
Field of Junctions: Extracting Boundary Structure at Low SNR
Authors
Dor Verbin, Todd Zickler
Abstract
We introduce a bottom-up model for simultaneously finding many boundary elements in an image, including contours, corners and junctions. The model explains boundary shape in each small patch using a 'generalized M-junction' comprising M angles and a freely-moving vertex. Images are analyzed using non-convex optimization to cooperatively find M+2 junction values at every location, with spatial consistency being enforced by a novel regularizer that reduces curvature while preserving corners and junctions. The resulting 'field of junctions' is simultaneously a contour detector, corner/junction detector, and boundary-aware smoothing of regional appearance. Notably, its unified analysis of contours, corners, junctions and uniform regions allows it to succeed at high noise levels, where other methods for segmentation and boundary detection fail.
Concepts
The Big Picture
Imagine trying to sketch a map of a city in thick fog. You can barely make out the streets, but you know they form corners at intersections, smooth curves as they bend, and T-junctions where side streets meet main roads. A skilled cartographer wouldn’t squint at one intersection at a time. They’d use their knowledge of how streets connect to fill in what the fog obscures. That’s the idea behind a new computer vision model from Harvard that finds image edges and boundaries in conditions where virtually every other approach goes blind.
Vision researchers have chased the boundary detection problem for decades, and for good reason: finding where one region ends and another begins is a prerequisite for almost everything a visual system needs to do. Detect an object, understand a scene, navigate a room. Images taken at short exposures, in low light, or from challenging sensors are riddled with noise. Most boundary detection methods, even deep learning systems trained on millions of images, fail catastrophically as that noise climbs.
Researchers Dor Verbin and Todd Zickler at Harvard’s SEAS have developed the field of junctions, a unified framework that simultaneously finds three types of image boundaries: smooth edges (contours), sharp corners, and junctions where multiple edges converge at a point. Rather than treating these as separate tasks, the model handles them cooperatively, so each type of boundary reinforces the others during analysis.
Key Insight: By representing every small image patch as a “generalized junction,” a wedge-shaped primitive that can smoothly deform into a contour, corner, or multi-way intersection, the model lets all boundary types reinforce each other. This enables detection even when signal-to-noise ratio plummets.
How It Works
The central building block is deceptively elegant. The researchers define a generalized M-junction: a model for a small image patch consisting of M angular wedges radiating from a center point, each wedge assigned a distinct color. With the right parameters, this single shape can represent:
- A uniform region (no edges at all)
- A contour (two wedges, one boundary line passing through)
- A corner (two wedges meeting at an acute angle)
- A junction of degree M (M wedges, M boundary rays meeting at a point)
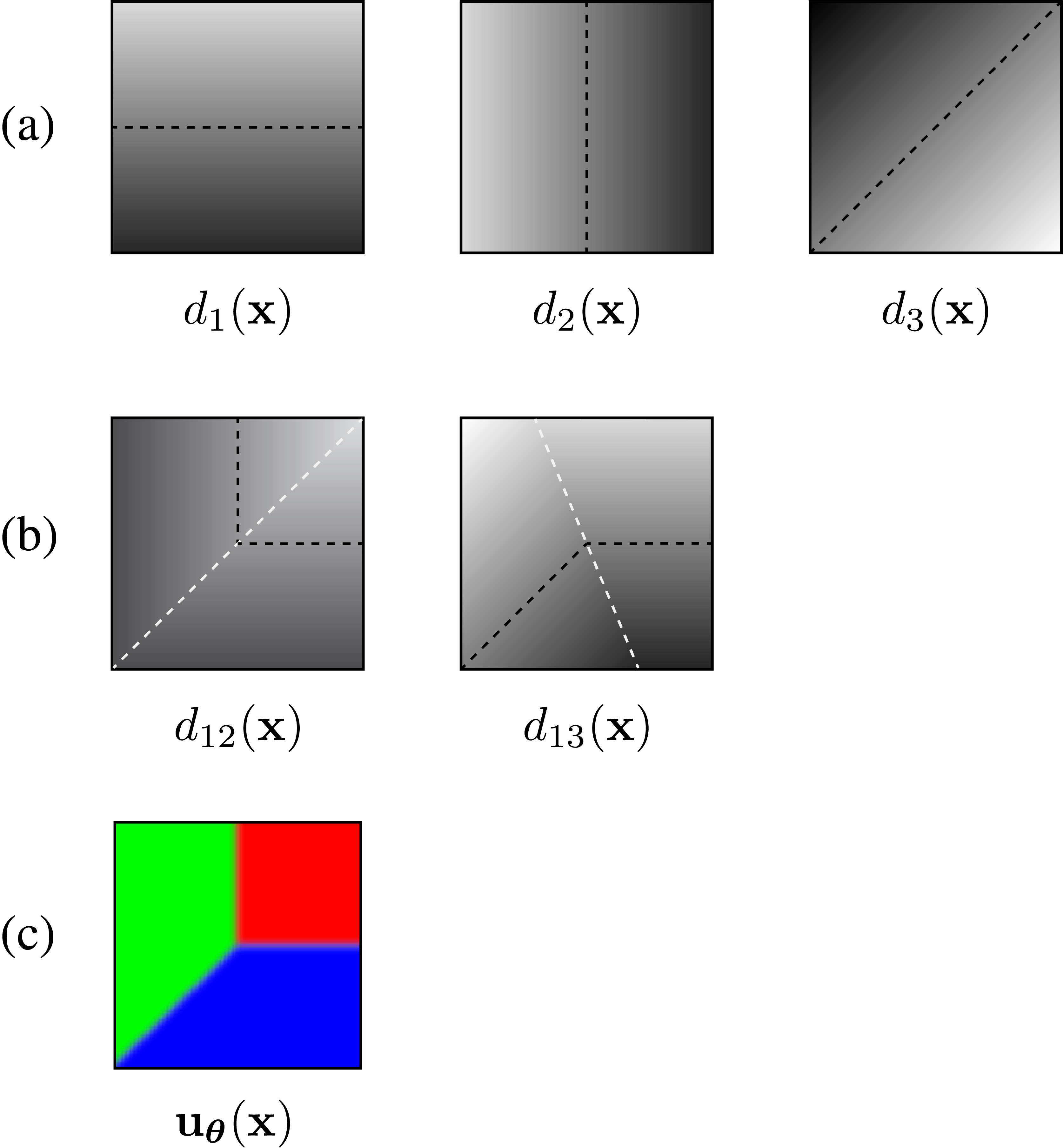
To analyze an entire image, the model fits M+2 parameters to dense, overlapping small patches at every location: the M angles, the vertex position, and the regional colors. This requires solving a non-convex optimization problem (a mathematical search where the landscape has many local valleys, making it easy to get stuck before finding the best answer) across the full image simultaneously. Patches share information with their neighbors, so a noisy patch with ambiguous boundary evidence gets help from surrounding patches where the signal is clearer.
Making the optimization work demanded two innovations. First, a greedy initialization algorithm builds up the junction configuration one wedge at a time, establishing good starting conditions before the global search begins. Second, a novel spatial regularizer, a mathematical penalty that steers the model toward smooth, physically plausible boundaries, penalizes boundary curvature while simultaneously preserving sharp corners and multi-way junctions. Previous curvature-minimization methods couldn’t do this because they only handled two-region boundaries.
The regularizer’s design is subtle but important. Traditional curvature penalties round off corners because the math doesn’t distinguish between a corner that should be sharp and curvature that should be smoothed away. The field of junctions sidesteps this by encoding the distinction structurally: corners and junctions are zero-dimensional events that the model explicitly represents. The regularizer then smooths contours between them without blurring the junctions themselves.
Why It Matters
The immediate payoff is dramatic noise resilience. The paper shows the field of junctions operating on extremely short-exposure images that produce heavily corrupted data, extracting boundary maps that competing methods completely miss, even when those competitors are preceded by state-of-the-art denoising. This matters for astronomy, medical imaging, autonomous systems in low light, and any application where increasing exposure isn’t an option.
The deeper point is conceptual. The field of junctions is a model-based approach, not a learned one. It carries no trained weights, requires no labeled boundary data, and applies equally well to single-channel or multi-channel images regardless of imaging modality.
Encoder-decoder networks (neural networks that compress an image down and then expand it back up to locate boundaries) excel by internalizing statistical patterns from large datasets, but struggle with spatial precision because internal downsampling blurs boundaries. They also have trouble generalizing to radically novel imaging conditions. The field of junctions trades dataset-specific performance for principled generality, a trade-off that becomes especially valuable in scientific and low-data domains.
The framework also produces an interpretable intermediate representation: not just “there’s a boundary here,” but “here’s a contour, here’s a corner, here’s a three-way junction, and here are the regional colors on each side.” Open questions remain. Can the optimization be accelerated for real-time use? Could the junction representation serve as a structural prior inside deep networks, combining model-based generality with learned expressiveness? How far does the noise tolerance extend, to 3D volumetric data, temporal sequences, or modalities far from natural images?
Bottom Line: The field of junctions reframes boundary detection as a cooperative, unified problem. In doing so, it achieves noise tolerance that leaves specialized, state-of-the-art methods behind, pointing toward a new class of interpretable, model-based vision primitives.
IAIFI Research Highlights
This work draws on optimization theory, signal processing, and computational geometry to build a vision model that behaves more like a physicist's structured inference problem than a traditional machine learning system.
The field of junctions shows that carefully designed model-based representations can outperform deep neural networks in high-noise regimes, offering a principled alternative for domains where large labeled datasets are unavailable or imaging conditions are extreme.
Boundary extraction from noisy images is directly relevant to scientific imaging in physics, from detecting particle tracks in detectors to parsing structure in astronomical observations, where signal-to-noise constraints are severe.
Future work may explore integrating the field of junctions as a structural prior within neural architectures and extending the framework to 3D or temporal data; the paper is available at [arXiv:2011.13866](https://arxiv.org/abs/2011.13866).