
Cosmological constraints from density-split clustering in the BOSS CMASS galaxy sample
Authors
Enrique Paillas, Carolina Cuesta-Lazaro, Will J. Percival, Seshadri Nadathur, Yan-Chuan Cai, Sihan Yuan, Florian Beutler, Arnaud de Mattia, Daniel Eisenstein, Daniel Forero-Sanchez, Nelson Padilla, Mathilde Pinon, Vanina Ruhlmann-Kleider, Ariel G. Sánchez, Georgios Valogiannis, Pauline Zarrouk
Abstract
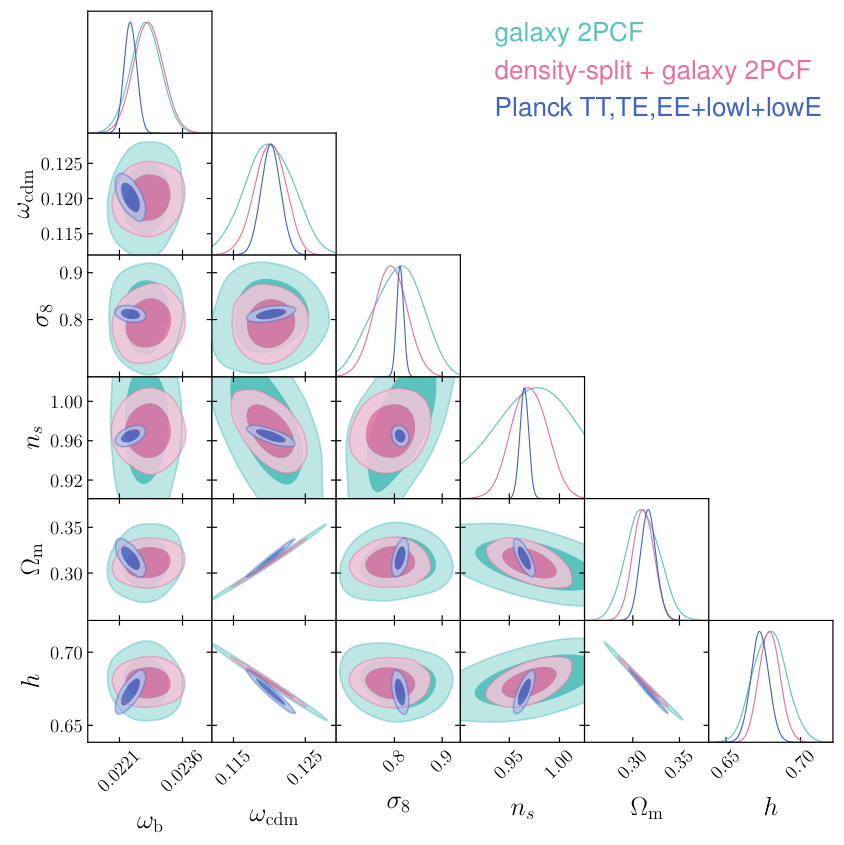
We present a clustering analysis of the BOSS DR12 CMASS galaxy sample, combining measurements of the galaxy two-point correlation function and density-split clustering down to a scale of $1\,h^{-1}{\rm Mpc}$. Our theoretical framework is based on emulators trained on high-fidelity mock galaxy catalogues that forward model the cosmological dependence of the clustering statistics within an extended-$Λ$CDM framework, including redshift-space and Alcock-Paczynski distortions. Our base-$Λ$CDM analysis finds $ω_{\rm cdm} = 0.1201\pm 0.0022$, $σ_8 = 0.792\pm 0.034$, and $n_s = 0.970\pm 0.018$, corresponding to $fσ_8 = 0.462\pm 0.020$ at $z \approx 0.525$, which is in agreement with Planck 2018 predictions and various clustering studies in the literature. We test single-parameter extensions to base-$Λ$CDM, varying the running of the spectral index, the dark energy equation of state, and the density of massless relic neutrinos, finding no compelling evidence for deviations from the base model. We model the galaxy-halo connection using a halo occupation distribution framework, finding signatures of environment-based assembly bias in the data. We validate our pipeline against mock catalogues that match the clustering and selection properties of CMASS, showing that we can recover unbiased cosmological constraints even with a volume 84 times larger than the one used in this study.
Concepts
The Big Picture
Imagine trying to understand a city’s population by counting how many buildings stand within a mile of each other. You’d miss the rich neighborhoods clustered near the park, the sparse suburbs, the dense downtown core.
For decades, cosmologists have measured galaxies using the two-point correlation function, which counts how often galaxy pairs appear at different separations. It works well, but it treats dense cosmic filaments and empty voids as equally informative. They’re not.
The universe isn’t smooth. After 13.8 billion years of gravitational collapse, matter has clumped into a vast cosmic web of filaments, sheets, clusters, and enormous empty voids. All that structure encodes secrets about dark matter, dark energy, and the growth rate of the universe. Classic two-point statistics handle large scales well but fall short at small scales, where gravity creates complex, tangled structures that resist clean mathematical description. Cosmologists have been leaving information on the table.
A team led by Enrique Paillas, including IAIFI’s Carolina Cuesta-Lazaro, found a way around this limitation. They combined density-split clustering with machine-learning emulators to pin down the universe’s fundamental properties more precisely than before from the BOSS CMASS galaxy survey.
Key Insight: By splitting the galaxy field into regions of different local density and measuring clustering statistics in each environment separately, researchers capture non-Gaussian information that standard two-point analyses miss, squeezing more science from existing survey data.
How It Works
The idea is simple. Rather than treating all galaxies equally, the team first smoothed the galaxy density field and divided space into quintiles: five bins ranked by local galaxy density, from the emptiest voids to the most crowded clusters. Correlation functions measured in each environment carry distinct cosmological fingerprints.
To make this practically useful, they needed a theoretical model that could predict density-split correlation functions for any set of cosmological parameters without running a full N-body simulation (a computer model tracking how millions of particles attract and clump under gravity over cosmic time) every single time. Their solution: train neural network emulators on a library of high-fidelity mock galaxy catalogues. These emulators learn to interpolate across a vast parameter space, predicting clustering statistics in milliseconds rather than months.
The pipeline involves:
- N-body simulations of dark matter clustering across a range of cosmological parameters
- Halo occupation distribution (HOD) modeling, a statistical recipe for deciding which dark matter halos are massive or concentrated enough to host a galaxy, and how many
- Forward modeling that translates theoretical predictions into telescope-observable signals
- Corrections for redshift-space distortions (how galaxies’ velocities smear their apparent distances along the line of sight) and the Alcock-Paczynski effect (geometric distortions from assuming the wrong cosmology)
- Emulators trained to predict both the standard two-point function and density-split statistics simultaneously
The galaxy sample, BOSS DR12 CMASS, covers roughly 650,000 massive galaxies at redshifts z ≈ 0.43–0.70 and is one of the richest datasets available for this kind of analysis. The team pushed measurements down to scales of just 1 h⁻¹ Mpc, deep into the regime where gravity creates messy, nonlinear structure but where their emulators remain accurate.
One important piece of the analysis was modeling assembly bias: whether galaxies’ tendency to occupy halos depends not just on halo mass but also on the surrounding environment. The team found genuine signatures. Galaxies prefer halos that are more concentrated or differently shaped depending on local density. It’s a subtle effect, but ignoring it would bias the cosmological results.
Why It Matters
The results land squarely in agreement with Planck 2018. The key numbers: ω_cdm = 0.1201 ± 0.0022 (cold dark matter density), σ_8 = 0.792 ± 0.034 (how clumpy matter is today), n_s = 0.970 ± 0.018 (the tilt of primordial fluctuations), and a growth rate fσ_8 = 0.462 ± 0.020 (how fast cosmic structure has been building). That agreement matters. The universe’s growth rate, as traced by these massive galaxies, is consistent with predictions from the CMB (the faint thermal glow left over from the Big Bang), easing some of the tensions that have dogged cosmology in recent years.
The team also tested whether any physics beyond standard ΛCDM (the current best model of the universe, built from ordinary matter, cold dark matter, and a constant dark energy) was hiding in the data. They varied the running of the spectral index, the dark energy equation of state, and the density of relic neutrinos. None showed statistically compelling deviations from the base model. A clean null result, but one that still puts meaningful constraints on exotic physics.
They validated their pipeline against mock catalogues 84 times larger than the actual CMASS volume and recovered unbiased constraints even at that scale. The next generation of galaxy surveys from DESI, Euclid, and the Vera Rubin Observatory will deliver exactly that kind of expanded dataset, and this methodology is ready for them.
Bottom Line: Density-split clustering, powered by machine-learning emulators, extracts cosmological information from scales and environments that traditional two-point analyses ignore. The technique is already validated for the much larger galaxy surveys arriving in the next decade.
IAIFI Research Highlights
This work ties together AI and cosmology by deploying neural network emulators, trained on N-body simulations, to perform Bayesian inference on one of the largest galaxy surveys ever assembled. A problem that would be computationally prohibitive with brute-force simulation becomes tractable through learned surrogate models.
The emulator framework demonstrates how machine learning can stand in for expensive forward simulations in high-dimensional parameter inference, an approach transferable to any field that depends on simulation-based analysis.
By probing galaxy clustering at nonlinear scales through environment-dependent statistics, the analysis delivers competitive constraints on dark matter density, the growth rate of cosmic structure, and extensions to ΛCDM including dark energy and neutrino physics.
With DESI and Euclid already collecting data, this pipeline, validated at 84× the CMASS volume, is positioned to sharpen cosmological constraints in the near future; the paper is available at [arXiv:2309.16541](https://arxiv.org/abs/2309.16541).