
Formation of Representations in Neural Networks
Authors
Liu Ziyin, Isaac Chuang, Tomer Galanti, Tomaso Poggio
Abstract
Understanding neural representations will help open the black box of neural networks and advance our scientific understanding of modern AI systems. However, how complex, structured, and transferable representations emerge in modern neural networks has remained a mystery. Building on previous results, we propose the Canonical Representation Hypothesis (CRH), which posits a set of six alignment relations to universally govern the formation of representations in most hidden layers of a neural network. Under the CRH, the latent representations (R), weights (W), and neuron gradients (G) become mutually aligned during training. This alignment implies that neural networks naturally learn compact representations, where neurons and weights are invariant to task-irrelevant transformations. We then show that the breaking of CRH leads to the emergence of reciprocal power-law relations between R, W, and G, which we refer to as the Polynomial Alignment Hypothesis (PAH). We present a minimal-assumption theory proving that the balance between gradient noise and regularization is crucial for the emergence of the canonical representation. The CRH and PAH lead to an exciting possibility of unifying major key deep learning phenomena, including neural collapse and the neural feature ansatz, in a single framework.
Concepts
The Big Picture
Imagine you’re trying to understand how a master sculptor thinks. You could study the finished statue, but you’d learn far more watching the sculptor’s hands at work, examining the tools they use, and discovering that hands, tools, and stone all move in synchrony. Researchers at MIT have found something similar happening inside neural networks: the internal patterns a network builds, the connection weights between its neurons, and the error signals (called gradients) guiding its learning all snap into alignment during training. This alignment may be a universal law of how neural networks think.
For decades, neural networks have been black boxes. We know they work spectacularly well, but not why. What internal structures do they build? Why do those structures transfer across tasks? What mathematical laws govern how they form? This gap hampers our ability to design better AI systems. A team from MIT and Texas A&M has now proposed a unifying framework, the Canonical Representation Hypothesis, that describes representation formation in neural networks through just six equations.
Key Insight: Neural networks don’t learn representations by accident. Their internal activations, weights, and gradients are driven into mutual alignment during training by a universal mechanism, producing compact and transferable internal structure.
How It Works
The core idea is deceptively simple. Inside any hidden layer of a neural network, three mathematical objects are constantly in play: the latent representations R (what the network “sees” at that layer), the weights W (connection strengths between neurons), and the neuron gradients G (error signals driving learning). The Canonical Representation Hypothesis (CRH) proposes that after training, these three objects don’t merely coexist. They align with each other in a precise mathematical sense.
The team identifies three types of alignment, where covariance measures how two quantities vary together across the network:
- Representation-Gradient Alignment (RGA): The covariance of activations becomes proportional to the covariance of gradients
- Representation-Weight Alignment (RWA): The covariance of activations becomes proportional to the weight outer product
- Gradient-Weight Alignment (GWA): The covariance of gradients becomes proportional to the weight outer product
Each layer has both a “pre-activation” side (the raw input before a neuron fires) and a “post-activation” side (the output after firing). Each relation therefore comes in forward and backward versions, yielding six alignment equations in total. When all six hold simultaneously, the network satisfies the CRH.
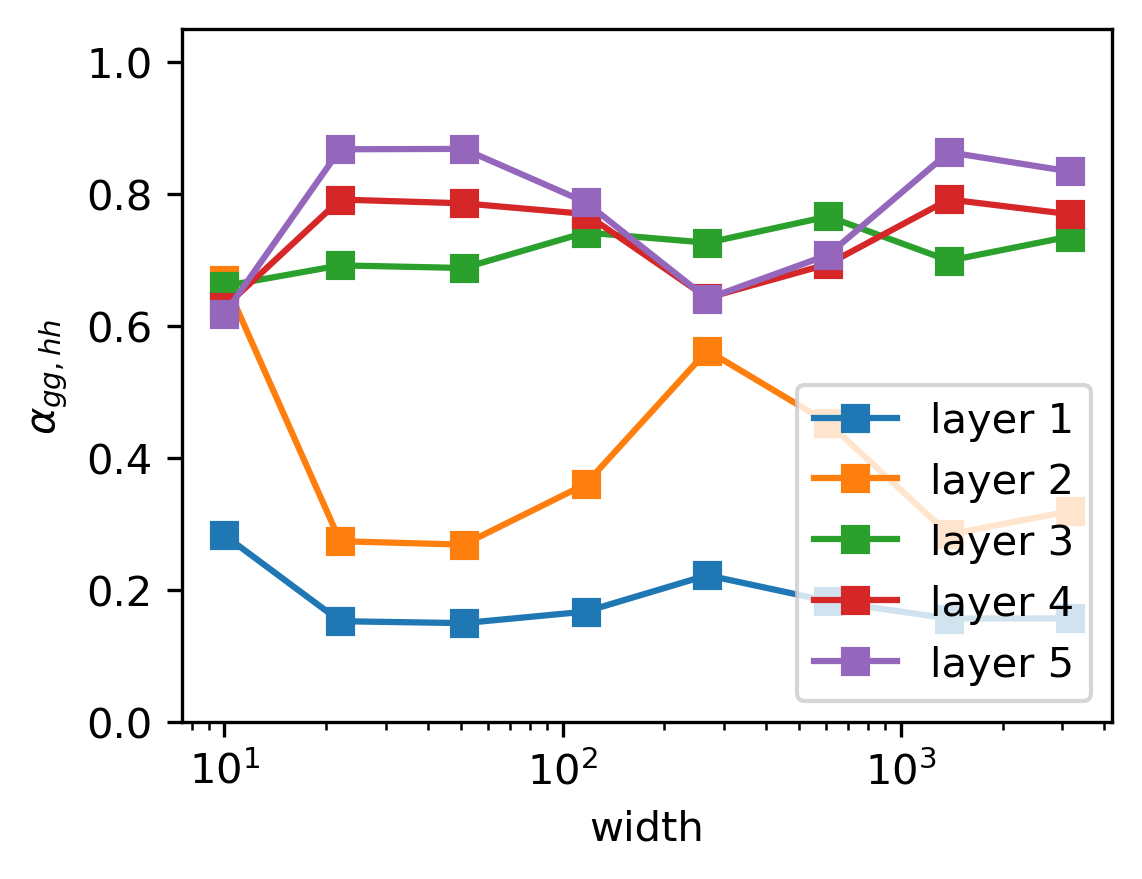
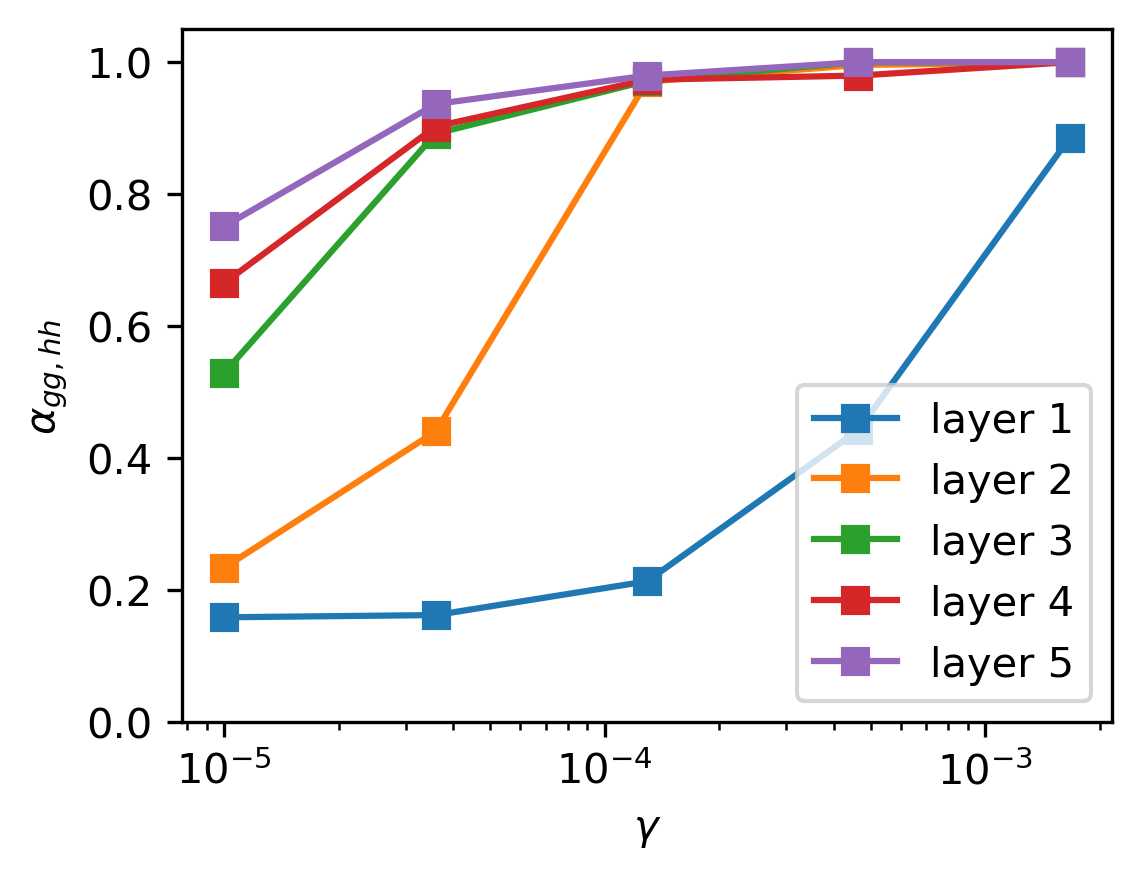
What drives this alignment? The researchers prove it emerges from a balance between two competing forces: gradient noise (the randomness in how training samples are drawn) and regularization (the pressure to keep weights small). Neither alone produces alignment. Together, though, they act like opposing forces finding a natural equilibrium, pushing representations toward a canonical form. The proof requires few assumptions, so it applies broadly across architectures and tasks.
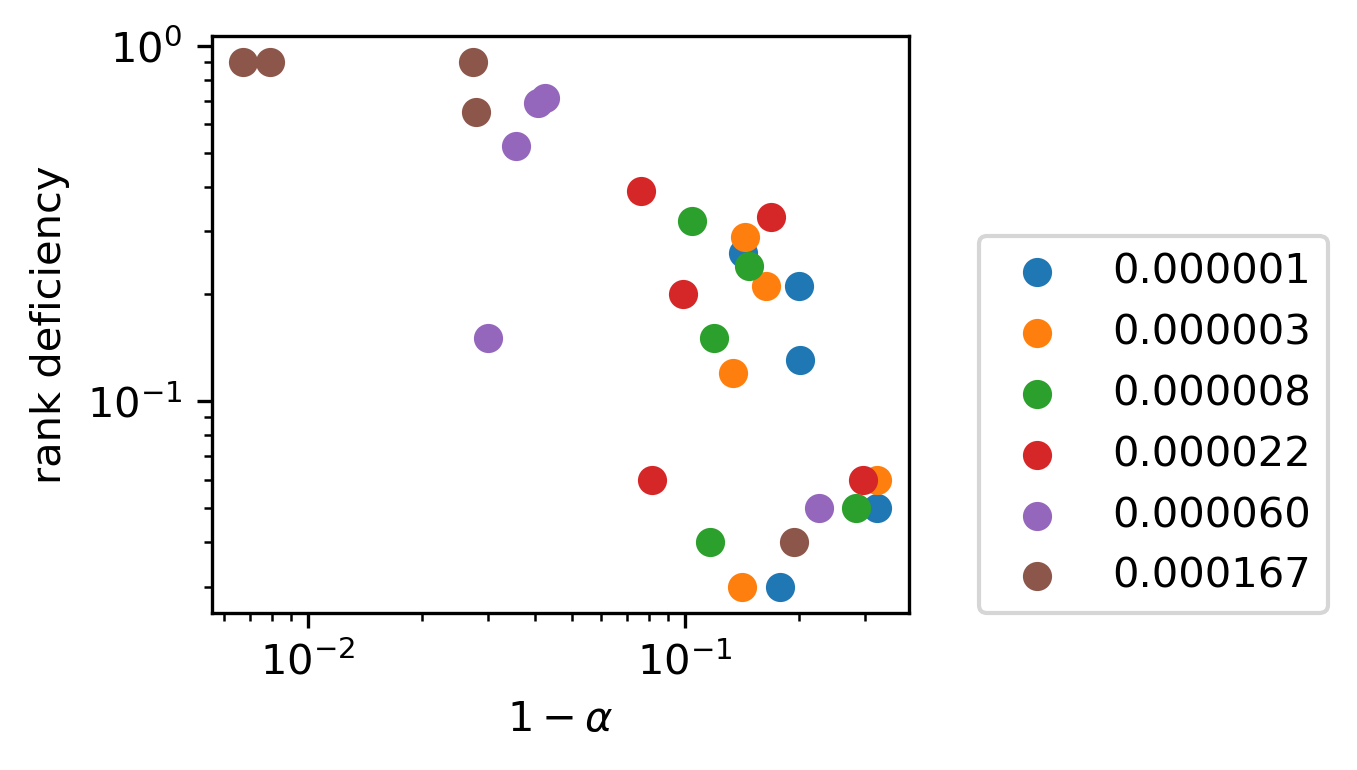
Real networks are messy, and the CRH doesn’t always hold perfectly. When alignment breaks (in early layers, very large networks, or certain training regimes) the paper predicts something unexpected: R, W, and G don’t simply become uncorrelated. Instead, they follow reciprocal power-law relations with each other. The team calls this the Polynomial Alignment Hypothesis (PAH). Rather than perfect proportionality, you get scaling relationships with exponents that characterize distinct “phases” of a neural network layer, analogous to phases of matter in physics.
Why It Matters
The CRH turns out to be a Rosetta Stone for neural network theory. Two major phenomena in deep learning, neural collapse (where final-layer representations collapse onto a perfectly symmetric geometric structure in classifiers) and the neural feature ansatz (where weight matrices evolve according to gradient outer products), had been studied in isolation. The CRH shows they are both special cases of the same underlying alignment mechanism.
Neural collapse emerges when the CRH holds in the penultimate layer of a classifier. The neural feature ansatz is recovered as a particular forward alignment relation. What we’ve been discovering piecemeal appears to be facets of a single, deeper law.
There are practical implications too. If trained networks obey universal alignment laws, we can predict structural properties of a network’s internals without expensive experiments, guiding choices about architecture, initialization, and training dynamics. It also opens a path toward mechanistic interpretability: if we know the geometry that representations converge toward, we can design probes and interventions that exploit that geometry rather than treating the network as an opaque system.
Bottom Line: The Canonical Representation Hypothesis is a first candidate for a universal law of representation formation in neural networks, one that unifies previously disconnected phenomena and explains why deep learning produces compact, transferable internal structure.
IAIFI Research Highlights
This work applies concepts from statistical physics (phase transitions, scaling laws, thermodynamic balance) to explain how structure emerges in artificial neural networks, cross-pollinating AI theory with physics intuition in the spirit of IAIFI's mission.
The CRH and PAH provide a unified theoretical framework explaining neural collapse, the neural feature ansatz, and emergent power-law scaling under a single set of equations.
The discovery of universal phases in neural network layers, governed by the balance between gradient noise and regularization, mirrors the role of competing forces in physical phase transitions. The parallels between learning systems and physical systems run deeper than previously appreciated.
Future work could extend the CRH to attention-based architectures and use the framework to guide more efficient and interpretable model design; the paper appears at ICLR 2025, authored by Liu Ziyin, Isaac Chuang, Tomer Galanti, and Tomaso Poggio.