
Diffusion Autoencoders with Perceivers for Long, Irregular and Multimodal Astronomical Sequences
Authors
Yunyi Shen, Alexander Gagliano
Abstract
Self-supervised learning has become a central strategy for representation learning, but the majority of architectures used for encoding data have only been validated on regularly-sampled inputs such as images, audios. and videos. In many scientific domains, data instead arrive as long, irregular, and multimodal sequences. To extract semantic information from these data, we introduce the Diffusion Autoencoder with Perceivers (daep). daep tokenizes heterogeneous measurements, compresses them with a Perceiver encoder, and reconstructs them with a Perceiver-IO diffusion decoder, enabling scalable learning in diverse data settings. To benchmark the daep architecture, we adapt the masked autoencoder to a Perceiver encoder/decoder design, and establish a strong baseline (maep) in the same architectural family as daep. Across diverse spectroscopic and photometric astronomical datasets, daep achieves lower reconstruction errors, produces more discriminative latent spaces, and better preserves fine-scale structure than both VAE and maep baselines. These results establish daep as an effective framework for scientific domains where data arrives as irregular, heterogeneous sequences.
Concepts
The Big Picture
Imagine trying to teach a child to recognize animals, but the photos you hand them are taken at random times, from random angles, in random lighting, and sometimes what you hand them isn’t a photo at all but a sound recording or a thermometer reading. That’s roughly the challenge facing astronomers who want AI to make sense of their data. Telescopes don’t observe on neat schedules. Clouds roll in. Instruments switch targets. A supernova might be photographed ten times in one week, then not at all for two months.
The result is data that’s long, patchy, and bundled across wildly different measurement types: light curves from one instrument, spectra from another, timestamps scattered throughout. Most modern AI tools are built for tidier worlds. Image models expect data on regular grids, pixels in neat rows and columns, audio sampled at a fixed rate. Forcing these tools onto messier scientific data is like fitting a square peg into a round hole.
A team from MIT and Harvard has built the right-shaped peg. Their new system, DAEP (Diffusion AutoEncoder with Perceivers), learns compact, meaningful summaries directly from long, irregular, mixed-measurement astronomical sequences, without requiring the data to be cleaned up first.
Key Insight: DAEP combines a flexible Perceiver encoder with a diffusion-based decoder to learn from messy, real-world astronomical data in its native form, outperforming existing methods at reconstructing fine-grained structure and organizing the internal summaries it builds from each observation.
How It Works
DAEP solves three problems simultaneously: handling variable-length inputs, compressing them into a meaningful representation, and reconstructing the originals faithfully. It does this by chaining two powerful ideas from modern deep learning.
The pipeline works in three stages:
- Tokenization — Each data point is converted into a unified format encoding its position (wavelength or timestamp), value, and uncertainty. A galaxy spectrum and a supernova light curve become a single coherent input stream, regardless of the instrument that produced them.
- Perceiver encoding — Unlike standard transformers, whose processing costs balloon with sequence length, the Perceiver encoder uses a fixed set of learned “latent queries” to scan the input selectively. A 10,000-point spectrum and a sparse 200-point light curve require roughly the same compute to process. The encoder compresses everything into a fixed-size latent vector, a fingerprint capturing the essential character of the sequence. Two supernovae of the same type should produce similar fingerprints even if observed on different nights with different instruments.
- Diffusion decoding — Instead of a standard decoder, DAEP uses a diffusion decoder (the same class of model powering today’s image generators). Starting from pure noise, it iteratively refines toward the target, guided at every step by the latent vector. This steered denoising recovers fine-grained detail that simpler decoders typically blur.
To isolate the value of diffusion, the authors also built MAEP (Masked AutoEncoder with Perceivers): the same Perceiver backbone, but trained to predict masked-out portions of the input without any human-labeled examples. It’s a self-supervised approach with the same architecture but a different learning strategy. The comparison is deliberately apples-to-apples.
Why It Matters
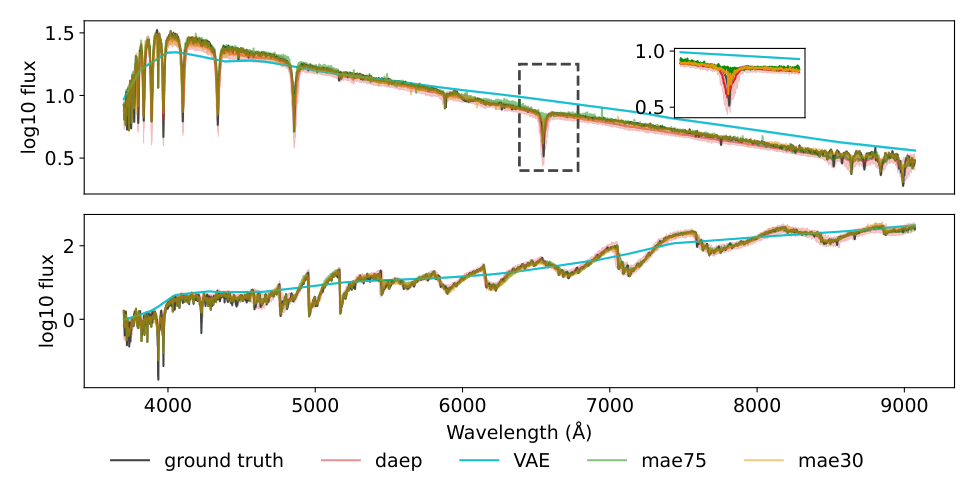
Tested on spectroscopic datasets (galaxy spectra from SDSS and DESI) and photometric datasets (supernova light curves from ZTF and ATLAS), DAEP consistently beats the baselines. It achieves lower reconstruction error than both the VAE (Variational Autoencoder, a standard AI compression approach) and MAEP. The most striking gains show up on high-frequency features: sharp emission lines in spectra, rapid brightness changes in transient events. These are exactly the details that smoother decoders tend to smear over. DAEP’s internal summaries are also more discriminative, meaning similar objects cluster together more tightly, which matters when downstream tasks involve classifying galaxy types or flagging rare transients.
The design isn’t limited to astronomy. The authors built DAEP for any domain where data arrives as long, messy, mixed-type sequences: irregularly sampled patient health records, financial time series with gaps, sensor networks that report only when something interesting happens. The architecture doesn’t need clean inputs to extract clean knowledge.
The bigger goal here is AI that works with data as it actually exists, not data reshaped into formats that existing systems happen to prefer. DAEP is a concrete step toward that.
Bottom Line: DAEP delivers better reconstructions and more structured representations than existing methods on real astronomical data, with a design that transfers naturally to any scientific domain where messy, irregular, multimodal sequences are the norm.
IAIFI Research Highlights
This work applies advances in deep generative modeling, specifically diffusion autoencoders and Perceiver architectures, to the practical challenge of extracting science from large, heterogeneous astronomical surveys including ZTF, ATLAS, SDSS, and DESI.
DAEP extends diffusion autoencoders beyond regular-grid modalities, establishing a scalable framework for self-supervised representation learning on long, irregular, and multimodal sequences, a setting largely unaddressed by existing methods.
Better representations of spectra and light curves directly accelerate classification of transient phenomena, galaxy characterization, and multi-modal data fusion across the next generation of large astronomical surveys.
Future work could extend DAEP to fully multimodal training at scale across simultaneous spectroscopic and photometric survey data; the paper is available at [arXiv:2510.20595](https://arxiv.org/abs/2510.20595).
Original Paper Details
Diffusion Autoencoders with Perceivers for Long, Irregular and Multimodal Astronomical Sequences
2510.20595
["Yunyi Shen", "Alexander Gagliano"]
Self-supervised learning has become a central strategy for representation learning, but the majority of architectures used for encoding data have only been validated on regularly-sampled inputs such as images, audios. and videos. In many scientific domains, data instead arrive as long, irregular, and multimodal sequences. To extract semantic information from these data, we introduce the Diffusion Autoencoder with Perceivers (daep). daep tokenizes heterogeneous measurements, compresses them with a Perceiver encoder, and reconstructs them with a Perceiver-IO diffusion decoder, enabling scalable learning in diverse data settings. To benchmark the daep architecture, we adapt the masked autoencoder to a Perceiver encoder/decoder design, and establish a strong baseline (maep) in the same architectural family as daep. Across diverse spectroscopic and photometric astronomical datasets, daep achieves lower reconstruction errors, produces more discriminative latent spaces, and better preserves fine-scale structure than both VAE and maep baselines. These results establish daep as an effective framework for scientific domains where data arrives as irregular, heterogeneous sequences.