
FINDER: Feature Inference on Noisy Datasets using Eigenspace Residuals
Authors
Trajan Murphy, Akshunna S. Dogra, Hanfeng Gu, Caleb Meredith, Mark Kon, Julio Enrique Castrillion-Candas
Abstract
''Noisy'' datasets (regimes with low signal to noise ratios, small sample sizes, faulty data collection, etc) remain a key research frontier for classification methods with both theoretical and practical implications. We introduce FINDER, a rigorous framework for analyzing generic classification problems, with tailored algorithms for noisy datasets. FINDER incorporates fundamental stochastic analysis ideas into the feature learning and inference stages to optimally account for the randomness inherent to all empirical datasets. We construct ''stochastic features'' by first viewing empirical datasets as realizations from an underlying random field (without assumptions on its exact distribution) and then mapping them to appropriate Hilbert spaces. The Kosambi-Karhunen-Loéve expansion (KLE) breaks these stochastic features into computable irreducible components, which allow classification over noisy datasets via an eigen-decomposition: data from different classes resides in distinct regions, identified by analyzing the spectrum of the associated operators. We validate FINDER on several challenging, data-deficient scientific domains, producing state of the art breakthroughs in: (i) Alzheimer's Disease stage classification, (ii) Remote sensing detection of deforestation. We end with a discussion on when FINDER is expected to outperform existing methods, its failure modes, and other limitations.
Concepts
The Big Picture
Imagine trying to identify someone’s face through a frosted glass window. The more frosted the glass, the harder it becomes, and most AI classification tools essentially give up when the frost gets too thick. Noisy data poses exactly this challenge: when measurements are corrupted, samples are scarce, or sensors are faulty, standard machine learning methods fail in ways that carry real consequences. A misdiagnosed patient. A missed early warning of deforestation.
The problem shows up everywhere in science. Medical imaging datasets may contain only dozens of patients. Satellite data can be riddled with atmospheric interference. When there are far more measurements per sample than there are samples to learn from (a situation that arises constantly in medicine, astronomy, and environmental science), even sophisticated models end up memorizing noise instead of learning real patterns.
The usual fixes often aren’t available. Gathering more data may be impossible or unaffordable. Adjusting model settings or adding training constraints only goes so far.
A team from Boston University and Imperial College London developed FINDER (Feature Inference on Noisy Datasets using Eigenspace Residuals), a mathematically grounded framework that rethinks how classifiers handle noisy data. They validated it on two high-stakes scientific problems.
Key Insight: Rather than treating noise as an obstacle to work around, FINDER treats data randomness as a mathematical object to analyze directly, extracting clean classification signals from datasets where standard approaches break down.
How It Works
FINDER starts from a shift in perspective. Rather than treating a dataset as a fixed collection of numbers, the framework treats it as a single realization of an underlying random field, a mathematical object capturing all the ways the data could have turned out given the noisy process that generated it. A single blurry photograph is one instance of what a camera might capture, not the ground truth itself. FINDER takes that idea seriously.
From there, FINDER proceeds in three steps:
- Dataset acquisition: Collect the raw data, however noisy.
- Feature construction: Map the data into a Hilbert space, an abstract coordinate space that can accommodate data of any complexity, where data from different classes lands in geometrically distinct regions.
- Classification: Build a classifier on top of those structured features.
The mathematical engine behind step two is the Kosambi-Karhunen-Loève expansion (KLE), a theorem from stochastic analysis that works like a Fourier series for random functions. Just as a complex sound wave decomposes into pure tones, the KLE breaks a stochastic feature into simpler components ordered by how much of the data’s variance they explain. The signal of class differences rises to the top. Noise, disorganized by definition, falls to the bottom and gets discarded.
The resulting objects are stochastic features: compositions of the random-field mapping and the Hilbert space embedding that directly encode the stochasticity of the data-generating process. The team proves this decomposition holds when converting continuous measurements into digital numbers, and derives principled criteria for truncating the infinite series so that the method runs on real computers in reasonable time.
Once stochastic features are constructed, classification is the easy part. Data from different classes occupy distinct eigenspace regions, and simple classifiers like support vector machines (SVMs, which find the clearest mathematical boundary separating categories) or hidden Markov models (HMMs, which detect patterns unfolding across a sequence) achieve much higher accuracy on FINDER’s structured features than on raw noisy data.
Why It Matters
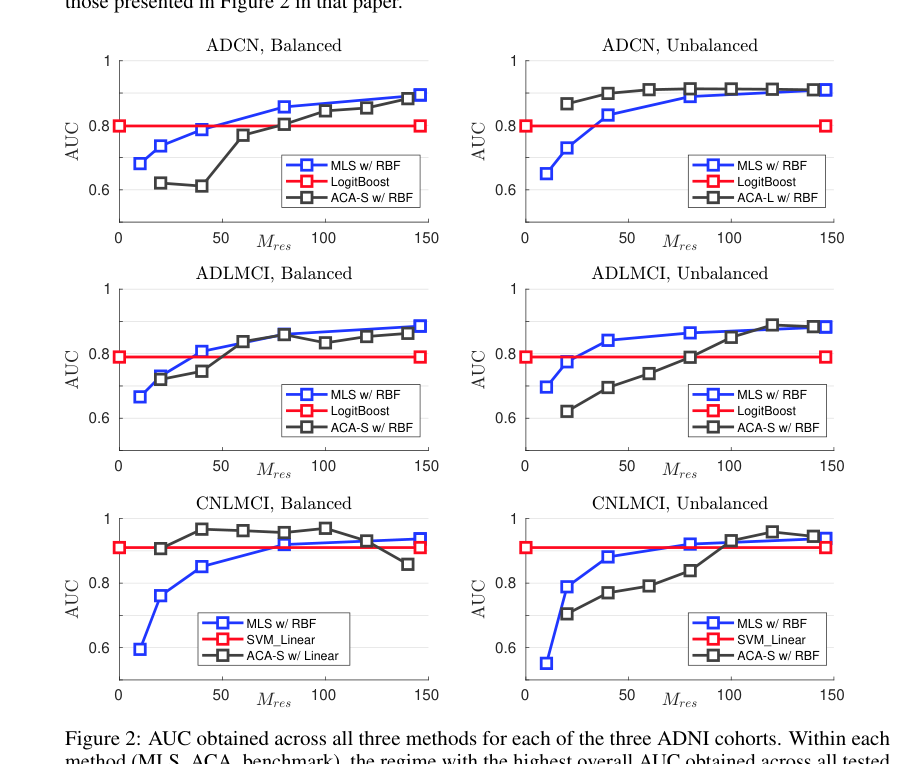
The results on real datasets speak for themselves. On Alzheimer’s Disease stage classification, FINDER hit state-of-the-art performance on a notoriously difficult neuroimaging dataset from the Alzheimer’s Disease Neuroimaging Initiative (ADNI). Brain scan data is high-dimensional, expensive to collect, and deeply heterogeneous between patients. These are exactly the conditions where FINDER’s noise-aware design pays off.
On remote sensing deforestation detection, where satellite imagery is corrupted by clouds, seasonal variation, and sensor noise, FINDER again beat existing methods. These aren’t toy benchmarks. Alzheimer’s staging from imaging data could accelerate clinical trials and enable earlier interventions. Automated deforestation detection is a tool for environmental monitoring at scales no human analyst can match.
There’s a broader point here, too. The field has largely advanced by throwing more data and more compute at problems. FINDER takes a different path: building the mathematical structure of uncertainty directly into the feature representation, making the most of whatever data exists. The authors are upfront about its limitations (it’s not a universal solution), but the framework gives a rigorous way to ask when noise-aware methods should win, and by how much.
Open questions remain. Can the KLE-based approach extend to multi-class problems beyond binary classification? How does FINDER interact with modern deep learning architectures, where features are learned end-to-end? Can stochastic feature construction scale to truly large datasets without sacrificing its mathematical guarantees?
Bottom Line: FINDER delivers state-of-the-art results in Alzheimer’s staging and deforestation detection by treating noisy data not as a limitation to overcome, but as structured randomness to exploit.
IAIFI Research Highlights
FINDER draws on stochastic analysis, a branch of pure mathematics, to solve practical AI classification problems. This is the kind of cross-disciplinary work that sits at the heart of IAIFI's research mission.
By constructing features that mathematically encode data randomness via the Kosambi-Karhunen-Loève expansion, FINDER provides new theoretical footing for classification in high-dimensional, low-sample regimes where standard ML methods struggle.
The framework's success on neuroimaging and remote sensing datasets shows that mathematical tools from physics-adjacent fields can sharply improve AI performance in data-starved scientific domains, with potential applications in particle physics and cosmology.
Future work may extend FINDER's stochastic feature framework to deep learning pipelines and multi-class scientific problems; the full paper is available at [arXiv:2510.19917](https://arxiv.org/abs/2510.19917).