
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Authors
Yung-Sung Chuang, Rumen Dangovski, Hongyin Luo, Yang Zhang, Shiyu Chang, Marin Soljačić, Shang-Wen Li, Wen-tau Yih, Yoon Kim, James Glass
Abstract
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
Concepts
The Big Picture
Imagine trying to teach a student the meaning of words by only showing them synonyms, never pointing out what makes words different. You’d end up with someone who knows “happy” and “joyful” are similar but can’t explain why “happy” and “ecstatic” aren’t the same thing. For years, the dominant approach to teaching AI how language works had exactly this limitation.
At the heart of how AI systems understand language is a technique called sentence embedding: converting a sentence into a list of numbers that captures its meaning in a form computers can compare and work with. Doing this well without labeled data, without human annotations or task-specific examples, is the central challenge.
One popular training strategy shows a model two slightly different versions of the same sentence and teaches it to recognize those as more similar to each other than to unrelated sentences. “The cat sat on the mat” and “A cat was sitting on the mat” should land close together, while “Inflation rates rose sharply” should be far away. For images, this works beautifully: slightly rotating or cropping a photo doesn’t change what’s in it. For text, the same logic is treacherous. Swap out a single word, and you might change the meaning entirely.
So researchers learned to avoid meaning-altering transformations altogether. A team from MIT, Meta AI, MIT-IBM Watson AI Lab, and UC Santa Barbara thought the field was leaving valuable signal on the table. Rather than ignoring text changes that alter meaning, they built a method that explicitly learns from those changes, achieving state-of-the-art performance on semantic similarity benchmarks without any labeled data.
Key Insight: Instead of teaching a model only what sentences have in common, DiffCSE also teaches it to detect what changed, making the resulting embeddings richer, more precise, and dramatically better at capturing meaning.
How It Works
DiffCSE borrows a concept from physics: equivariance. A function is equivariant to a transformation if applying that transformation to the input produces a predictable, structured change in the output. Not necessarily no change (that would be invariance), but a trackable one. Previous contrastive learning methods aimed purely for invariance: train the model so that small, safe perturbations don’t change the embedding. DiffCSE asks a more nuanced question. What if some transformations should change the embedding, and we can learn from that?
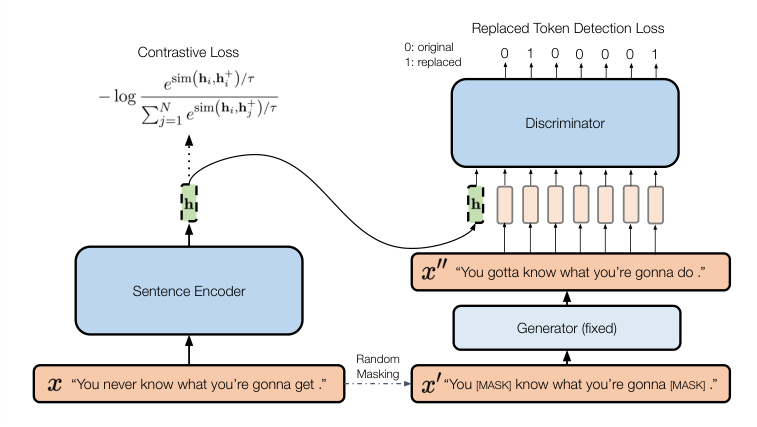
The framework runs in two parallel streams. On one side sits a standard SimCSE-style contrastive learner, the previous leading approach for unsupervised sentence embeddings. Take a sentence, run it through an encoder network twice with slightly different random noise applied (a technique called dropout), and train the model to recognize those two noisy versions as more similar to each other than any other sentence in the batch. Dropout is the “insensitive” transformation: it introduces noise without changing meaning, so the model learns invariance to it.
On the other side sits something new: a conditional discriminator. Modeled after the ELECTRA architecture, this network takes the sentence embedding plus an aggressively edited version of the sentence and predicts, token by token, which words were changed.
The editing process is the key ingredient:
- Take the original sentence and randomly mask 15% of its tokens.
- Feed those masked positions to a pre-trained masked language model (BERT) to generate replacement words.
- The result is a grammatically plausible sentence that may differ subtly, or substantially, in meaning from the original.
- The discriminator receives the sentence embedding h and the edited sentence, then predicts a binary label for each token: original or replaced?
This setup forces the encoder to produce embeddings that carry information about specific word choices, not just general topic or syntactic structure. If the embedding were vague, the discriminator couldn’t do its job. The encoder is rewarded for being sensitive to the lexical changes that matter for meaning.
During inference, the discriminator is thrown away. Only the sentence embedding h is used, clean and compact, now attuned to semantic precision.
Why It Matters
The gains here are large given how small the architectural change looks. On seven standard Semantic Textual Similarity (STS) benchmarks, which measure how well embeddings capture human judgments of sentence similarity, DiffCSE outperforms unsupervised SimCSE by 2.3 absolute percentage points. On STS-B, one of the most widely used benchmarks, DiffCSE achieves a Spearman correlation of 86.4 compared to SimCSE’s 84.2.
In a field where progress is often measured in decimal points, 2.3 points is a real jump. The improvement holds across both BERT-base and RoBERTa-base backbone models, which suggests the technique is model-agnostic rather than a lucky fit with one particular architecture.
Ablation studies confirm that both components are necessary. Remove the discriminator, and you’re back to SimCSE. Remove the contrastive loss, and performance collapses. The two objectives are genuinely complementary: one teaches invariance to noise, the other teaches sensitivity to meaning.
Sentence embeddings power semantic search, question answering, document retrieval, and a growing ecosystem of applications where machines must reason about meaning at scale. Better embeddings mean better search results, more accurate similarity matching, and richer representations for downstream models.
DiffCSE also validates a broader principle: equivariance, a concept that physicists use to reason about symmetry and conservation laws, translates directly into better machine learning. The idea that “some transformations should be tracked, not ignored” is general enough to reshape how self-supervised learning objectives are designed across modalities.
Bottom Line: DiffCSE achieves a 2.3-point improvement over the previous state-of-the-art in unsupervised sentence representation learning by teaching models to notice what changed, a simple reframing of how contrastive learning should handle meaning-altering transformations.
IAIFI Research Highlights
This work applies the mathematical concept of equivariance, central to physics and the study of symmetry, to improve how AI systems learn language representations. It is a concrete example of theoretical physics intuitions informing NLP engineering.
DiffCSE sets a new state-of-the-art for unsupervised sentence embeddings, outperforming SimCSE by 2.3 absolute points on STS benchmarks and offering a principled framework for designing augmentation strategies in contrastive learning.
The work formalizes and validates equivariant contrastive learning in the NLP domain, showing that the invariance/equivariance distinction, rooted in group theory and physics, governs which data transformations help or hurt representation learning.
Future directions include extending equivariant contrastive learning to other modalities and exploring learned rather than hand-designed sensitive transformations; the full paper and pretrained models are available at [arXiv:2204.10298](https://arxiv.org/abs/2204.10298).