
Generating Interpretable Networks using Hypernetworks
Authors
Isaac Liao, Ziming Liu, Max Tegmark
Abstract
An essential goal in mechanistic interpretability to decode a network, i.e., to convert a neural network's raw weights to an interpretable algorithm. Given the difficulty of the decoding problem, progress has been made to understand the easier encoding problem, i.e., to convert an interpretable algorithm into network weights. Previous works focus on encoding existing algorithms into networks, which are interpretable by definition. However, focusing on encoding limits the possibility of discovering new algorithms that humans have never stumbled upon, but that are nevertheless interpretable. In this work, we explore the possibility of using hypernetworks to generate interpretable networks whose underlying algorithms are not yet known. The hypernetwork is carefully designed such that it can control network complexity, leading to a diverse family of interpretable algorithms ranked by their complexity. All of them are interpretable in hindsight, although some of them are less intuitive to humans, hence providing new insights regarding how to "think" like a neural network. For the task of computing L1 norms, hypernetworks find three algorithms: (a) the double-sided algorithm, (b) the convexity algorithm, (c) the pudding algorithm, although only the first algorithm was expected by the authors before experiments. We automatically classify these algorithms and analyze how these algorithmic phases develop during training, as well as how they are affected by complexity control. Furthermore, we show that a trained hypernetwork can correctly construct models for input dimensions not seen in training, demonstrating systematic generalization.
Concepts
The Big Picture
Imagine trying to understand how a calculator works by only looking at its output. No buttons, no display, just the answer. That’s roughly what researchers face when trying to decode how a neural network actually solves a problem. The field of mechanistic interpretability exists to crack open these networks and read the algorithm hidden inside.
There’s a catch: most existing work starts with a known algorithm and builds a network specifically designed to reproduce it. That guarantees interpretability, but it also guarantees you’ll never discover anything genuinely new.
A team from MIT (Isaac Liao, Ziming Liu, and Max Tegmark) decided to flip the script. Instead of asking “how do we build a network that implements this algorithm?”, they asked: “Can we build a system that generates interpretable networks, and then figure out what those algorithms are?” The answer was yes, and the algorithms it found included ones nobody had thought to look for.
Their tool is a hypernetwork: a neural network that designs the internal parameters of another, smaller neural network. By training this hypernetwork carefully, the team produced a family of tiny networks that all solve the same simple problem (computing the L1 norm, or sum of absolute values of a list of numbers) but through surprisingly different and previously unknown methods.
Hypernetworks can systematically explore the space of interpretable algorithms, discovering computational strategies that humans never thought to try but can still understand in hindsight.
How It Works
The researchers chose a deliberately simple test case: the L1 norm. It sounds almost trivial. But simplicity was the point. If you can’t fully understand how a network computes something this basic, what hope is there for complex tasks?
The target networks are compact two-layer MLPs (multi-layer perceptrons, a standard architecture where neurons are organized in stacked layers that pass information in sequence) with 16 input neurons, 48 hidden neurons, and a single output. They use the swish activation function, a smooth curve governing how strongly each neuron fires in response to its input. Conventional training produces networks that technically solve the problem but look like noise: no discernible structure, no interpretable pattern.
The hypernetwork changes the game in two ways. First, it generates weights with structured, repeating motifs that are the fingerprints of an underlying algorithm. Second, it includes a parameter β that controls model complexity by balancing how well the network fits data against a penalty for unnecessary complexity. High β means simpler networks; low β allows more complex ones. By sweeping β and collecting models across 33 random seeds, the team assembled a rich library for analysis.
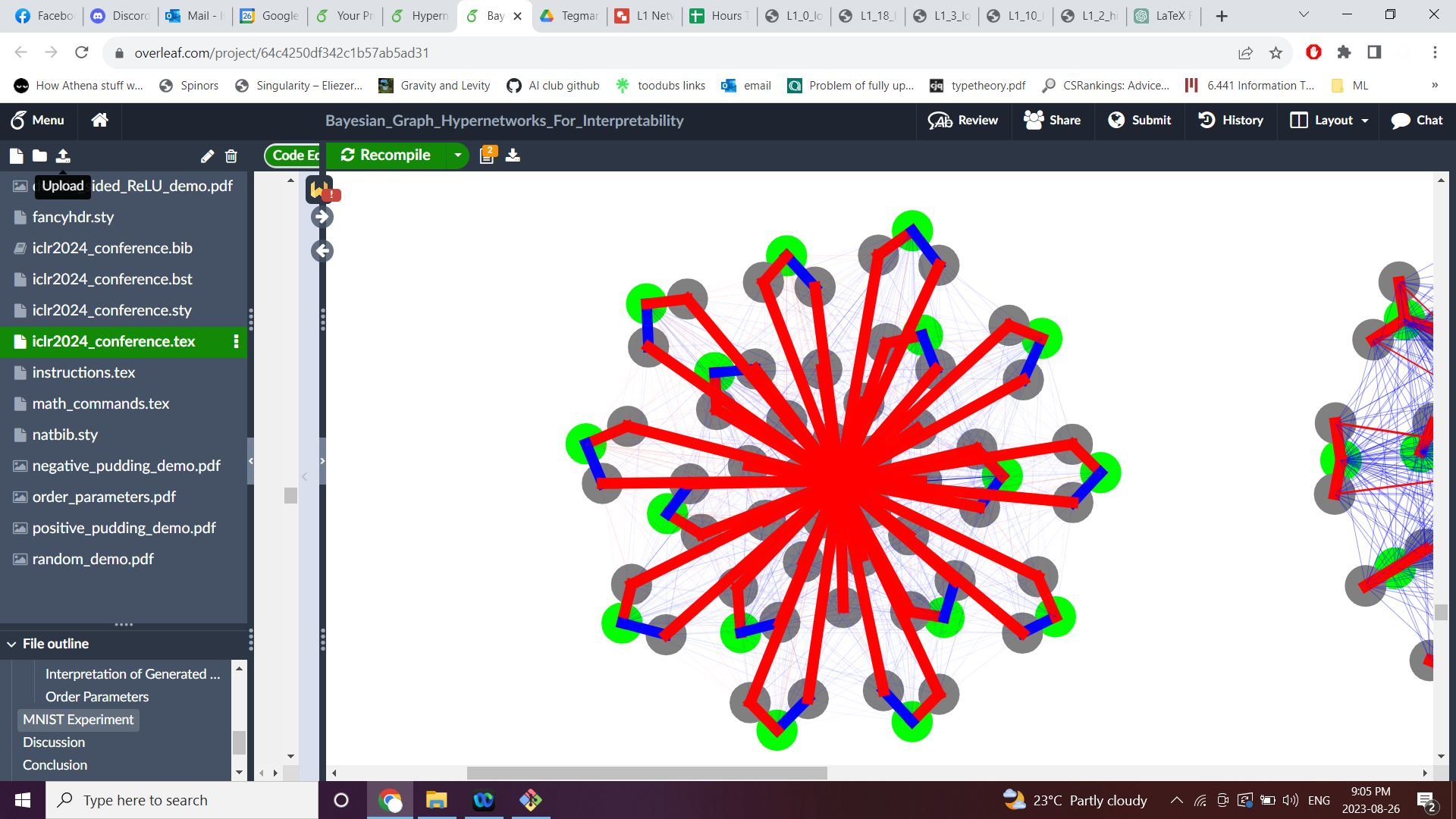
To read the algorithms out of these networks, the team used force-directed graph drawings, a visualization technique that arranges neurons on a plane according to their connection strengths, making symmetries visible at a glance. Three distinct algorithms emerged:
- The double-sided algorithm: The expected one. Build an absolute value from two ReLU neurons, one firing for positive inputs and one for negative, then sum across all dimensions. Clean, familiar, unsurprising.
- The pudding algorithm: Not expected. This method exploits a mathematical identity involving a limit as a constant approaches infinity, squeezing the L1 computation through a different algebraic path. It comes in two signed variants (“positive pudding” and “negative pudding”) which look visually distinct in the force-directed drawings.
- The convexity algorithm: Also unexpected. This one uses the convexity properties of the absolute value function through a completely different computational route.
Only the double-sided algorithm was anticipated before running the experiments. The other two emerged purely from what the hypernetwork chose to do.
Why It Matters
The real significance here isn’t that a hypernetwork found two new algorithms for computing absolute values. It’s what this reveals about the space of interpretable algorithms. Neural networks, even tiny ones, don’t necessarily rediscover human-familiar methods. They find their own paths, paths that are sometimes describable once you see them but that humans simply hadn’t thought to explore.
This has direct implications for mechanistic interpretability. Researchers currently hunt for structure in networks that weren’t designed to be interpretable. The MIT team’s work suggests an alternative: use hypernetworks to systematically generate and catalogue interpretable algorithms, building a library that could guide future decoding efforts.
The team also showed that their trained hypernetwork generalizes to input dimensions it never saw during training, constructing correct models for vector sizes outside the training distribution. That kind of systematic generalization suggests the hypernetwork has learned something genuinely algorithmic, not just memorized specific configurations.
There’s a bigger question lurking here, one the team explicitly raises: do large language models, when they solve math problems, rediscover human algorithms or invent alien ones? The pudding and convexity algorithms hint that the latter is entirely possible, even for elementary computations. Understanding those alien algorithms, rather than forcing networks into human-shaped molds, may be the key to truly trustworthy AI.
By training a hypernetwork to generate interpretable networks, the MIT team discovered two entirely new algorithms for computing absolute values that nobody thought to look for. Neural networks may harbor a richer algorithmic imagination than we’ve given them credit for.
IAIFI Research Highlights
This work connects the physics-inspired toolkit of complexity control and phase transitions to a core problem in AI safety and interpretability, treating algorithmic discovery as a structured search over a phase space of neural network behaviors.
The hypernetwork framework provides a systematic method for generating and cataloguing interpretable algorithms, advancing mechanistic interpretability research and offering new tools for understanding what computations neural networks actually perform.
The discovery of phase transitions between algorithmic regimes, triggered by varying β or by training dynamics, offers a statistical-mechanics lens for understanding how networks settle into computational strategies. This is a natural connection point between physics and machine learning.
Future work could scale this approach to more complex tasks and larger networks, potentially revealing whether language models use human-familiar or fundamentally alien algorithms. The paper is available at [arXiv:2312.03051](https://arxiv.org/abs/2312.03051) (Liao, Liu, Tegmark, MIT).
Original Paper Details
Generating Interpretable Networks using Hypernetworks
2312.03051
["Isaac Liao", "Ziming Liu", "Max Tegmark"]
An essential goal in mechanistic interpretability to decode a network, i.e., to convert a neural network's raw weights to an interpretable algorithm. Given the difficulty of the decoding problem, progress has been made to understand the easier encoding problem, i.e., to convert an interpretable algorithm into network weights. Previous works focus on encoding existing algorithms into networks, which are interpretable by definition. However, focusing on encoding limits the possibility of discovering new algorithms that humans have never stumbled upon, but that are nevertheless interpretable. In this work, we explore the possibility of using hypernetworks to generate interpretable networks whose underlying algorithms are not yet known. The hypernetwork is carefully designed such that it can control network complexity, leading to a diverse family of interpretable algorithms ranked by their complexity. All of them are interpretable in hindsight, although some of them are less intuitive to humans, hence providing new insights regarding how to "think" like a neural network. For the task of computing L1 norms, hypernetworks find three algorithms: (a) the double-sided algorithm, (b) the convexity algorithm, (c) the pudding algorithm, although only the first algorithm was expected by the authors before experiments. We automatically classify these algorithms and analyze how these algorithmic phases develop during training, as well as how they are affected by complexity control. Furthermore, we show that a trained hypernetwork can correctly construct models for input dimensions not seen in training, demonstrating systematic generalization.