
Feature Learning and Generalization in Deep Networks with Orthogonal Weights
Authors
Hannah Day, Yonatan Kahn, Daniel A. Roberts
Abstract
Fully-connected deep neural networks with weights initialized from independent Gaussian distributions can be tuned to criticality, which prevents the exponential growth or decay of signals propagating through the network. However, such networks still exhibit fluctuations that grow linearly with the depth of the network, which may impair the training of networks with width comparable to depth. We show analytically that rectangular networks with tanh activations and weights initialized from the ensemble of orthogonal matrices have corresponding preactivation fluctuations which are independent of depth, to leading order in inverse width. Moreover, we demonstrate numerically that, at initialization, all correlators involving the neural tangent kernel (NTK) and its descendants at leading order in inverse width -- which govern the evolution of observables during training -- saturate at a depth of $\sim 20$, rather than growing without bound as in the case of Gaussian initializations. We speculate that this structure preserves finite-width feature learning while reducing overall noise, thus improving both generalization and training speed in deep networks with depth comparable to width. We provide some experimental justification by relating empirical measurements of the NTK to the superior performance of deep nonlinear orthogonal networks trained under full-batch gradient descent on the MNIST and CIFAR-10 classification tasks.
Concepts
The Big Picture
Imagine playing telephone across a hundred people. Each person adds a little noise, a mumble here, a misheard word there. By the end, the original message is unrecognizable. Now imagine each person trained to preserve the exact volume and clarity of what they received, passing along only meaningful content. The final message arrives crisp and intact, no matter how long the chain.
That’s essentially what physicists and machine learning researchers at the University of Illinois and MIT have achieved for deep neural networks, by swapping out one mathematical ingredient at the very start of training. Instead of setting a network’s starting connection strengths using numbers drawn from a standard bell-curve distribution, they initialize them as orthogonal matrices: special arrangements of numbers that, by construction, preserve the size of any signal passing through. The result is a network that behaves consistently whether it’s ten layers deep or a hundred.
The core problem here is the exploding and vanishing gradient problem, where the error signals used to teach the network either balloon out of control or shrink to nothing as they travel back through many layers. Even after decades of clever engineering workarounds, the fundamental question remained: can we design initializations that keep these signals under control as depth grows? Hannah Day, Yonatan Kahn, and Daniel A. Roberts show mathematically, and confirm through experiments, that orthogonal initialization does exactly this.
Key Insight: Initializing neural network weights from orthogonal matrices, rather than standard Gaussian distributions, makes the statistical fluctuations governing training behavior independent of network depth, opening the door to stable, efficient training in very deep networks.
How It Works
The standard recipe for initializing a deep network draws each weight from a Gaussian (bell-curve) distribution, then tunes a parameter called criticality, a mathematical sweet spot that prevents signals from exploding or collapsing as they travel forward through layers.
This works reasonably well, but there’s a catch. Even at criticality, Gaussian networks suffer from preactivation fluctuations (statistical noise in layer signals) that grow linearly with depth. These scale as L/n, where L is depth and n is width. When depth rivals width (L/n ~ 1), the fluctuations grow large enough to interfere with training.
Orthogonal matrices offer a cleaner starting point. A square orthogonal matrix O satisfies O^T O = I: it’s a pure rotation or reflection that reshapes and reorients without ever stretching or compressing. The authors prove analytically that for networks using tanh activations (a smooth, S-shaped function belonging to a universality class of mathematically similar functions), orthogonal initialization makes preactivation fluctuations independent of depth, to leading order in 1/n. The telephone chain no longer degrades with length.
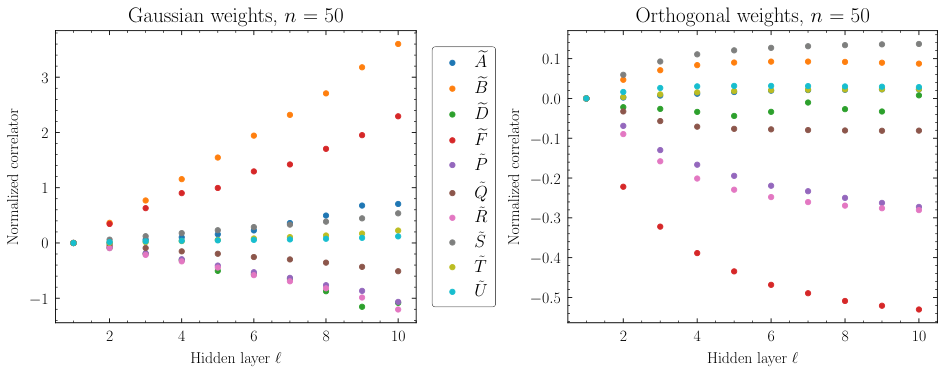
The analysis hinges on computing the connected 4-point correlator, a statistical quantity measuring how much four neurons’ outputs co-vary. Think of it as a proxy for the overall noisiness of a network’s internal representations. For Gaussian initializations, this quantity grows without bound as depth increases. For orthogonal initializations with tanh, it stays flat.
This result holds in the finite-width regime, the realistic setting where networks have a limited number of neurons per layer, using a systematic expansion in powers of 1/n to track corrections that arise in real networks.
The authors then examine the neural tangent kernel (NTK), the central object governing how a network’s outputs change during gradient descent. The NTK and its statistical relatives encode how features evolve as the network learns. For Gaussian networks, NTK correlators scale with L/n, growing indefinitely. For orthogonal networks, the numerics tell a different story:
- At initialization, NTK correlators saturate around depth L ~ 20
- Beyond that depth, adding more layers doesn’t increase the noise
- This saturation appears across all NTK correlators studied, not just one
This saturation is the main experimental signature. Very deep orthogonal networks don’t accumulate progressively chaotic training dynamics. They hit a stable regime early and stay there.
Why It Matters
The practical payoff shows up in classification experiments. The team trained fully-connected networks on MNIST (handwritten digits) and CIFAR-10 (small color images) using full-batch gradient descent, a controlled setting that strips away the complexity of modern optimizers and regularization tricks.
In shallow networks (L/n << 1), Gaussian and orthogonal initializations perform comparably. Push into the deep regime (L/n ~ 1), and orthogonal networks pull ahead: better generalization, faster training. NTK fluctuations stay suppressed throughout the training run, confirming that initial stability translates into stable learning dynamics.
What makes this work distinctive is where the tools come from. Perturbative expansions in 1/n, universality classes borrowed from statistical field theory, the geometry of matrix ensembles: these are the bread and butter of theoretical physics, repurposed here to say something precise about neural networks. The authors identify which activation functions belong to the right universality class (tanh yes, ReLU no), and that classification determines whether orthogonal initialization delivers its depth-independence benefits. This is structural insight from analytical theory, not empirical trial and error.
Open questions remain. The analysis covers fully-connected networks with tanh activations and full-batch gradient descent. Modern architectures use attention mechanisms, residual connections, and stochastic optimizers. Extending this framework to transformers and convolutional networks is a natural next step, and the authors also note that combining orthogonal initialization with techniques like LayerNorm could prove fruitful.
Bottom Line: Orthogonal weight initialization tames the noise that plagues deep Gaussian networks, keeping training dynamics stable regardless of depth. For anyone designing or scaling very deep networks, the choice of weight distribution at initialization may matter more than previously appreciated.
IAIFI Research Highlights
This work applies techniques from theoretical physics (perturbative expansions, universality classes, and random matrix theory) to derive rigorous analytical results about neural network training dynamics, exemplifying the physics-informed AI research at IAIFI's core.
The paper provides the first analytical and numerical evidence that orthogonal initialization suppresses NTK fluctuations independently of depth, offering a principled explanation for the empirically observed superior generalization of deep orthogonal networks.
By establishing which universality classes of activation functions inherit depth-independent fluctuations, the work imports the concept of universality (central to statistical mechanics and quantum field theory) into the theory of neural networks.
Future directions include extending the orthogonal initialization framework to convolutional and attention-based architectures and deriving optimal hyperparameter prescriptions for the *L/n ~ 1* regime; the paper is available at [arXiv:2310.07765](https://arxiv.org/abs/2310.07765).
Original Paper Details
Feature Learning and Generalization in Deep Networks with Orthogonal Weights
[2310.07765](https://arxiv.org/abs/2310.07765)
["Hannah Day", "Yonatan Kahn", "Daniel A. Roberts"]
Fully-connected deep neural networks with weights initialized from independent Gaussian distributions can be tuned to criticality, which prevents the exponential growth or decay of signals propagating through the network. However, such networks still exhibit fluctuations that grow linearly with the depth of the network, which may impair the training of networks with width comparable to depth. We show analytically that rectangular networks with tanh activations and weights initialized from the ensemble of orthogonal matrices have corresponding preactivation fluctuations which are independent of depth, to leading order in inverse width. Moreover, we demonstrate numerically that, at initialization, all correlators involving the neural tangent kernel (NTK) and its descendants at leading order in inverse width -- which govern the evolution of observables during training -- saturate at a depth of $\sim 20$, rather than growing without bound as in the case of Gaussian initializations. We speculate that this structure preserves finite-width feature learning while reducing overall noise, thus improving both generalization and training speed in deep networks with depth comparable to width. We provide some experimental justification by relating empirical measurements of the NTK to the superior performance of deep nonlinear orthogonal networks trained under full-batch gradient descent on the MNIST and CIFAR-10 classification tasks.