
Exploration Behavior of Untrained Policies
Authors
Jacob Adamczyk
Abstract
Exploration remains a fundamental challenge in reinforcement learning (RL), particularly in environments with sparse or adversarial reward structures. In this work, we study how the architecture of deep neural policies implicitly shapes exploration before training. We theoretically and empirically demonstrate strategies for generating ballistic or diffusive trajectories from untrained policies in a toy model. Using the theory of infinite-width networks and a continuous-time limit, we show that untrained policies return correlated actions and result in non-trivial state-visitation distributions. We discuss the distributions of the corresponding trajectories for a standard architecture, revealing insights into inductive biases for tackling exploration. Our results establish a theoretical and experimental framework for using policy initialization as a design tool to understand exploration behavior in early training.
Concepts
The Big Picture
Imagine being dropped into an unfamiliar city with a mostly blank map. How you explore (wandering randomly, walking in straight lines, gridding the streets) determines how quickly you fill it in. AI agents trained through trial and error, known as reinforcement learning or RL, face the same challenge: they must explore their environment to learn, but before learning anything, they have no idea where to go.
Most RL research focuses on rewards, bonus points for visiting new places, penalties for getting stuck. But Jacob Adamczyk at UMass Boston and IAIFI asks a more fundamental question: what if the underlying structure of an AI’s decision-making network, before any training begins, already determines how an agent explores? What if the shape of that decision network encodes hidden exploration biases nobody has been paying attention to?
The answer is yes. The consequences run deeper than you’d expect.
Key Insight: Untrained neural network policies aren’t random noise generators. Their architecture imposes structure on exploration trajectories, producing either smooth “ballistic” motion or diffusive random walks depending on how the policy is initialized and used.
How It Works
The core observation: a neural network with randomly initialized weights is not a random function. Neural networks are smooth. They map nearby inputs to nearby outputs. In RL, this smoothness has a direct physical consequence.
Two distinct trajectory regimes emerge from different ways of using an untrained policy:
- Ballistic trajectories — near-linear paths through state space, produced when an agent uses the same untrained policy throughout an episode
- Diffusive trajectories — broadly spreading, heavy-tailed distributions, produced by resampling a fresh random policy at every timestep
Ballistic trajectories arise because a smooth network maps similar states to similar actions. With continuous environment dynamics, the agent drifts like a ball rolling down a hill. Adamczyk formalizes this with a Lipschitz continuity argument: if the policy is $L_\pi$-Lipschitz and the environment dynamics are similarly well-behaved, the trajectory deviates from a straight line by at most an error that grows quadratically in time. Standard multilayer perceptron networks (MLPs with two hidden layers, 256 nodes, ReLU activations) produce exactly this behavior in simulation.
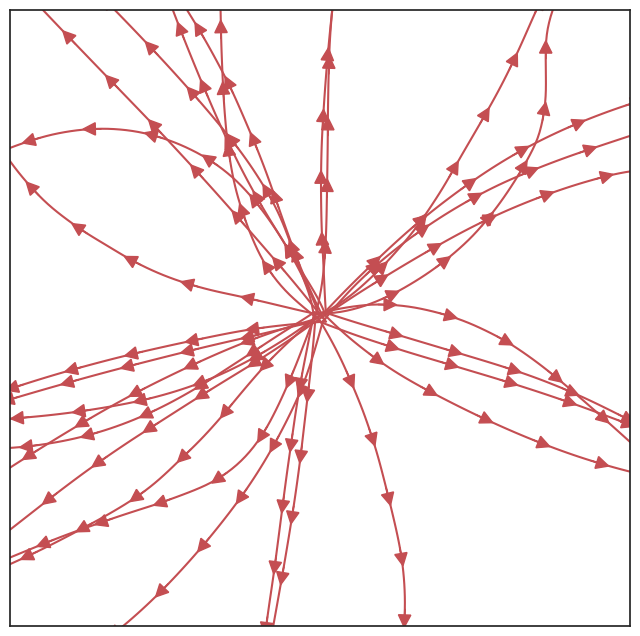
Diffusive trajectories require a different strategy: resampling a fresh random policy at every timestep. This creates a stochastic trajectory ensemble even with fully deterministic dynamics. The math becomes tractable through the infinite-width limit. As a network’s hidden layers grow arbitrarily wide, the distribution over functions it represents converges to a Gaussian Process (GP), a mathematical tool for describing families of smooth random functions.
This is where physics enters. Once the action sequence is treated as draws from a GP, the agent’s trajectory becomes a stochastic process amenable to tools from statistical mechanics. The Fokker-Planck equation, which governs how probability distributions evolve over time, describes the dynamics. The kernel structure of the GP (determined by network architecture and activation functions) sets the diffusion coefficient and hence the character of exploration.
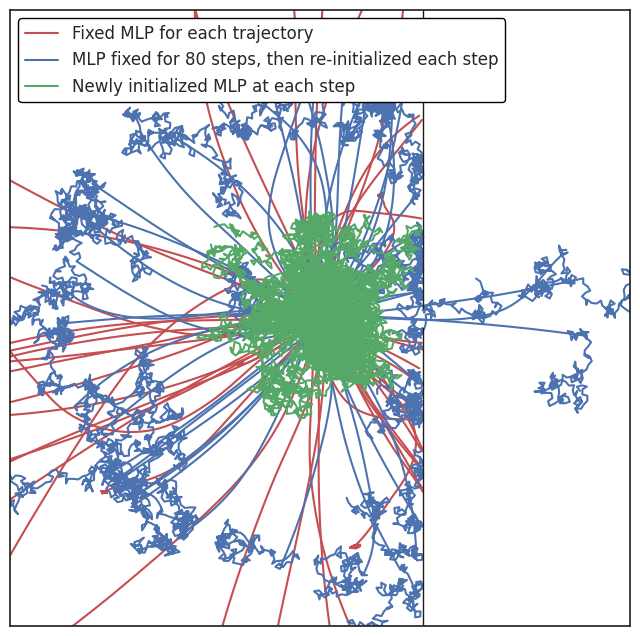
Resampled policies produce heavy-tailed steady-state distributions over visited states, so the agent spreads broadly rather than clustering near its start. Ballistic and diffusive regimes aren’t mutually exclusive; combining them offers a design knob for controlling the geometry of exploration before any training begins.
Why It Matters
Exploration becomes a problem of architecture design, not reward shaping. Most existing exploration methods (curiosity bonuses, count-based rewards, Thompson sampling) require extra networks, modified reward signals, or computational overhead. Adamczyk shows you can get meaningful control over exploration for free, simply by choosing how you initialize and resample your policy before training starts.
The connection to physics is more than decorative. Fokker-Planck analysis and GP theory are mature tools in statistical mechanics and quantum field theory, and importing them into RL opens new analytical avenues. Heavy-tailed distributions from diffusive trajectories resemble Lévy flights, a pattern found in animal foraging and long studied as an optimal exploration strategy in uncertain environments. That the same pattern emerges naturally from neural network priors is a nontrivial result.
The toy model here deliberately sidesteps complexities of real RL: value-based algorithms, stochastic environments, high-dimensional state spaces. But the theoretical scaffolding (Lipschitz bounds, GP limits, Fokker-Planck analysis) should translate to richer settings. One could even imagine a new role for neural architecture search: rather than optimizing purely for expressivity or generalization, search for architectures whose initialization distributions produce favorable exploration geometries for a given task.
Bottom Line: Untrained neural network policies already encode rich exploration behavior through their architecture. By understanding this structure theoretically, researchers can use policy initialization itself as a design tool, independent of rewards or additional training overhead.
IAIFI Research Highlights
This work imports tools from statistical physics (Gaussian Process theory, the Fokker-Planck equation, Lipschitz analysis) into reinforcement learning, showing that the mathematical language of diffusion and random processes naturally describes neural policy behavior at initialization.
Architecture implicitly determines exploration geometry before any training occurs. This opens a new design axis for RL practitioners: choosing initializations that induce favorable trajectory distributions without additional exploration rewards or auxiliary networks.
Applying infinite-width network limits and continuous-time stochastic analysis connects neural network theory to classical physics, showing that tools developed to understand physical systems at scale apply equally well to deep learning dynamics.
Future work will extend these results beyond toy models to realistic RL environments and value-based algorithms. The paper is available at [arXiv:2506.22566](https://arxiv.org/abs/2506.22566).