
CosmoFlow: Scale-Aware Representation Learning for Cosmology with Flow Matching
Authors
Sidharth Kannan, Tian Qiu, Carolina Cuesta-Lazaro, Haewon Jeong
Abstract
Generative machine learning models have been demonstrated to be able to learn low dimensional representations of data that preserve information required for downstream tasks. In this work, we demonstrate that flow matching based generative models can learn compact, semantically rich latent representations of field level cold dark matter (CDM) simulation data without supervision. Our model, CosmoFlow, learns representations 32x smaller than the raw field data, usable for field level reconstruction, synthetic data generation, and parameter inference. Our model also learns interpretable representations, in which different latent channels correspond to features at different cosmological scales.
Concepts
The Big Picture
Imagine trying to understand the entire history of the universe from a single photograph, but the photograph fills a warehouse. That’s where cosmologists find themselves with modern simulations of the cosmic web, the vast network of dark matter and galaxies spanning the observable universe. Simulations like AbacusSummit generate datasets exceeding 2,000 terabytes. Even machines choke at that scale.
The usual escape route is compression. But compression is a trade-off: squeeze too hard and you lose the subtle, small-scale features that carry real cosmological information. The power spectrum, a standard tool that measures how much structure exists at each spatial scale, discards information about where that structure is located. Machine learning alternatives like variational autoencoders (VAEs) tend to produce smeared reconstructions, like a watercolor version of a photograph. For cosmology, where the fine-grained clumping of matter encodes fundamental physics, “smeared” isn’t good enough.
Researchers from UC Santa Barbara and MIT have built a model called CosmoFlow that sidesteps this trade-off. It compresses cosmological field data by a factor of 32 while preserving the detailed structure that makes the data scientifically useful. Each simulation gets encoded into a compact latent code of just 8 numbers, and that’s enough to reconstruct the original.
Key Insight: CosmoFlow uses flow matching, a recent generative modeling framework, to learn compact, interpretable representations of dark matter simulations without any supervision. A single compressed latent code supports reconstruction, synthetic data generation, and parameter inference.
How It Works
The core idea harnesses a generative modeling technique called flow matching. Instead of encoding data into a fixed representation and decoding it directly (the VAE approach), flow matching learns a trajectory: a smooth path through probability space that gradually transforms random noise into a realistic simulation output. The model learns the velocity field at every point along this path, meaning the direction and speed of the transformation.
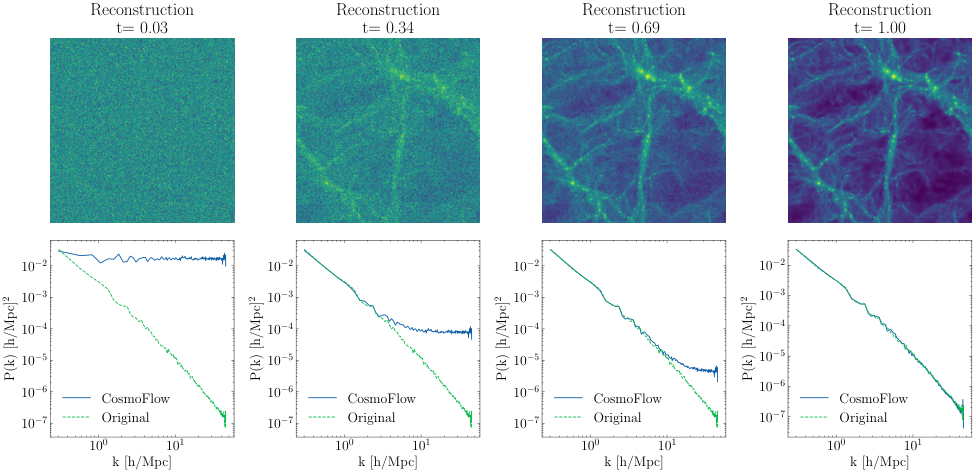
CosmoFlow’s architecture has two main components:
- A ResNet encoder compresses the raw 256×256 dark matter field into a smaller compressed field. ResNets are neural networks built from stacked layers that each refine a previous estimate, widely used for image analysis.
- During iterative decoding, a UNet-based velocity field predictor guides full-resolution generation. The UNet (shaped like a U, with layers that progressively zoom out to capture broad patterns then zoom back in to restore fine detail) is conditioned on both the masked compressed field and a summary statistics vector of just 8 numbers extracted via global pooling.
Those 8 numbers are the latent code. By conditioning generation on this vector, the model is forced to capture everything statistically relevant: cosmological parameters, large-scale structure, and fine-grained features alike. The training objective minimizes the difference between the predicted velocity and the straight-line path from noise to data. No labeled pairs, no manual similarity definitions.
The result is a latent space 32 times smaller than the raw data, yet rich enough to support three downstream tasks:
- Field reconstruction — regenerating the original simulation from the compressed code
- Synthetic data generation — producing physically plausible simulations at parameter values absent from the training set
- Cosmological parameter inference — estimating fundamental parameters like the matter density Ω_m directly from the 8-element latent vector, with accuracy matching inference on the raw field
Why It Matters
The most striking result here isn’t the compression ratio. It’s what the model learned on its own.
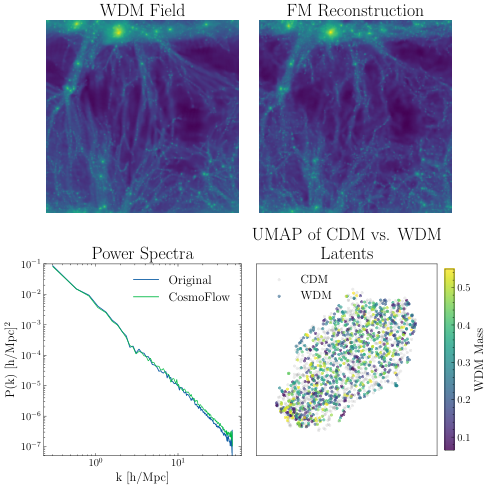
Without being told to, CosmoFlow organized its 8-element latent code so that different channels correspond to cosmological features at different spatial scales. Interpolating only the high-frequency channels produced more granular, small-scale clumping and shifted only the high-frequency components of the power spectrum. Interpolating the low-frequency channels smoothed the image and shifted only large-scale structure. The model spontaneously discovered a scale-organized representation of the universe.
This kind of interpretability is rare. In most deep learning systems, internal representations are inscrutable: useful for prediction but meaningless to physicists. CosmoFlow’s latent space has a physical grammar. Different dimensions speak to different scales of cosmic structure, echoing how cosmologists themselves decompose the universe by length scale.
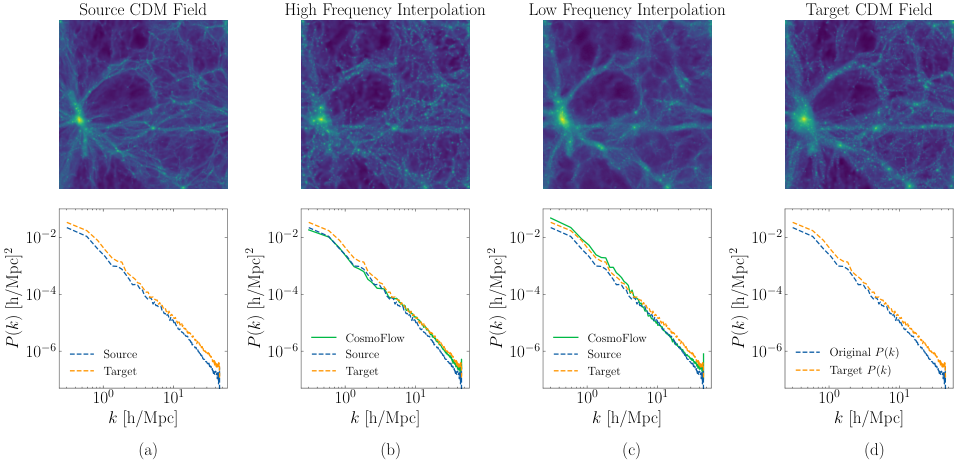
On the practical side, 32x compression that preserves both reconstruction quality and downstream task performance dramatically shrinks the computational burden of working with cosmological simulations. Training datasets currently requiring petabytes of storage could be represented in a fraction of the space. For large collaborations running thousands of simulations to explore parameter space, that changes the game.
The methodological lesson runs deeper. Flow matching was developed primarily for image and audio generation, but it carries inductive biases that make it naturally suited to scientific data with multiscale structure. The fact that CosmoFlow learns scale-separated representations without explicit supervision suggests the flow matching objective aligns with the physics of cosmological fields in a way that wasn’t engineered. That principle is worth testing across other domains where multiscale structure matters: turbulent fluid dynamics, quantum field theory, and beyond.
Open questions remain. The current model operates on 2D projected fields; extending to full 3D simulations will require significant architectural scaling. The model also shows deviations from ground truth at the highest frequencies, a limitation that must be addressed before CosmoFlow is ready for precision cosmology.
Bottom Line: CosmoFlow compresses dark matter simulations 32-fold using flow matching, achieving reconstruction quality that leaves VAEs behind. Along the way, it spontaneously learns a physically interpretable latent space organized by cosmological scale, with no supervision required.
IAIFI Research Highlights
CosmoFlow applies flow matching, a generative AI technique, to a core problem in observational cosmology. The model's inductive biases turn out to naturally align with the multiscale structure of the cosmic web.
Flow matching models can learn compact, semantically rich, and interpretable latent representations of scientific field data without supervision, extending generative representation learning beyond natural images.
By enabling 32x compression of cold dark matter simulations while preserving parameter inference accuracy, CosmoFlow makes it feasible to train machine learning models on much larger cosmological datasets, advancing our ability to test and constrain the ΛCDM model.
Future directions include scaling to 3D simulation volumes and improving high-frequency reconstruction fidelity; the full paper is available at [arXiv:2507.11842](https://arxiv.org/abs/2507.11842) from the UC Santa Barbara and MIT collaboration.