
Decomposing The Dark Matter of Sparse Autoencoders
Authors
Joshua Engels, Logan Riggs, Max Tegmark
Abstract
Sparse autoencoders (SAEs) are a promising technique for decomposing language model activations into interpretable linear features. However, current SAEs fall short of completely explaining model performance, resulting in "dark matter": unexplained variance in activations. This work investigates dark matter as an object of study in its own right. Surprisingly, we find that much of SAE dark matter -- about half of the error vector itself and >90% of its norm -- can be linearly predicted from the initial activation vector. Additionally, we find that the scaling behavior of SAE error norms at a per token level is remarkably predictable: larger SAEs mostly struggle to reconstruct the same contexts as smaller SAEs. We build on the linear representation hypothesis to propose models of activations that might lead to these observations. These insights imply that the part of the SAE error vector that cannot be linearly predicted ("nonlinear" error) might be fundamentally different from the linearly predictable component. To validate this hypothesis, we empirically analyze nonlinear SAE error and show that 1) it contains fewer not yet learned features, 2) SAEs trained on it are quantitatively worse, and 3) it is responsible for a proportional amount of the downstream increase in cross entropy loss when SAE activations are inserted into the model. Finally, we examine two methods to reduce nonlinear SAE error: inference time gradient pursuit, which leads to a very slight decrease in nonlinear error, and linear transformations from earlier layer SAE outputs, which leads to a larger reduction.
Concepts
The Big Picture
Imagine you’re trying to understand a symphony by identifying individual instruments. A violin here, a trumpet there, piece by piece, you reconstruct the full sound. Sparse autoencoders (SAEs) work something like this: they break apart the internal calculations of large language models into individual “features,” each corresponding to a recognizable concept, fact, or grammatical pattern the model has learned. The dream is total decomposition. Understand every note, and you understand the orchestra.
But there’s a problem. No matter how many features you find, something always escapes explanation. Researchers at MIT and IAIFI have started calling it dark matter, a term borrowed from cosmology, where it names the invisible stuff that accounts for most of the universe’s mass while stubbornly resisting direct observation.
In the SAE world, dark matter is the leftover gap: the difference between what the tool reconstructs and what the model actually computed. It’s not small. And until now, nobody had looked at it closely.
A new paper by Joshua Engels, Logan Riggs, and Max Tegmark treats this unexplained residual not as noise to minimize but as a scientific object worth studying on its own terms. What they find is surprising: dark matter has hidden structure, and that structure tells us something deep about how language models represent knowledge.
Key Insight: About half of the SAE error vector, and more than 90% of its magnitude, can be predicted with a simple linear transformation of the original model activation. This suggests “dark matter” isn’t random noise but a structured, partially recoverable quantity.
How It Works
The starting point is the linear representation hypothesis (LRH): the idea that a language model’s internal states encode meaning as sparse combinations of linear directions. Think of each direction as a dial in a vast mixing board. Information gets stored by turning a few dials up or down. SAEs are the main tool for finding which dials are active.
They work by taking a model’s internal state at a given processing step, squeezing it through a compression layer, and reconstructing it as a weighted sum of learned “dictionary” features. The error (the difference between the original state and the reconstruction) is what the researchers call dark matter.
The team’s first move was to ask: how much of this error is predictable? They trained a linear probe, a simple mathematical function with no hidden layers, to predict the SAE error directly from the model’s original internal state. A linear transformation of the input explained roughly half the variance in the error vector and over 90% of the error’s norm, meaning the overall magnitude of the mistake is almost entirely foreseeable before the SAE even runs. The result surprised even the authors.
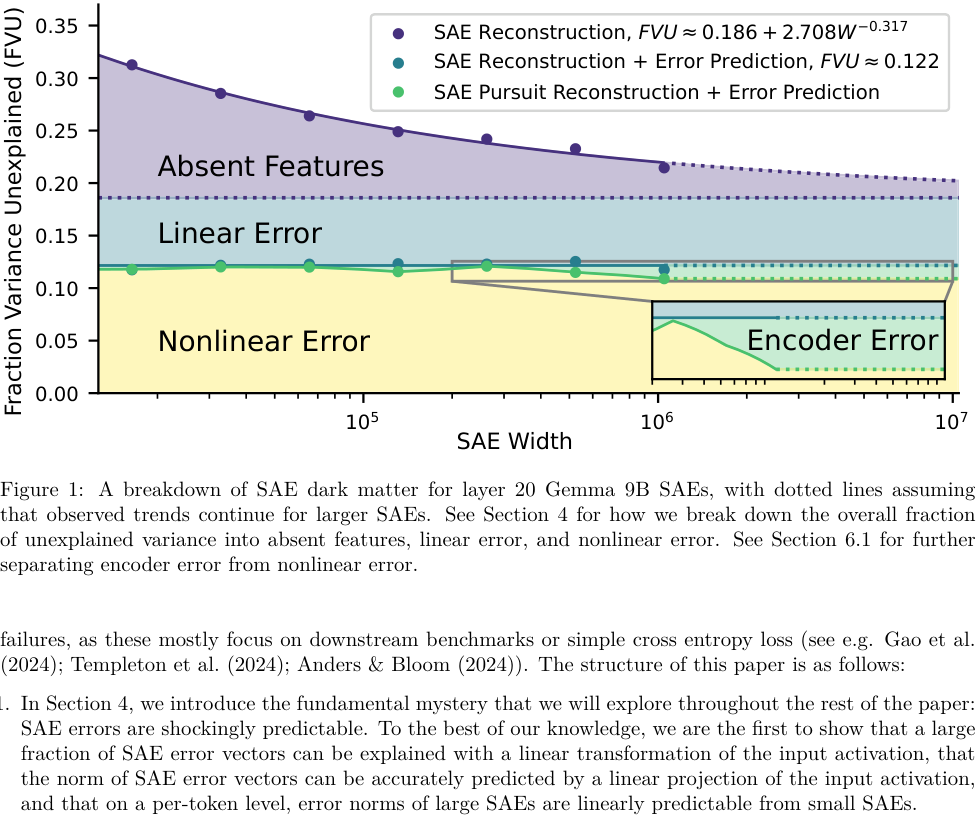
This led them to carve dark matter into two fundamentally different pieces:
- Linear error: the predictable component, what a linear function of the input activation can anticipate. This likely consists of features the SAE hasn’t yet learned but which are in principle within its reach.
- Nonlinear error: the residual after removing the linear component, what no linear function of the input can predict. This is the deeper mystery.
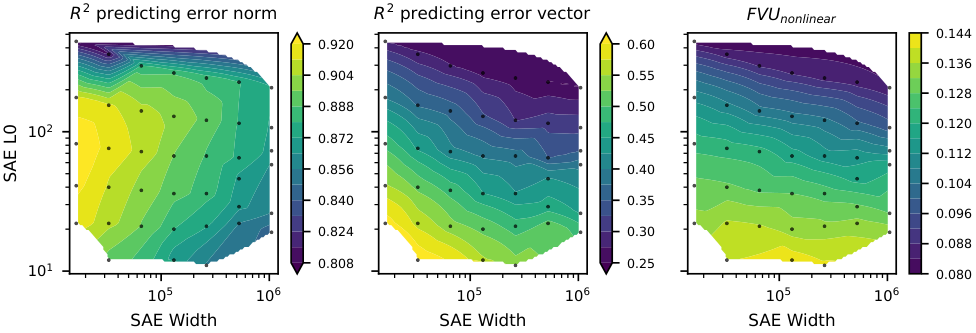
The team also found that SAE errors scale in a regular way. When you train larger SAEs, you’d hope they’d gradually fix mistakes across the board. Instead, errors are consistent: larger SAEs fail on the same contexts where smaller ones fail. Dark matter concentrates on specific, hard cases that even a much bigger SAE can’t crack.
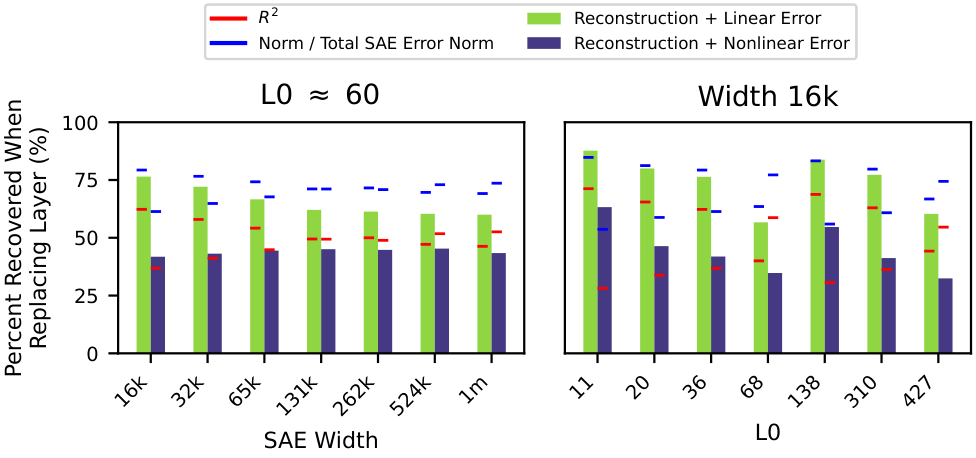
To test whether nonlinear error is qualitatively different from linear error, or just quantitatively harder, the researchers ran a battery of experiments. The answer came back clearly: qualitatively different.
- Fewer unlearned features: A second SAE trained on the nonlinear error alone performed measurably worse than one trained on the linear error, suggesting the nonlinear residual contains fewer learnable linear features.
- Harder to learn: SAEs trained on nonlinear error achieve worse reconstruction quality. It isn’t just a smaller version of the same problem.
- Proportional downstream harm: Nonlinear error degrades language modeling performance in direct proportion to its norm, while the linear component behaves differently.
So SAE dark matter has two layers. The outer layer (linear error) is large but tractable, representing features the SAE hasn’t found yet. Scaling up will eventually help. The inner core (nonlinear error) may reflect components that simply don’t fit the linear feature model: Gaussian noise, circular representations, or other non-sparse structures that no number of dictionary features will capture.
The team tested two strategies for attacking nonlinear error. Inference-time gradient pursuit optimizes feature activations at test time rather than just running the encoder forward; it produced only a small reduction. Linear transformations from earlier layers worked better. Using SAE outputs from a previous layer to predict the current layer’s error shaved off a more meaningful chunk by exploiting predictable structure in how representations evolve across layers.
Why It Matters
For mechanistic interpretability, this is a sobering result, but also a clarifying one. There is a fundamental ceiling on what SAEs can explain, and it’s not just an engineering problem that more compute will fix. The nonlinear core may be genuinely beyond the reach of current feature-finding approaches. Understanding its nature (noise? dense representations? something else?) is now a concrete research target rather than a vague worry.
For AI alignment, the stakes are real. SAEs are one of the primary tools researchers use to peer inside large language models. If a substantial fraction of what models compute lives in an explanation-resistant residual, that gap could matter for safety-relevant questions about model behavior. The finding that linear and nonlinear error have different downstream effects on loss also means that not all unexplained variance is equally important to explain.
Open questions remain. What generates nonlinear error: is it a property of how transformers are trained, or inherent to the information they encode? Can novel SAE architectures attack the nonlinear component directly? And can the layer-to-layer prediction trick scale into a practical tool for dramatically reducing dark matter?
Bottom Line: SAE dark matter isn’t monolithic. It splits into a large, learnable linear component and a smaller, resistant nonlinear core that behaves fundamentally differently. This reframes interpretability research: the path forward requires not just bigger SAEs, but new tools designed specifically for what linear methods leave behind.
IAIFI Research Highlights
This work imports the metaphor and methodology of dark matter physics into AI interpretability, using structured decomposition (a staple of physical modeling) to reveal hidden organization in neural network residuals.
The paper shows that SAE reconstruction error is not random noise but a structured quantity with two qualitatively distinct components, changing how interpretability researchers should think about SAE limitations and scaling.
Max Tegmark's involvement continues IAIFI's mission of applying physics-inspired thinking to AI foundations, with the linear representation hypothesis treated as a physical model whose failures carry diagnostic information.
Future work may develop architectures that target nonlinear error specifically or use multi-layer SAE pipelines to progressively reduce unexplained variance. The paper is published in *Transactions on Machine Learning Research* (04/2025) and available as [arXiv:2410.14670](https://arxiv.org/abs/2410.14670).