
Fast convolutional neural networks on FPGAs with hls4ml
Authors
Thea Aarrestad, Vladimir Loncar, Nicolò Ghielmetti, Maurizio Pierini, Sioni Summers, Jennifer Ngadiuba, Christoffer Petersson, Hampus Linander, Yutaro Iiyama, Giuseppe Di Guglielmo, Javier Duarte, Philip Harris, Dylan Rankin, Sergo Jindariani, Kevin Pedro, Nhan Tran, Mia Liu, Edward Kreinar, Zhenbin Wu, Duc Hoang
Abstract
We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate an inference latency of $5\,μ$s using convolutional architectures, targeting microsecond latency applications like those at the CERN Large Hadron Collider. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device used in trigger and data acquisition systems of particle detectors. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be significantly reduced with little to no loss in model accuracy. We show that the FPGA critical resource consumption can be reduced by 97% with zero loss in model accuracy, and by 99% when tolerating a 6% accuracy degradation.
Concepts
The Big Picture
Imagine a fire hose pumping out data at 40 million bursts per second. Inside the Large Hadron Collider at CERN, proton beams slam together every 25 nanoseconds, spewing roughly a megabyte of raw detector data per collision. No computer can store or process all of it, so physicists rely on ultra-fast hardware that makes split-second decisions about which collisions are worth keeping. Miss something interesting, and it’s gone forever.
The gatekeepers of this torrent are called Level-1 triggers: electronic systems that must inspect each collision and decide its fate in about one microsecond (a millionth of a second). For decades, these triggers ran on custom logic carved into silicon. Deep learning created an obvious opportunity. What if neural networks could spot subtle signatures of new physics that rigid rule-based systems might miss?
The catch is brutal. Deep learning typically takes milliseconds. The LHC needs microseconds, a thousand times faster. That gap seemed impossible to close.
A team spanning CERN, MIT, Fermilab, and a dozen other institutions tackled this head-on. Their answer: extend hls4ml, an open-source tool that converts neural networks into firmware (low-level code baked directly into hardware) for field-programmable gate arrays (FPGAs), reconfigurable chips that execute specific computations at blinding speed. The team adds full support for convolutional neural networks (CNNs), the architecture behind modern image recognition, and delivers answers in just 5 microseconds.
Key Insight: By combining streaming-based CNN layers with model compression (pruning dead weights and training with low-precision arithmetic), hls4ml can slash FPGA resource consumption by 97–99% while preserving nearly all accuracy, making deep learning viable inside particle physics trigger systems.
How It Works
The challenge starts at the mathematical level. A standard convolutional layer slides a small filter across an image, computing thousands of overlapping calculations. On a conventional processor, this happens sequentially. On an FPGA targeting microsecond latency, sequential processing is a non-starter.
The hls4ml team’s solution is a streaming architecture: data flows through the network continuously, with different layers overlapping their work like an assembly line. At its core sits a line buffer, a small memory that stores just enough of the incoming image for a sliding filter window to scan. The filter begins computing as soon as its first window of pixels arrives. This pipelining (where processing stages overlap rather than wait for the previous stage to finish) lets the FPGA process a new input every clock cycle once the pipeline is full.
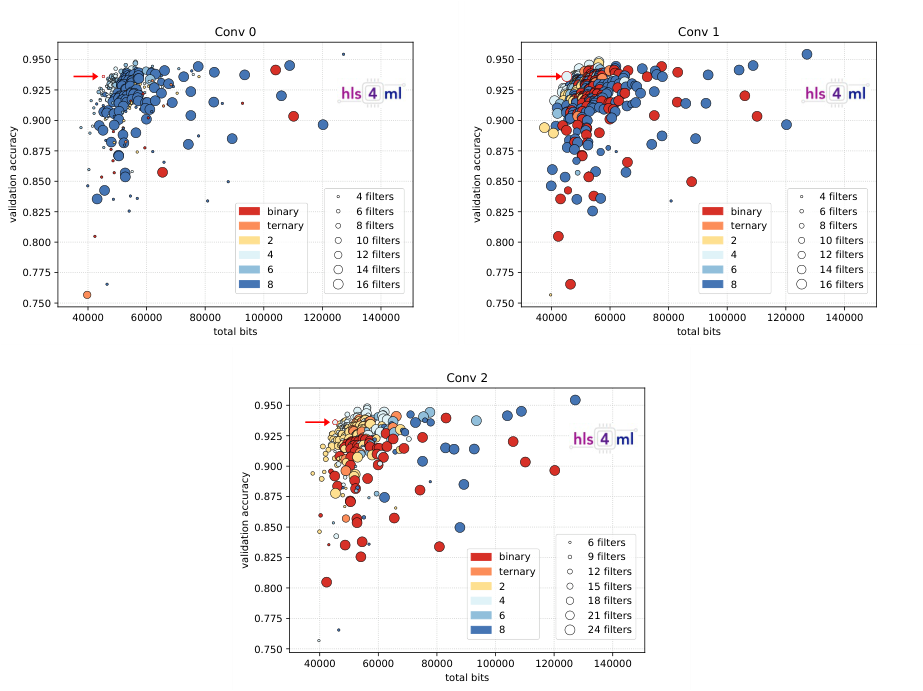
To validate the approach, the team trained a CNN on the Street View House Numbers (SVHN) dataset: house number images from Google Street View, complex enough to stress-test the hardware but manageable for FPGA deployment. The baseline model hit 92% test accuracy. Then came the hard part: squeezing it onto a chip with serious resource limits.
Two compression strategies did the heavy lifting:
- Pruning: Weights close to zero are forced to exactly zero, then permanently removed from the firmware. The FPGA skips those computations entirely, saving resources and power with no approximation error.
- Quantization-aware training (QAT): Instead of 32-bit floating-point weights, the QKeras library trains with reduced precision, as few as 2 or 3 bits per weight. The network learns to compensate for the coarseness during training, which dramatically outperforms quantization applied after training is complete.
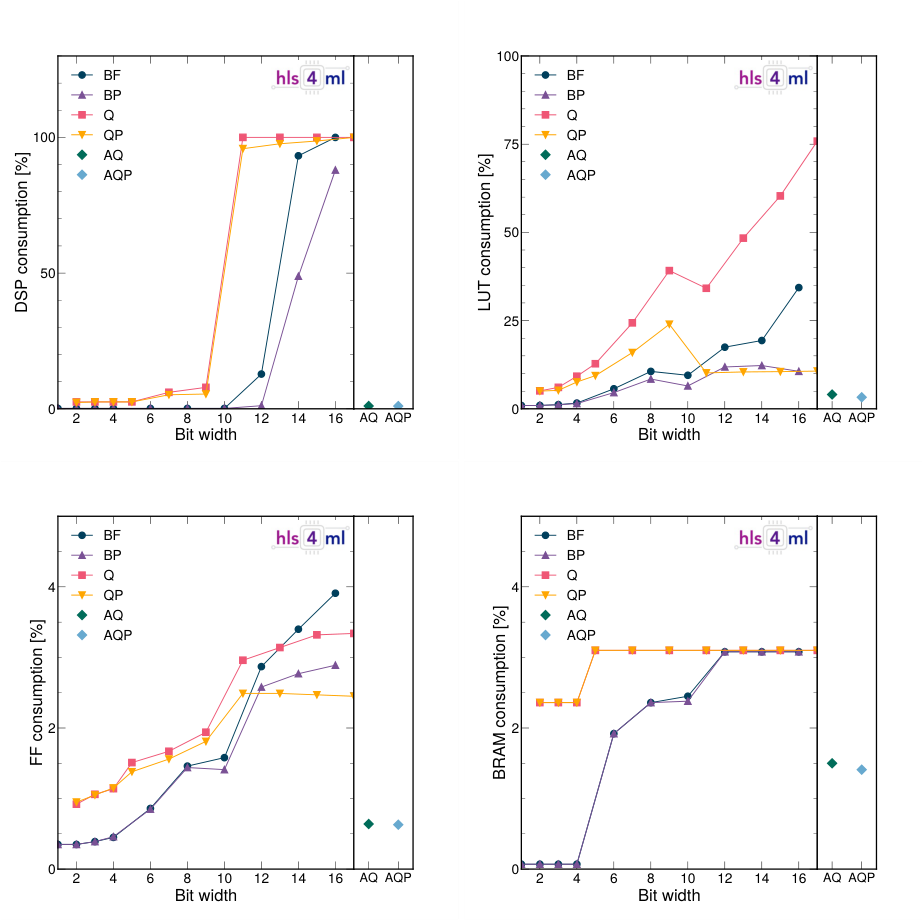
Starting from a baseline too resource-hungry for practical deployment, pruning and quantization together reduced DSP usage (the specialized hardware blocks that handle neural network multiplications) by 97% with zero accuracy loss. Pushing harder and accepting a 6% accuracy hit cut resource usage by 99%. The final compressed model runs with 5-microsecond inference latency, comfortably within the LHC trigger budget.
Why It Matters
For particle physics, the payoff is direct: trigger systems can now incorporate CNN-based classifiers that previously existed only in offline analysis. More sophisticated real-time selection could catch rare decay signatures or new-physics events that simpler triggers would discard. The LHC’s High-Luminosity upgrade, coming in the late 2020s, will push collision rates even higher and make intelligent triggering more critical than ever.
But the applications go well beyond CERN. Anywhere edge computing (processing on a device itself rather than in a remote data center) demands real-time inference under tight power and latency budgets, the hls4ml workflow offers a path forward. Autonomous sensors, medical implants, satellite payloads, industrial monitoring: all could benefit from a tool that converts a trained PyTorch or Keras model into running hardware firmware without manual chip-design expertise.
Open-source tooling and multi-vendor FPGA support keep the barrier to entry low. What’s needed next: larger architectures, recurrent and transformer support, and tighter integration with neural architecture search (automated methods that explore thousands of network designs to find the best hardware fit) so that model structure and hardware constraints can be co-optimized from the start.
Bottom Line: hls4ml’s new CNN support enables 5-microsecond deep learning inference on FPGAs, fast enough for the LHC’s trigger systems, achieving 97–99% resource savings through principled pruning and quantization. Real-time neural-network-powered particle physics is now within reach.
IAIFI Research Highlights
This work adapts image-recognition architectures (CNNs) for deployment inside CERN's particle detector trigger systems, where microsecond decisions determine which collision data is preserved for science, connecting computer vision directly to high-energy physics.
The hls4ml framework shows that streaming-based FPGA deployment combined with quantization-aware training can achieve extreme compression ratios (up to 99% resource reduction) while maintaining near-original model accuracy, pushing the boundary of efficient neural network deployment on constrained hardware.
CNN-based inference at 5 μs latency makes it feasible to deploy learned classifiers in the Level-1 trigger of LHC experiments, potentially improving sensitivity to rare and exotic particle physics signatures.
Future directions include extending hls4ml to larger architectures and co-designing network structure with hardware constraints from the outset; the full paper is available at [arXiv:2101.05108](https://arxiv.org/abs/2101.05108).
Original Paper Details
Fast convolutional neural networks on FPGAs with hls4ml
[2101.05108](https://arxiv.org/abs/2101.05108)
Thea Aarrestad, Vladimir Loncar, Nicolò Ghielmetti, Maurizio Pierini, Sioni Summers, Jennifer Ngadiuba, Christoffer Petersson, Hampus Linander, Yutaro Iiyama, Giuseppe Di Guglielmo, Javier Duarte, Philip Harris, Dylan Rankin, Sergo Jindariani, Kevin Pedro, Nhan Tran, Mia Liu, Edward Kreinar, Zhenbin Wu, Duc Hoang
We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate an inference latency of 5 μs using convolutional architectures, targeting microsecond latency applications like those at the CERN Large Hadron Collider. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device used in trigger and data acquisition systems of particle detectors. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be significantly reduced with little to no loss in model accuracy. We show that the FPGA critical resource consumption can be reduced by 97% with zero loss in model accuracy, and by 99% when tolerating a 6% accuracy degradation.