
Does SGD Seek Flatness or Sharpness? An Exactly Solvable Model
Authors
Yizhou Xu, Pierfrancesco Beneventano, Isaac Chuang, Liu Ziyin
Abstract
A large body of theory and empirical work hypothesizes a connection between the flatness of a neural network's loss landscape during training and its performance. However, there have been conceptually opposite pieces of evidence regarding when SGD prefers flatter or sharper solutions during training. In this work, we partially but causally clarify the flatness-seeking behavior of SGD by identifying and exactly solving an analytically solvable model that exhibits both flattening and sharpening behavior during training. In this model, the SGD training has no \textit{a priori} preference for flatness, but only a preference for minimal gradient fluctuations. This leads to the insight that, at least within this model, it is data distribution that uniquely determines the sharpness at convergence, and that a flat minimum is preferred if and only if the noise in the labels is isotropic across all output dimensions. When the noise in the labels is anisotropic, the model instead prefers sharpness and can converge to an arbitrarily sharp solution, depending on the imbalance in the noise in the labels spectrum. We reproduce this key insight in controlled settings with different model architectures such as MLP, RNN, and transformers.
Concepts
The Big Picture
Imagine you’re hiking through mountains, looking for the lowest valley. But the terrain is strange: dozens of valleys all sit at exactly the same depth. Do you wander into a wide, gentle bowl, or a narrow, knife-edge trench? The valley you end up in could determine how well you survive the next earthquake. In machine learning terms, it determines how well your model generalizes to new data.
This question sits at the center of one of deep learning’s most contentious debates. When you train a neural network, the algorithm makes tiny adjustments to millions of numerical settings, searching for configurations that produce fewer errors. The standard tool is stochastic gradient descent (SGD), which uses random subsets of the training data rather than the whole dataset at once, navigating what researchers call a loss landscape: a mathematical terrain where every point represents a different network configuration and the elevation represents how many errors it makes.
For decades, researchers believed SGD has an innate preference for “flat” minima: wide valleys where the loss barely changes even if you nudge the network’s parameters. Flat regions, the intuition goes, are more robust and generalize better.
But empirical evidence kept undermining that story. Modern large models routinely converge to “sharp” minima, narrow steep troughs, and work just fine. So which is it?
A new paper from researchers at MIT and EPFL cuts through the confusion with a rare weapon in theoretical machine learning: an exactly solvable model that can exhibit both behaviors, and a precise mathematical answer for when each occurs.
Key Insight: SGD has no inherent preference for flatness. Instead, it minimizes gradient fluctuations, and whether that produces a flat or sharp minimum depends entirely on the geometry of the noise in your training labels.
How It Works
The team’s starting point is a theoretical result gaining traction in recent years: SGD naturally gravitates toward solutions with small gradient fluctuations, solutions where the gradient (the error signal used to update the network) doesn’t jump around much from one mini-batch to the next. This “minimal-fluctuation” principle is subtly different from seeking flat minima. Flatness, measured by the Hessian (a matrix capturing how steeply the landscape curves in every direction), and gradient fluctuation sound similar but are not the same thing. They align only under special conditions.
To isolate exactly when they diverge, the researchers constructed a mathematically exact test case: a deep linear network (multiple matrix layers chained together) trained on data from a linear teacher, a simple known model used to generate artificial training examples, with noisy labels. Simple enough to solve with exact formulas, yet rich enough to show nontrivial sharpness behavior.
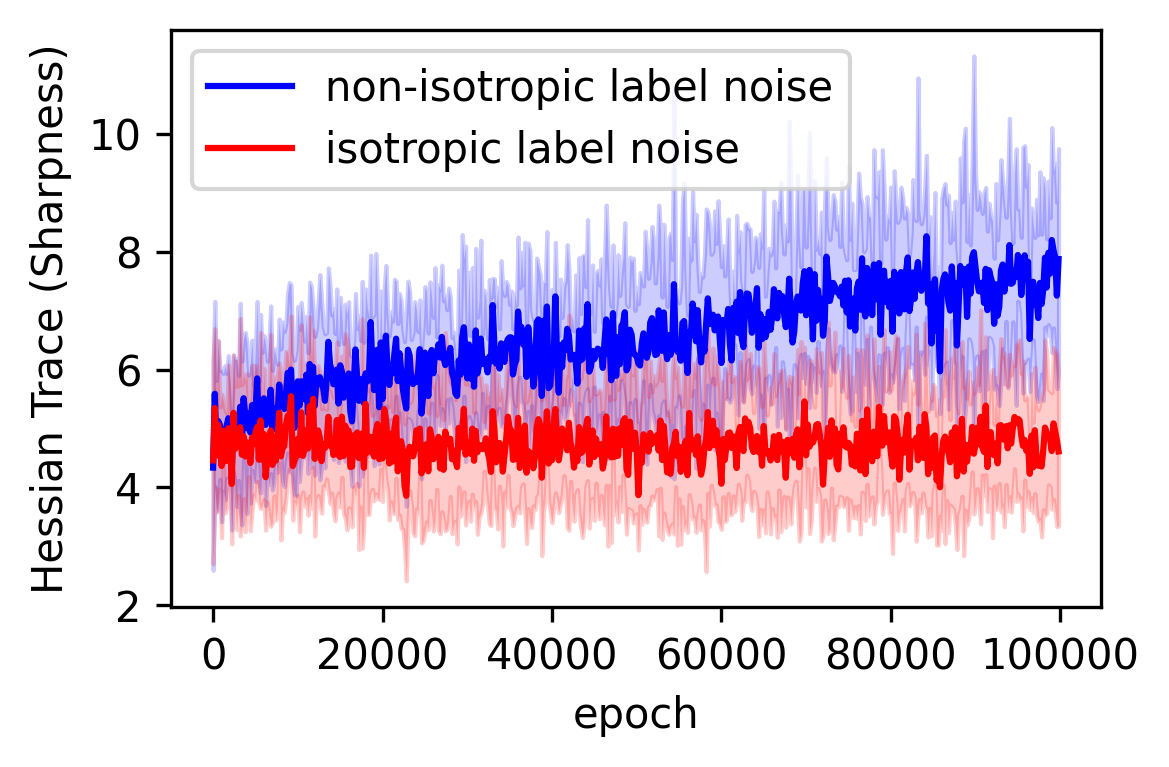
Even when networks start at wildly different sharpness levels, they converge to the same sharpness value, a unique fixed point that doesn’t depend on initialization. This is exactly what you want from a theory: clean predictions, not noisy trajectories muddied by starting conditions.
The controlling variable turns out to be label noise anisotropy, how evenly noise is distributed across different output dimensions:
- Isotropic label noise (noise spread evenly across all output dimensions): SGD converges to the flattest possible solution among all equally good minima.
- Anisotropic label noise (noise concentrated in some dimensions more than others): SGD converges to a sharper solution, and the sharpness scales with the imbalance. Extreme imbalance can push the model to arbitrarily sharp solutions.
The sharpness at convergence is a precise function of the input data covariance, the teacher’s structure, network depth, and the label noise covariance matrix (which captures exactly how noise is distributed across output dimensions). Not an approximation. An exact formula.
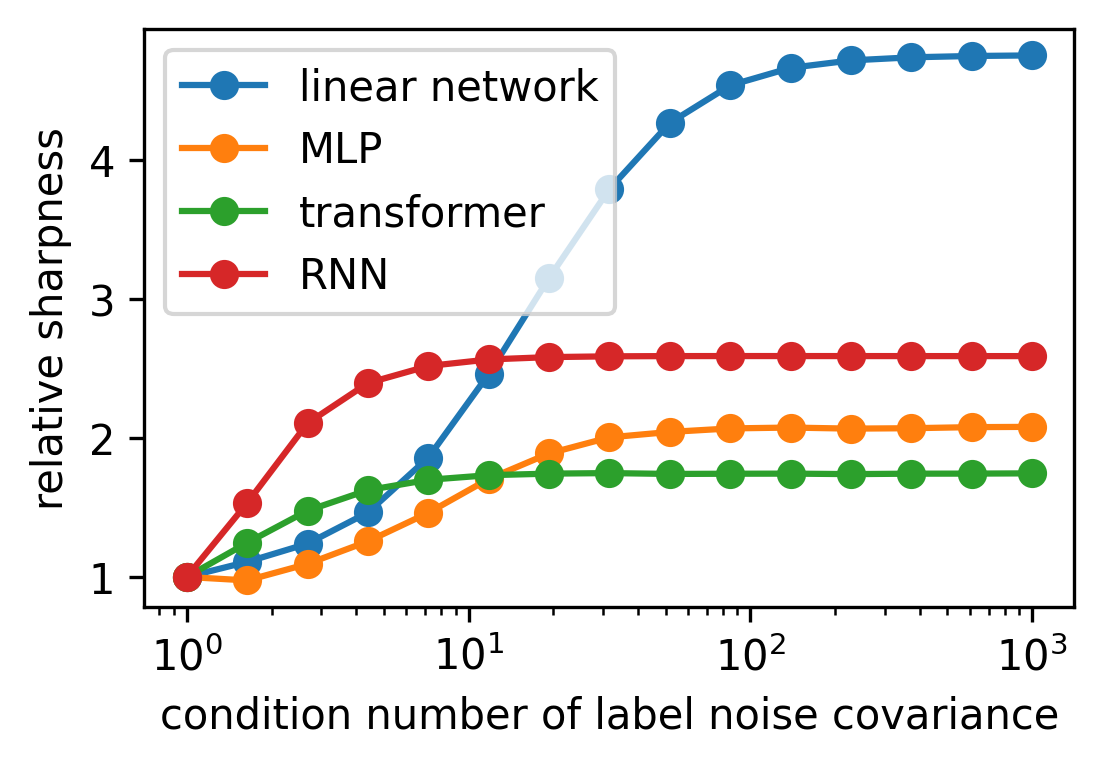
The team then tested whether this insight survives contact with more realistic models. They ran controlled experiments on MLPs, RNNs, and transformers, architectures far more complex than deep linear networks. In each case, tuning the anisotropy of label noise shifted the converged sharpness in the direction the theory predicted. Isotropic noise pushed toward flat solutions; anisotropic noise pushed toward sharp ones.
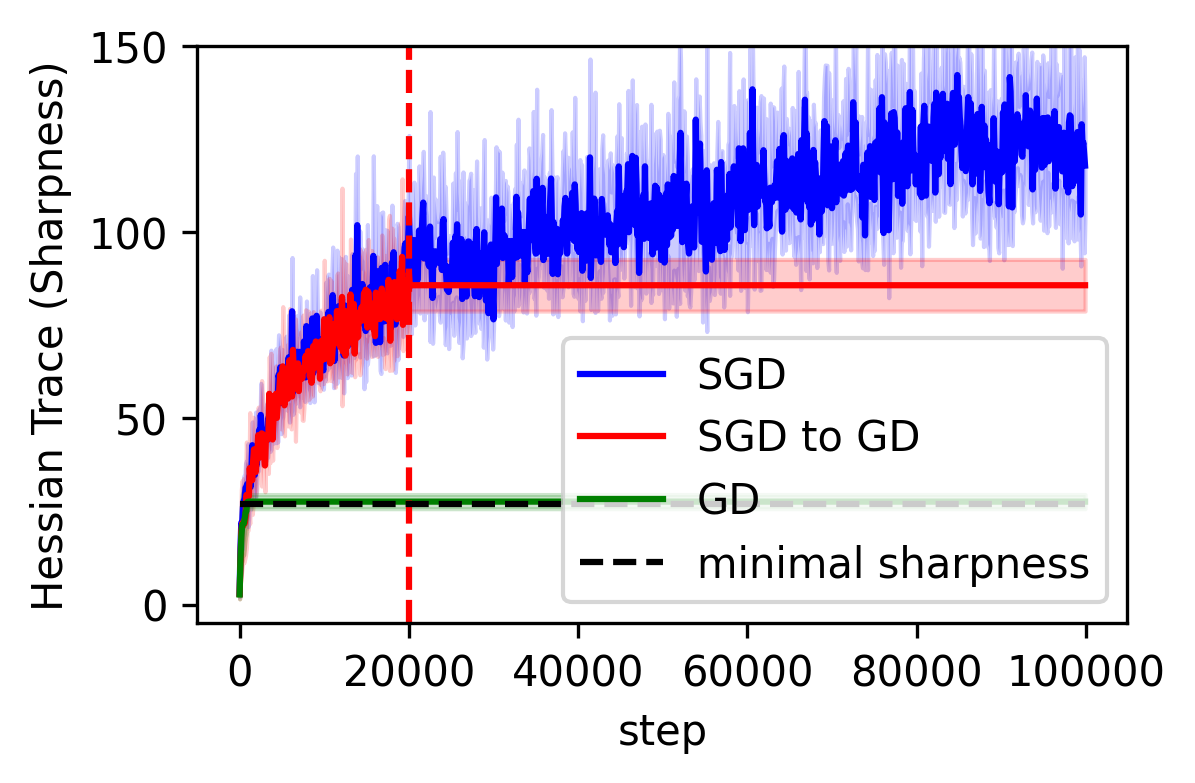
Why It Matters
This reframes a decade of conflicting results under a single lens. The “paradox” of SGD sometimes seeking flatness, sometimes seeking sharpness, was never a contradiction. Researchers were examining different data regimes without realizing that data geometry was the hidden variable.
Real-world datasets have highly structured, anisotropic noise. Think of uneven label uncertainty in image classification across different object categories, or the lopsided prediction difficulty across tokens in language modeling. Under the minimal-fluctuation framework, this structure directly shapes what kind of minimum SGD finds.
What follows for practice? Training recipes that inject synthetic noise (data augmentation, label smoothing, dropout) implicitly tune noise anisotropy, and per this theory, tune the sharpness of the final model. Sharpness-aware optimization methods like SAM, which explicitly push networks toward flat minima, may work best precisely where label noise happens to be isotropic. And if anisotropic noise can lead to arbitrarily sharp solutions, it raises a harder question: is sharpness even the right metric to monitor, or is gradient fluctuation the more fundamental quantity?
Bottom Line: SGD seeks minimal gradient fluctuation, not flatness, and it’s the structure of your data’s noise that decides whether those two goals point in the same direction. This exactly solvable result gives the field a clean causal handle on one of deep learning’s most persistent puzzles.
IAIFI Research Highlights
This work applies the mathematical toolkit of exactly solvable physics models (analytic solutions, closed-form predictions) to resolve a foundational question in deep learning theory, putting the IAIFI mission of physics-style reasoning applied to AI into practice.
The paper provides the first exact, causal account of when SGD prefers flat versus sharp minima, replacing a confusing empirical picture with a clear theoretical principle validated across MLP, RNN, and transformer architectures.
By framing optimization dynamics through noise geometry and gradient fluctuation theory, the work advances the broader program of understanding learning algorithms as physical processes governed by precise mathematical laws.
Future work could extend the minimal-fluctuation framework to real-world data distributions and explore how noise anisotropy interacts with sharpness-aware training methods. The paper by Xu, Beneventano, Chuang, and Ziyin is available at [arXiv:2602.05065](https://arxiv.org/abs/2602.05065).