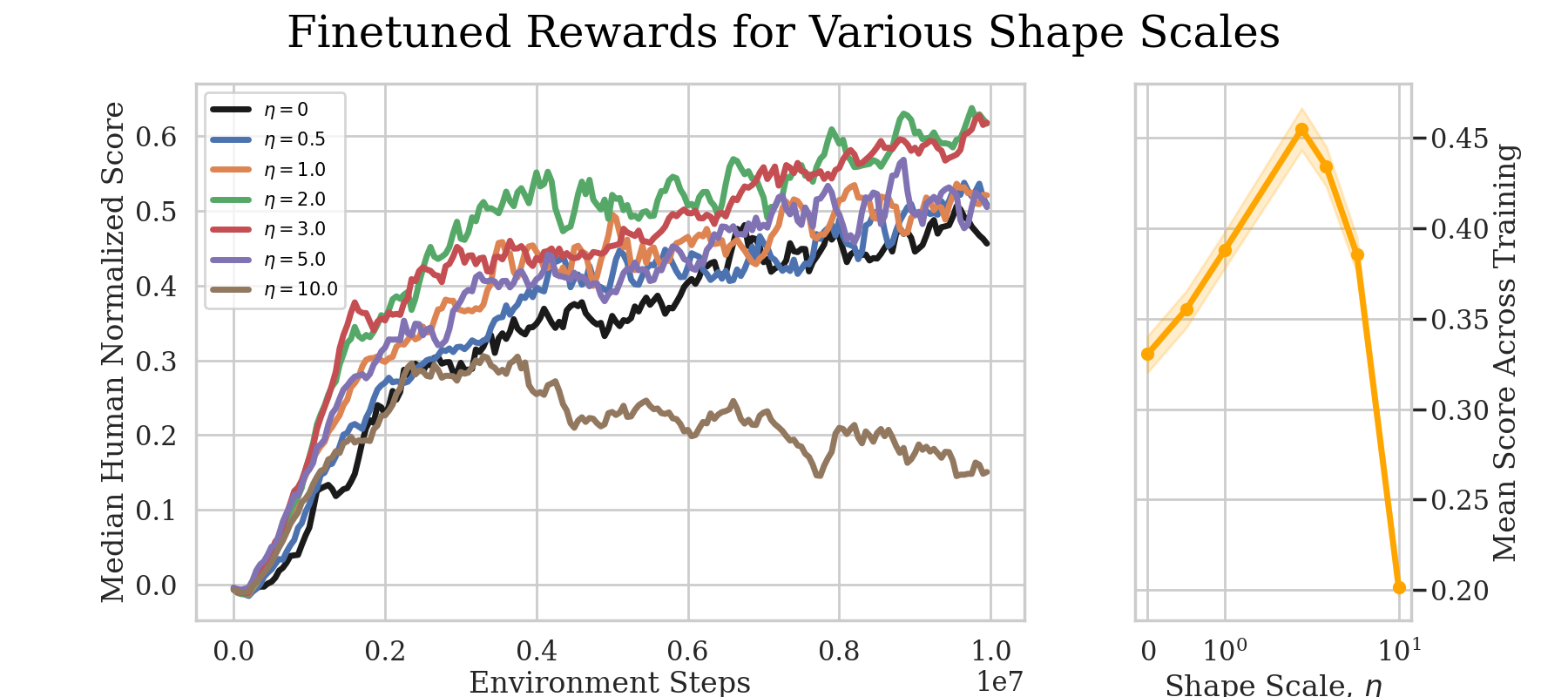
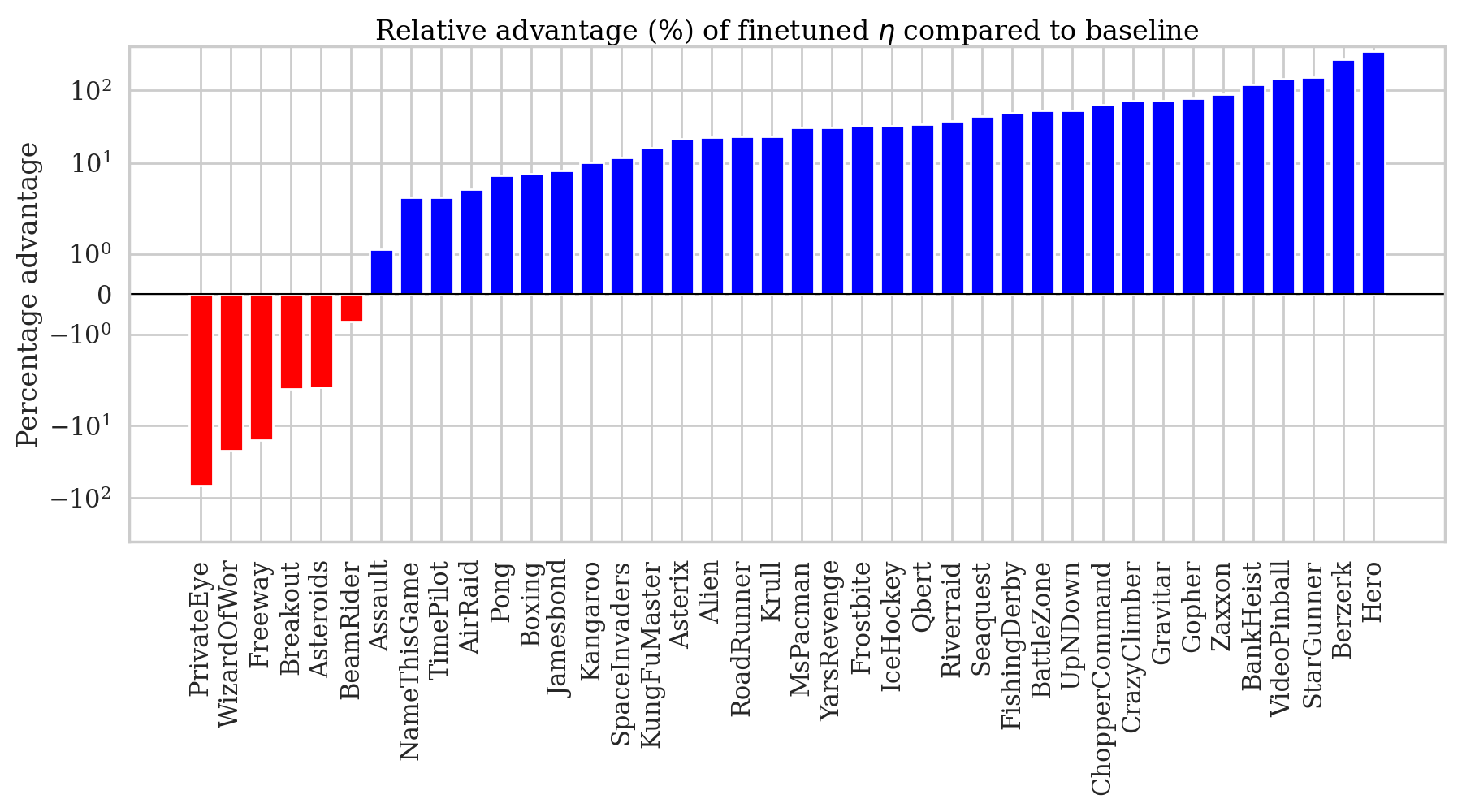
BSRS also improves training speed in the Atari Learning Environment, a benchmark suite of 57 classic video games that has challenged RL researchers for over a decade. These games involve high-dimensional image inputs, long horizons, and delayed sparse rewards. Gains here, from a method requiring no task-specific knowledge and a one-line code change, are meaningful.
The broader significance runs deeper than benchmark numbers. Reward engineering (designing reward functions that guide agents toward the right behavior without accidentally teaching them to exploit loopholes) is one of the central unsolved problems in applied RL. Systems that “reward hack” or develop unintended behaviors due to subtly mis-specified rewards are a genuine concern as RL gets deployed in higher-stakes settings.
BSRS doesn’t solve reward engineering, but it sidesteps a major source of manual intervention: the need to encode prior knowledge as a potential function. That reduction in human-specified structure is especially valuable in scientific discovery, robotics, and physical simulation, where task-relevant prior knowledge is hard to formalize.
Future directions include extending BSRS to continuous action spaces, integrating it with model-based approaches where a learned world model could sharpen the value estimates, and exploring whether bootstrapping can improve exploration rather than just exploitation.
Bottom Line: BSRS makes reinforcement learning more self-sufficient — an agent that shapes its own rewards using only what it’s already learned, with guaranteed convergence and measurable speedups across AI’s most challenging benchmarks.
IAIFI Research Highlights
This work provides convergence guarantees for a method where the reward signal itself changes during training. Proving convergence when the shaping function evolves at every step required analysis beyond standard PBRS theory, connecting mathematical rigor to a core challenge in modern AI — reflecting IAIFI's approach of grounding machine learning research in formal foundations.
BSRS delivers faster training in sparse-reward environments without task-specific engineering, a drop-in upgrade compatible with any value-based RL algorithm.
By reducing the sample complexity of reinforcement learning, BSRS lowers the computational barrier to applying RL in physics simulations and scientific discovery tasks where environment interactions are expensive.
Future work targets continuous action spaces, model-based integration, and applications in physics-driven environments. The paper is available at [arXiv:2501.00989](https://arxiv.org/abs/2501.00989) and code at [github.com/JacobHA/ShapedRL](https://github.com/JacobHA/ShapedRL).