
Debiasing Guidance for Discrete Diffusion with Sequential Monte Carlo
Authors
Cheuk Kit Lee, Paul Jeha, Jes Frellsen, Pietro Lio, Michael Samuel Albergo, Francisco Vargas
Abstract
Discrete diffusion models are a class of generative models that produce samples from an approximated data distribution within a discrete state space. Often, there is a need to target specific regions of the data distribution. Current guidance methods aim to sample from a distribution with mass proportional to $p_0(x_0) p(ζ|x_0)^α$ but fail to achieve this in practice. We introduce a Sequential Monte Carlo algorithm that generates unbiasedly from this target distribution, utilising the learnt unconditional and guided process. We validate our approach on low-dimensional distributions, controlled images and text generations. For text generation, our method provides strong control while maintaining low perplexity compared to guidance-based approaches.
Concepts
The Big Picture
Imagine you’re trying to generate formal legal text. You tell an AI “be formal” and crank up the guidance dial. Instead of more formal text, you get garbled nonsense. The AI, steered too hard, falls off a cliff.
This is a recurring problem for discrete diffusion models — AI systems that generate text by starting with scrambled noise and gradually sculpting it into coherent language. Guidance is supposed to steer that sculpting process toward a desired outcome. In practice, it steers into a ditch.
The problem is mathematical. Standard guidance methods claim to sample from the target distribution — to draw outputs with exactly the right statistical profile — but fail to do so. Researchers at Cambridge, the Technical University of Denmark, and MIT’s IAIFI have now proven exactly why they fail, and fixed it.
Key Insight: Standard guidance for discrete diffusion models is provably biased — it cannot produce the intended target distribution except in one special case. A new Sequential Monte Carlo algorithm corrects this bias without any additional model training.
How It Works
Discrete diffusion uses Continuous-Time Markov Chains (CTMCs) — think of a particle that hops between states (say, different possible words at a position in text) over time, with hop rates engineered to reverse noise and produce coherent output. To condition generation on a desired property, researchers modify these rates using guidance. Amplifying guidance by a strength parameter α (alpha) should concentrate generated samples on text matching the conditioning signal.
It doesn’t. The paper’s core theorem makes this concrete: unless α equals exactly 1 (simple conditional generation, no amplification), the guided process samples from a distribution that only approximates the target, with errors that grow as α moves away from 1.
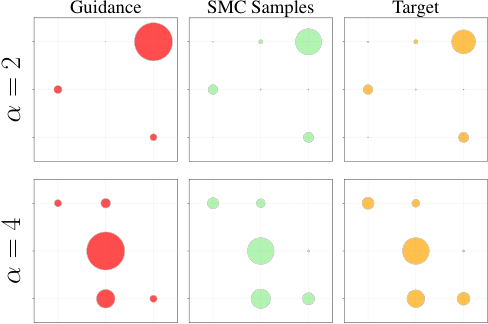
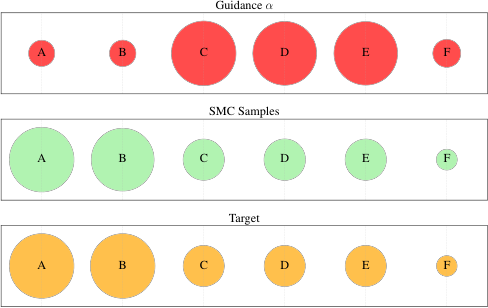
The orange circles above represent the true target distribution across six discrete states. Red circles (standard guidance) misplace probability mass, over-weighting some states and under-weighting others. The problem worsens with higher α.
The fix draws on Sequential Monte Carlo (SMC), a statistical technique for approximating complex distributions using a population of weighted “particles” that evolve over time:
- Run both processes simultaneously. Track particles that each combine information from the unconditional diffusion and the guidance signal.
- Compute importance weights. At each step, calculate how much each particle’s trajectory diverges from the true target and weight it accordingly.
- Resample to correct drift. Periodically discard particles that have drifted from the target and replace them with copies of better-weighted ones.
- No extra training required. The SMC correction works on top of any pre-trained discrete diffusion model, exploiting a previously ignored property: the guided rate matrix works as a proposal distribution even though it fails as a sampler.
The result (shown in green in Figure 1) closely matches the target distribution across all states.
The team validated their method across three domains. On low-dimensional toy distributions, SMC matched the theoretical target while standard guidance failed visibly. On image generation, the approach matched or exceeded classifier guidance at high α values without the image degradation that plagues standard methods, measured along the optimal tradeoff curve between sample quality and conditioning strength.
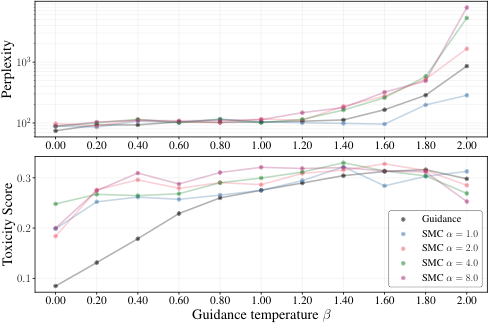
Text generation is where the stakes are highest. Language models operate over vocabularies of tens of thousands of individual text units (tokens), and steering coherent text toward a specific property — sentiment, topic, toxicity — is notoriously hard. The team tested sentiment-controlled generation, measuring perplexity (fluency) against sentiment accuracy.
Standard guidance at high α produced accurate sentiment but shredded fluency — perplexity skyrocketed as the model generated unnatural, repetitive text. SMC maintained strong sentiment control while keeping perplexity near the unconditional baseline, and compared favorably against finetuning-based approaches that require additional training.
Why It Matters
Discrete diffusion models are becoming important tools for text, protein design, molecule generation, and any domain where data lives in a structured discrete space. Reliably steering these models — not approximately, but with provable correctness — is foundational infrastructure for the whole field.
The SMC framework opens up applications requiring precise control without retraining costs. In drug discovery, a researcher might bias a molecule generator toward high solubility or low toxicity by increasing α. With standard guidance, pushing α too high produces chemically nonsensical outputs. With SMC, the generated distribution gets progressively closer to the correct target as you add more particles.
Open questions remain around computational cost — running many particles is more expensive than running one — and scaling to the largest language models. But even with a modest particle count, the gains in distribution accuracy are substantial. The theoretical foundation applies broadly: any discrete diffusion model, any conditioning signal, any α value.
Bottom Line: Guidance for discrete diffusion is broken by design — and this paper fixes it. Wrapping any pre-trained discrete diffusion model in a Sequential Monte Carlo correction produces conditioned samples that provably target the intended distribution, with dramatic improvements in text fluency at high guidance strengths.
IAIFI Research Highlights
This work connects statistical physics-inspired inference methods — Sequential Monte Carlo and Markov chain theory — to modern discrete generative AI, which is central to IAIFI's mission of bringing physics thinking to AI foundations.
The paper delivers the first provably unbiased guided sampling algorithm for discrete diffusion models, with demonstrated improvements in text sentiment control, image generation, and discrete molecular domains — without any additional model training.
The CTMC framework has direct parallels in statistical mechanics and lattice field theory; the corrected sampling methods could enable more reliable generative models for scientific data in discrete spaces such as protein sequences or lattice configurations.
Future work will focus on scaling SMC particle counts efficiently for large language models and extending the framework to conditional generation in scientific discovery tasks; the preprint is available at [arXiv:2502.06079](https://arxiv.org/abs/2502.06079).
Original Paper Details
Debiasing Guidance for Discrete Diffusion with Sequential Monte Carlo
2502.06079
["Cheuk Kit Lee", "Paul Jeha", "Jes Frellsen", "Pietro Lio", "Michael Samuel Albergo", "Francisco Vargas"]
Discrete diffusion models are a class of generative models that produce samples from an approximated data distribution within a discrete state space. Often, there is a need to target specific regions of the data distribution. Current guidance methods aim to sample from a distribution with mass proportional to $p_0(x_0) p(ζ|x_0)^α$ but fail to achieve this in practice. We introduce a Sequential Monte Carlo algorithm that generates unbiasedly from this target distribution, utilising the learnt unconditional and guided process. We validate our approach on low-dimensional distributions, controlled images and text generations. For text generation, our method provides strong control while maintaining low perplexity compared to guidance-based approaches.