
E Pluribus Unum Ex Machina: Learning from Many Collider Events at Once
Authors
Benjamin Nachman, Jesse Thaler
Abstract
There have been a number of recent proposals to enhance the performance of machine learning strategies for collider physics by combining many distinct events into a single ensemble feature. To evaluate the efficacy of these proposals, we study the connection between single-event classifiers and multi-event classifiers under the assumption that collider events are independent and identically distributed (IID). We show how one can build optimal multi-event classifiers from single-event classifiers, and we also show how to construct multi-event classifiers such that they produce optimal single-event classifiers. This is illustrated for a Gaussian example as well as for classification tasks relevant for searches and measurements at the Large Hadron Collider. We extend our discussion to regression tasks by showing how they can be phrased in terms of parametrized classifiers. Empirically, we find that training a single-event (per-instance) classifier is more effective than training a multi-event (per-ensemble) classifier, as least for the cases we studied, and we relate this fact to properties of the loss function gradient in the two cases. While we did not identify a clear benefit from using multi-event classifiers in the collider context, we speculate on the potential value of these methods in cases involving only approximate independence, as relevant for jet substructure studies.
Concepts
The Big Picture
Imagine you’re a detective trying to identify a suspect. You could analyze one fingerprint carefully, or you could dump 50 fingerprints into a blender, study the smeared result, and reason backward to the individual. The blender approach sounds absurd. Yet that’s roughly the logic behind a growing class of machine learning proposals for particle physics: take multiple collision events from the Large Hadron Collider (LHC), merge them into a single combined snapshot, and feed them to a neural network. More data at once must be better, right?
At the LHC, protons smash together millions of times per second. Each collision sprays a unique fingerprint of particles across the detector. Physicists have been racing to apply deep learning to these events, whether to hunt for new particles, measure known ones with higher precision, or study the structure of matter itself. A handful of recent papers proposed that by processing batches of events simultaneously, machine learning models might extract patterns invisible to single-event analysis. Surely a network that sees 100 events at once can pick up on statistical regularities that a one-at-a-time approach would miss?
Benjamin Nachman and Jesse Thaler set out to test this rigorously. Their answer is clean and definitive.
Key Insight: When collider events are statistically independent (which they are, to an excellent approximation), there is no informational advantage to training a multi-event classifier over a single-event classifier. The two approaches are provably equivalent, and in practice, the single-event approach wins.
How It Works
The result turns on a concept called IID (independent and identically distributed), meaning each collision is drawn from the same rulebook of physics, with no memory of previous collisions. No collision “knows about” any other. At the LHC, this is essentially exact: the probability of observing a batch of collisions is simply the product of each individual collision’s probability.
That factorization has a direct consequence for classifiers. The likelihood ratio, a score capturing how much more or less likely an event is under the “signal” hypothesis than the “background” hypothesis, is the key quantity any optimal classifier must learn. For a set of N events, this ratio is just the product of per-event likelihood ratios. So:
- An optimal per-ensemble classifier can always be built from an optimal per-instance classifier (take the product of single-event scores)
- Conversely, a per-ensemble classifier can be designed to recover an optimal per-instance classifier as a byproduct
Neither direction requires training on ensembles. The information content is identical. The paper’s title, E Pluribus Unum Ex Machina (“from many, one, by machine”), is a wry nod to this equivalence: the machine can extract the one from the many, or the many from the one, with no fundamental loss.
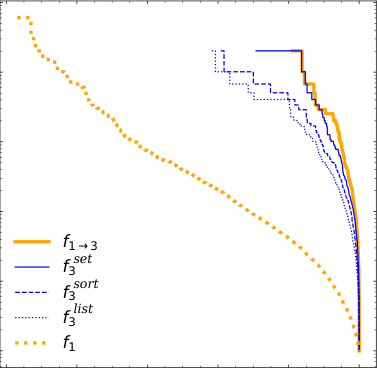
To move beyond theory, Nachman and Thaler ran empirical comparisons on three benchmark tasks: a simple two-Gaussian classification problem, a dijet resonance search (looking for a new particle decaying to two jets of hadrons), and a top quark mass measurement (extracting the mass of the heaviest known elementary particle). In each case, they compared models trained on individual events against models trained on ensembles.
Per-instance training won across the board. The reason comes down to gradient quality: when you train on ensembles, each individual event’s contribution gets diluted across all other events in the batch. The gradient signal telling the network “this feature matters” weakens when averaged over many events simultaneously. Training on single events keeps that signal sharp.
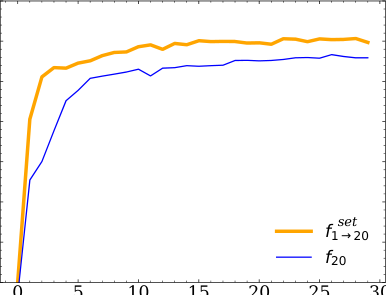
The analysis also covers regression tasks, not just “which class?” but “what is the value of a continuous parameter, like the top quark mass?” Regression can be recast as a parametrized classification problem, and per-instance approaches remain at least as effective as per-ensemble ones here too.
Why It Matters
Several multi-event proposals in the literature claimed advantages over single-event methods, backed by compelling empirical results. Nachman and Thaler don’t dispute those results. But they show that any such advantage can be matched by a carefully constructed single-event approach. This saves physicists from building complex architectures that process event ensembles when simpler per-instance networks would do as well or better.
The paper also identifies exactly where multi-event methods might genuinely help: situations where the IID assumption breaks down. The clearest example is jet substructure, the internal structure of particle sprays created when quarks and gluons collide. Inside a jet, particle emissions are not fully independent. They’re correlated by the underlying QCD (quantum chromodynamics) radiation pattern, the rules governing how quarks and gluons shed energy as they fly apart. Ensemble approaches capturing those collective correlations might have real advantages that no single-emission classifier can replicate. The authors leave this as an open question for future work.
The framework itself, translating between per-instance and per-ensemble learning and recasting regression as parametrized classification, is also useful beyond collider physics. It applies anywhere datasets consist of independent draws from parameterized distributions.
Bottom Line: Training a single-event classifier and combining scores is not just equivalent to training a multi-event classifier; it’s actually more effective in practice. The mathematical structure of IID collider data makes the ensemble approach redundant, at least until correlations enter the picture.
IAIFI Research Highlights
This work applies statistical theory to a live machine learning challenge in experimental particle physics, proving a formal equivalence between single-event and multi-event classifiers that directly guides how LHC analysis pipelines are designed.
The paper provides a concrete example where complex, set-based neural architectures offer no benefit over standard per-instance classifiers. For the broader ML community, it's a useful reminder that ensemble inputs can dilute gradients rather than add signal.
By clarifying the optimal strategy for classifying and measuring particle collision events, this research sharpens the tools physicists use to search for new particles and measure Standard Model parameters at the LHC.
Future work may uncover genuine advantages for multi-event methods in jet substructure studies, where particle emissions are approximately but not exactly independent; the full analysis is available at [arXiv:2101.07263](https://arxiv.org/abs/2101.07263).