
Deep Set Auto Encoders for Anomaly Detection in Particle Physics
Authors
Bryan Ostdiek
Abstract
There is an increased interest in model agnostic search strategies for physics beyond the standard model at the Large Hadron Collider. We introduce a Deep Set Variational Autoencoder and present results on the Dark Machines Anomaly Score Challenge. We find that the method attains the best anomaly detection ability when there is no decoding step for the network, and the anomaly score is based solely on the representation within the encoded latent space. This method was one of the top-performing models in the Dark Machines Challenge, both for the open data sets as well as the blinded data sets.
Concepts
The Big Picture
Imagine you’re a customs agent at the world’s busiest border crossing, tasked with flagging suspicious cargo, but nobody tells you what contraband looks like. All you can do is study “normal,” then flag anything that deviates. Scale that up by a billion, swap the cargo for subatomic particles, and you have the challenge physicists face at the Large Hadron Collider.
The LHC has spent over a decade smashing protons together and cataloging the debris. Theorists have proposed dozens of exotic particles that could appear: dark matter candidates, heavy partner particles, unknown forces. None have been found. Either new physics is hiding somewhere unexpected, or the models are wrong.
That uncomfortable situation has pushed physicists toward a different strategy: forget specific theories, and build detectors that can flag anything unusual, even if you don’t know what you’re looking for.
Bryan Ostdiek at Harvard’s IAIFI developed a powerful tool for exactly this challenge: a Deep Set Variational Autoencoder, a neural network trained to recognize when a collision event doesn’t fit the pattern of ordinary particle physics. It took top honors in a major international benchmark. The surprising twist? The method works best when you throw away half the network entirely.
Key Insight: The best way to spot anomalous particle collisions isn’t to reconstruct what you saw. It’s to ask how well the event compresses into a simple, well-behaved mathematical shape. Events that resist compression are suspicious.
How It Works
Particle physics experiments don’t record individual quarks. They record reconstructed objects: jets of particles, electrons, muons, photons, each described by energy and direction. An event might contain anywhere from a few to twenty such objects. The crucial observation: these objects form a set, not a sequence. There’s no meaningful “first” or “second” particle.
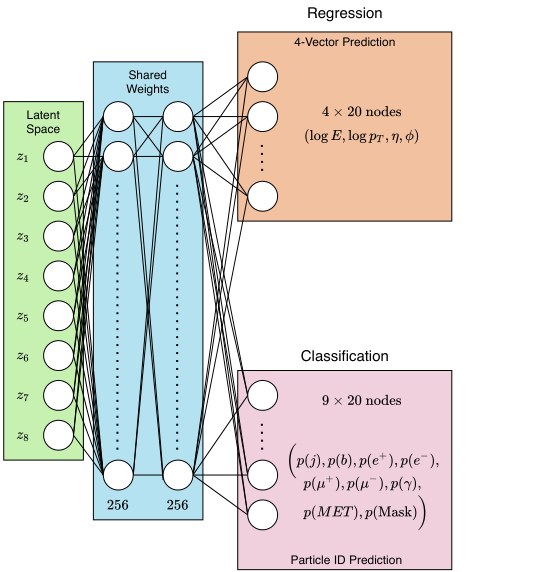
Traditional neural networks struggle with unordered inputs. Ostdiek builds on Particle Flow Networks, architectures designed for exactly this problem. The method works in two stages:
- A shared neural network (Φ) processes each particle independently, mapping it to a latent vector, a compact numerical fingerprint.
- All fingerprints get summed across the set, producing a permutation-invariant summary of the entire event. Order doesn’t matter.
This combined summary feeds into a variational layer, which encodes the event not as a single point in latent space but as a Gaussian probability distribution. Training pushes all Standard Model events toward a common, well-organized region. The anomaly score follows naturally: events that don’t compress into this Gaussian structure get flagged.
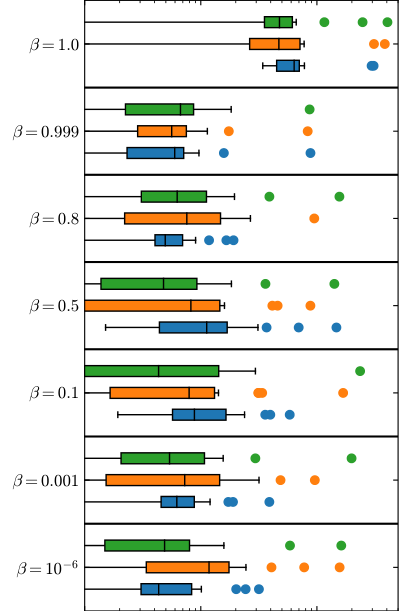
The full model includes a decoder that reconstructs the original particle set using a Chamfer loss, a distance measure for unordered sets. A single parameter, β, controls how much training cares about reconstruction versus latent structure:
- β = 0: Only reconstruction matters. The network works hard to rebuild each event.
- β = 1: Only latent structure matters. The network maps events to a Gaussian and nothing more.
- Best performance: β = 1, meaning the decoder is completely irrelevant.
At β = 1, you don’t need a decoder at all. The method reduces to a pure encoder asking one question: how well does this event fit the Gaussian? Standard Model events, trained to fit that shape, compress easily. New physics (unusual particle multiplicities, unexpected energy distributions, exotic combinations) resists.
Ostdiek tested the approach on the Dark Machines Anomaly Score Challenge, a rigorous benchmark with over one billion simulated proton-proton collisions at 13 TeV, drawn from 26 Standard Model processes. The challenge included four search channels: a hadronic channel with missing energy, two leptonic channels, and a high-activity inclusive channel. Eleven exotic physics scenarios covered dark matter candidates and two variants of supersymmetry (a theoretical framework predicting heavier partner particles for every known particle), spanning 18 different mass spectra. Signals were initially blinded, so methods had to perform without knowing what was hidden in the test data.
The Deep Set VAE with β = 1 ranked among the top-performing methods on both open and blinded datasets. It was particularly strong at flagging individual anomalous events, a harder task than finding statistical bumps in aggregate distributions.
The other top methods shared a common theme: all used “fixed target” approaches, either mapping events to a Gaussian or to a single fixed vector. Methods that tried to reconstruct their inputs consistently underperformed. One hypothesis: reconstruction forces the network to memorize event details rather than learn the deep structure of what’s “normal.”
Why It Matters
Model-agnostic anomaly detection is becoming essential for the LHC’s future. The final datasets will accumulate through the 2030s, and tools like this one improve the odds of catching something genuinely new, even if it matches no existing theoretical prediction.
The deep sets framework also points toward a useful architectural lesson. By respecting the natural symmetry of the data (the permutation invariance of particle sets) the network learns more efficiently and generalizes better than approaches that impose artificial ordering on the particles.
The finding that “learn a good encoding” outperforms “reconstruct the input” may carry implications well beyond collider physics. The same principle applies wherever data arrives as unordered collections: molecular modeling, 3D point cloud analysis, social network graphs. Whether the decoder half of an autoencoder actually earns its keep is a question worth revisiting across these fields.
Bottom Line: By treating particle collision events as mathematical sets and optimizing purely for compact latent representations, Ostdiek’s Deep Set VAE achieved top-tier anomaly detection in a major international challenge and revealed that the decoder half of an autoencoder may be hurting more than it helps.
IAIFI Research Highlights
This work connects modern deep learning (deep set networks and variational autoencoders) with particle physics search strategies, producing a principled, physics-motivated tool for model-agnostic BSM detection at the LHC.
The finding that β = 1 (encoding without reconstruction) outperforms full autoencoders runs counter to standard assumptions about autoencoder design and raises real questions about what information is actually useful for anomaly detection.
The method provides a competitive, theory-agnostic tool for flagging exotic physics events at the LHC without requiring any prior model of new physics, widening what the collider program can discover beyond targeted searches alone.
Future work should investigate why fixed-target encoding consistently outperforms reconstruction-based approaches and whether these techniques extend to the High-Luminosity LHC era; the full paper is available at [arXiv:2109.01695](https://arxiv.org/abs/2109.01695).