
Efficient Dictionary Learning with Switch Sparse Autoencoders
Authors
Anish Mudide, Joshua Engels, Eric J. Michaud, Max Tegmark, Christian Schroeder de Witt
Abstract
Sparse autoencoders (SAEs) are a recent technique for decomposing neural network activations into human-interpretable features. However, in order for SAEs to identify all features represented in frontier models, it will be necessary to scale them up to very high width, posing a computational challenge. In this work, we introduce Switch Sparse Autoencoders, a novel SAE architecture aimed at reducing the compute cost of training SAEs. Inspired by sparse mixture of experts models, Switch SAEs route activation vectors between smaller "expert" SAEs, enabling SAEs to efficiently scale to many more features. We present experiments comparing Switch SAEs with other SAE architectures, and find that Switch SAEs deliver a substantial Pareto improvement in the reconstruction vs. sparsity frontier for a given fixed training compute budget. We also study the geometry of features across experts, analyze features duplicated across experts, and verify that Switch SAE features are as interpretable as features found by other SAE architectures.
Concepts
The Big Picture
Imagine trying to understand a foreign language by listening to a crowded café. Every conversation blends into noise, and even if you catch individual words, deciphering who said what feels impossible. That’s roughly the challenge facing researchers who want to understand what’s happening inside large language models.
These AI systems don’t process one idea at a time. They represent thousands of concepts simultaneously, all compressed together inside the same mathematical space. Figuring out which concept the model is “thinking about” at any given moment is like trying to separate overlapping radio signals.
Sparse autoencoders (SAEs) are one of the best tools available for untangling this mess. They act like signal-separation devices, taking the jumbled internal signals of a neural network and decomposing them into individual, human-readable “features,” the distinct concepts a model uses to process information.
But there’s a catch. To fully map the features inside frontier AI systems like GPT-4 or Claude, researchers estimate SAEs would need to scale to hundreds of millions or even billions of features. At that scale, current training methods hit a wall.
A team from MIT and Oxford has introduced an architectural fix called the Switch Sparse Autoencoder that sharply reduces the compute cost of training large SAEs without sacrificing quality.
Key Insight: By borrowing a trick from large-scale language model design (routing inputs to specialized “expert” subnetworks), Switch SAEs can scale to far more features than conventional approaches for the same training budget.
How It Works
A standard SAE learns to reconstruct its input, the stream of numerical signals called activations that flow through a neural network as it processes text, through a bottleneck. It encodes those signals into a high-dimensional representation where most values are zero (that’s what “sparse” means here), then decodes it back. The non-zero values in the middle are where the action is: each ideally corresponds to one interpretable concept, like “the model is thinking about royalty” or “this token appears to be a verb ending.”
The computational wall arises in the encoder, the first step where raw activations get compressed into that sparse representation. Wider encoders mean denser matrix multiplications, and unlike other parts of SAE training, this step can’t be made sparse. Scale it up enough, and training time explodes.
The Switch SAE sidesteps this wall entirely:
- Split the SAE into many smaller “expert” SAEs. Instead of one large encoder, the model maintains a collection of smaller expert networks, each responsible for a different slice of the feature space.
- Add a routing network. A lightweight trainable router examines each incoming activation vector and decides which expert SAE should handle it, sending it to exactly one expert, not all of them.
- Train with load balancing. To prevent all inputs from piling into one expert (a failure mode called expert collapse), the training loss includes a penalty that encourages even distribution across experts.
This design is directly inspired by Switch Transformers, a prior architecture that applied the same “route to one expert” trick to make massive language models trainable. The Switch SAE brings that logic to interpretability for the first time.
Across a range of compute budgets, Switch SAEs consistently achieve lower reconstruction error than conventional (TopK) SAEs trained with the same number of floating-point operations (FLOPs). For a fixed FLOP budget, Switch SAEs land at a better point on the reconstruction-vs-sparsity frontier.
There’s a nuance worth keeping in mind. Switch SAEs require more total parameters than dense SAEs to reach the same reconstruction quality when trained to convergence. But since compute is the binding constraint in practice, the Switch SAE wins where it matters most.
Why It Matters
The immediate payoff is practical: researchers can train meaningfully more powerful interpretability tools without proportionally increasing their compute bill.
The deeper significance ties into mechanistic interpretability, the project of understanding, in precise detail, what computations an AI is actually performing when it reasons, plans, or makes decisions. If we want to genuinely understand what frontier AI systems are doing (or what they might be concealing), we need tools that can map their internal representations at scale. Current estimates suggest even the most ambitious SAE training runs have barely scratched the surface of the full feature space. The Switch SAE architecture makes the next order of magnitude more tractable.
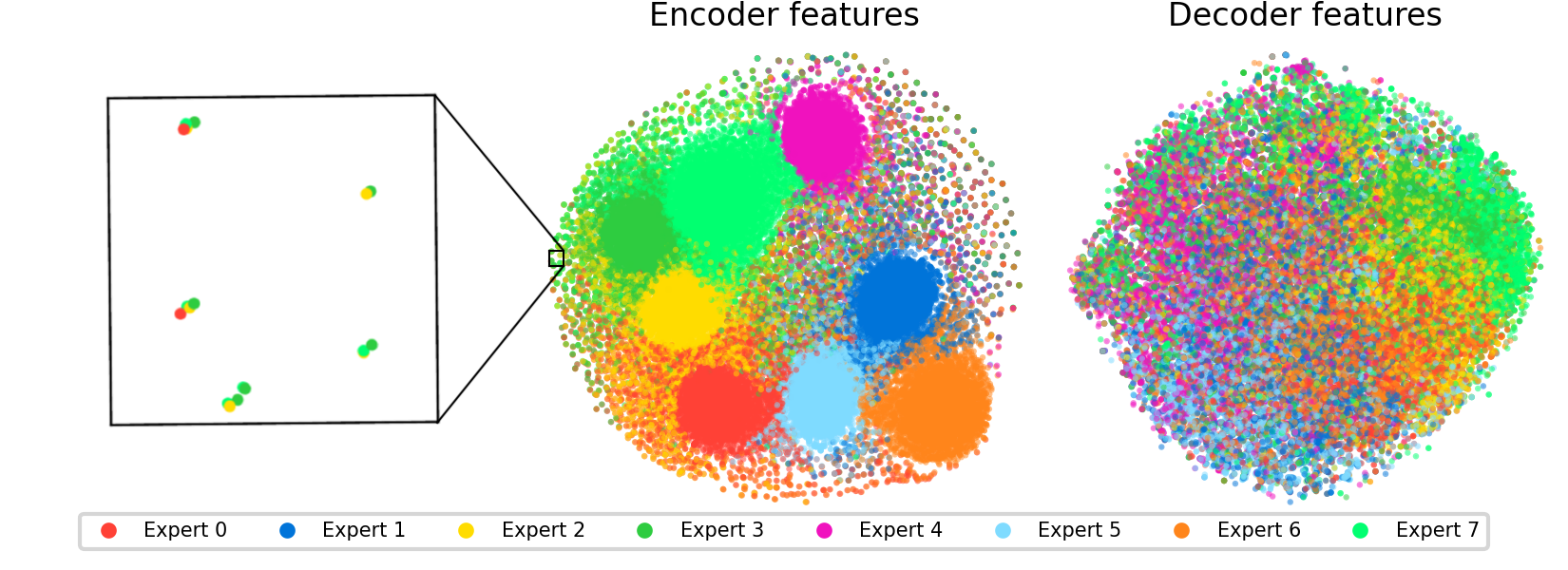
The paper also raises interesting scientific questions about feature structure itself. Features within a given expert cluster geometrically; they’re more similar to each other than to features in other experts. Some features appear duplicated across experts, suggesting the model learns slightly different “dialects” of the same concept in different routing contexts. This geometry hints that expert specialization isn’t arbitrary. The router is discovering something real about how the feature space is organized.
Future work could explore whether the expert structure itself reveals meaningful organization in how language models represent knowledge, turning a computational trick into a scientific instrument.
Bottom Line: Switch SAEs deliver a substantial improvement in reconstruction quality per unit of training compute, making it feasible to scale sparse autoencoders toward the feature counts needed to interpret frontier AI.
IAIFI Research Highlights
This work applies sparse mixture-of-experts scaling, originally developed for large language models, to neural network interpretability. It connects efficient ML engineering with the scientific goal of understanding AI from the inside out.
Switch SAEs reduce the compute cost of training sparse autoencoders through expert routing, enabling SAEs to scale to far more features for a fixed training budget and pushing mechanistic interpretability tools closer to frontier model scales.
By developing more efficient tools to decompose neural network representations into interpretable features, this research advances the study of internal structure in AI systems, a foundational question for both AI safety and our scientific understanding of learned computation.
Future directions include studying whether expert specialization reveals deeper organizational structure in language model knowledge representations. The paper is available at [arXiv:2410.08201](https://arxiv.org/abs/2410.08201) and corresponds to work from the MIT group led by Max Tegmark.