
Bounding generalization error with input compression: An empirical study with infinite-width networks
Authors
Angus Galloway, Anna Golubeva, Mahmoud Salem, Mihai Nica, Yani Ioannou, Graham W. Taylor
Abstract
Estimating the Generalization Error (GE) of Deep Neural Networks (DNNs) is an important task that often relies on availability of held-out data. The ability to better predict GE based on a single training set may yield overarching DNN design principles to reduce a reliance on trial-and-error, along with other performance assessment advantages. In search of a quantity relevant to GE, we investigate the Mutual Information (MI) between the input and final layer representations, using the infinite-width DNN limit to bound MI. An existing input compression-based GE bound is used to link MI and GE. To the best of our knowledge, this represents the first empirical study of this bound. In our attempt to empirically falsify the theoretical bound, we find that it is often tight for best-performing models. Furthermore, it detects randomization of training labels in many cases, reflects test-time perturbation robustness, and works well given only few training samples. These results are promising given that input compression is broadly applicable where MI can be estimated with confidence.
Concepts
The Big Picture
Imagine you’re a teacher grading students, but you can only watch them study. You never see how they do on the final exam. Can you predict their grade anyway? This is roughly the challenge researchers face with deep neural networks: how well will a model perform on data it has never seen, using only the training data it was built on?
Estimating generalization error is one of the central unsolved problems in machine learning. Get it right, and you could design better AI systems without expensive trial-and-error, and provide performance guarantees for safety-critical applications where a bad model could cause real harm. The trouble is that most existing theoretical bounds are either useless in practice (giving estimates like “your model will be wrong less than 300% of the time”) or require a separate test dataset held back for evaluation, which defeats the purpose.
A team from the University of Guelph, MIT, and the Vector Institute for AI went after this problem directly. They drew on information theory, infinite-width neural network theory, and a decades-old intuition about how learning works to produce a bound on generalization error that is computable from training data alone and that actually works.
Key Insight: By measuring how much an infinite-width neural network compresses its inputs, quantified via mutual information, researchers can bound how badly a model will generalize without ever needing a test set.
How It Works
The central concept is mutual information (MI), a measure of how much knowing one variable tells you about another. Here, the question is: how much information does a network’s final-layer representation retain about the raw input? Heavy compression means most input was discarded; no compression means almost everything was kept.
The intuition comes from the Information Bottleneck principle: good learning means stripping away irrelevant details while preserving only what matters for the task. A model that memorizes every quirk of its training data retains high MI with inputs and fails to generalize. A model that distills only task-relevant features should do better on new examples.
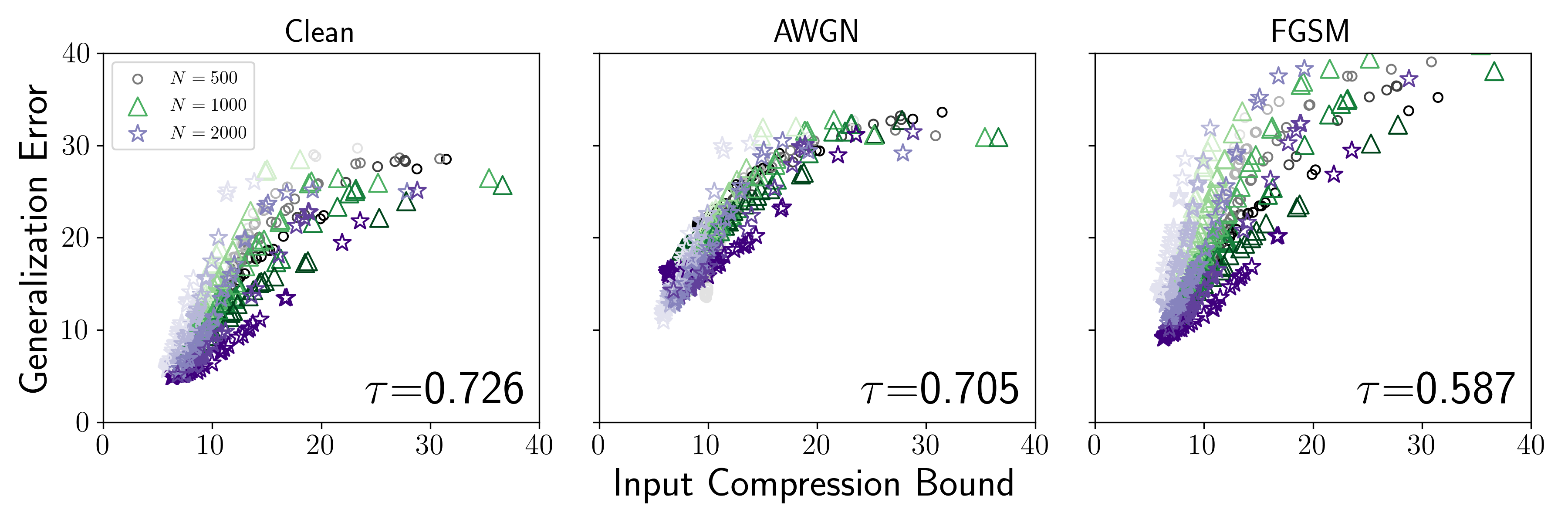
The team connects this intuition to a formal result called the Input Compression Bound (ICB), which links MI directly to generalization error. The bound had been derived theoretically but never tested empirically. This paper is the first to do so systematically.
Computing MI for real neural networks is notoriously hard. The researchers sidestep this by working with infinite-width networks, a mathematical limit where a neural network grows infinitely wide and its behavior becomes analytically tractable. In this regime, networks correspond to kernel regression using two tools:
- Neural Tangent Kernel (NTK): describes how a network’s predictions evolve during training
- Neural Network Gaussian Process (NNGP) kernel: models the network’s output as a full probability distribution rather than a point prediction
Both yield a conditional Gaussian predictive distribution, making MI estimation clean and parameter-free. Using an “InfoNCE” variational leave-one-out upper bound applied to these Gaussian distributions, the researchers compute an upper bound on MI entirely from training data, which feeds into the ICB to produce a bound on generalization error.
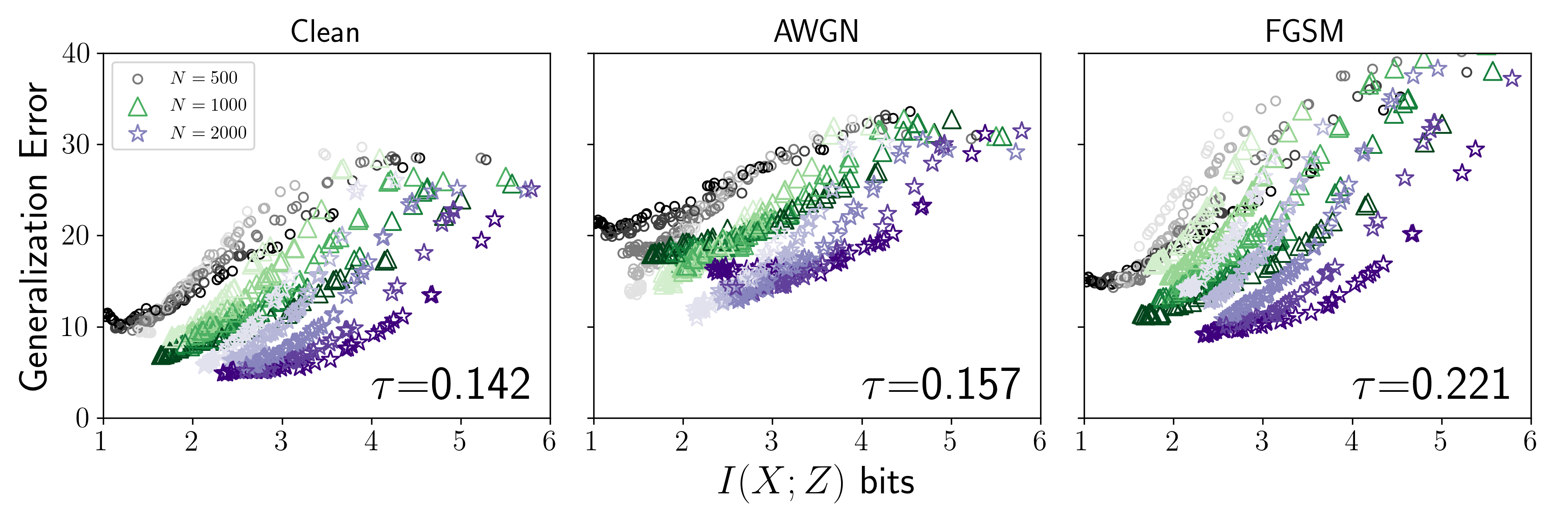
They tested this across five binary classification datasets, drawing random combinations of architecture and training hyperparameters:
- Falsification test: The ICB contained the true generalization error at the expected 95% confidence level for three of five datasets, and for all five when restricted to the best-performing models.
- Non-vacuous bounds: On fewer than 2,000 training samples, the ICB produced bounds below 50%, the trivial threshold for binary classification, making it practically useful.
- Ranking accuracy: The bound tracked model rankings reasonably well, though less reliably when many hyperparameters varied simultaneously.
Two other results are worth highlighting. First, the ICB detects label randomization: when models are trained on shuffled labels (a classic diagnostic for memorization), MI spikes and so does the ICB. The bound can flag memorizing models without ever checking test accuracy.
Second, models with lower ICB are more robust to test-time perturbations, small corruptions of input data that fool brittle models. This connection to robustness holds without assuming access to a differentiable model, which is both surprising and practically useful.
Why It Matters
Most generalization bounds in the literature are model-centric: they depend on properties of the network itself, like parameter count or weight magnitudes. The ICB is data-centric. It depends on how the network processes training inputs. As models grow larger and architectural choices become less predictive of generalization, this difference in perspective could prove decisive.
For AI broadly, a working generalization bound opens the door to principled Neural Architecture Search, where you select networks by optimizing a theoretical quantity rather than running thousands of trials. For safety-critical applications in physics, medicine, or autonomous systems, a certificate that bounds error is far more valuable than a test-set score. The connection to perturbation robustness matters too: physics experiments often involve instruments operating slightly outside calibration, and knowing a model degrades gracefully is worth a lot.
Open questions remain. The infinite-width limit is an approximation to real finite-width networks, and how well the bound transfers to modern architectures with billions of parameters is an active area of investigation. Reliable MI estimation is also required, a condition that holds in the regimes studied here but may break down for very high-dimensional inputs.
Bottom Line: This paper is the first empirical demonstration that an information-theoretic bound on generalization error actually works in practice. It is tight enough to be useful, computable without test data, and predictive of both label memorization and robustness. That makes it a real step toward replacing intuition and trial-and-error in deep learning with principled guarantees.
IAIFI Research Highlights
This work applies the Information Bottleneck framework, rooted in statistical physics intuitions about compression, to derive empirically testable guarantees for AI systems. It sits squarely at the intersection of physics and deep learning theory.
The paper provides the first empirical validation of an input-compression-based generalization bound, showing it is non-vacuous and practically informative on real datasets with fewer than 2,000 training samples.
The analysis is grounded in infinite-width network theory via NTK and NNGP kernels, tools with deep roots in mathematical physics. The work connects kernel methods to modern deep learning generalization and provides a cleaner theoretical handle on a notoriously difficult problem.
Extending these results to finite-width architectures and higher-dimensional datasets is a natural next step. The paper is available at [arXiv:2207.09408](https://arxiv.org/abs/2207.09408).
Original Paper Details
Bounding generalization error with input compression: An empirical study with infinite-width networks
2207.09408
["Angus Galloway", "Anna Golubeva", "Mahmoud Salem", "Mihai Nica", "Yani Ioannou", "Graham W. Taylor"]
Estimating the Generalization Error (GE) of Deep Neural Networks (DNNs) is an important task that often relies on availability of held-out data. The ability to better predict GE based on a single training set may yield overarching DNN design principles to reduce a reliance on trial-and-error, along with other performance assessment advantages. In search of a quantity relevant to GE, we investigate the Mutual Information (MI) between the input and final layer representations, using the infinite-width DNN limit to bound MI. An existing input compression-based GE bound is used to link MI and GE. To the best of our knowledge, this represents the first empirical study of this bound. In our attempt to empirically falsify the theoretical bound, we find that it is often tight for best-performing models. Furthermore, it detects randomization of training labels in many cases, reflects test-time perturbation robustness, and works well given only few training samples. These results are promising given that input compression is broadly applicable where MI can be estimated with confidence.