
Hardware-accelerated Inference for Real-Time Gravitational-Wave Astronomy
Authors
Alec Gunny, Dylan Rankin, Jeffrey Krupa, Muhammed Saleem, Tri Nguyen, Michael Coughlin, Philip Harris, Erik Katsavounidis, Steven Timm, Burt Holzman
Abstract
The field of transient astronomy has seen a revolution with the first gravitational-wave detections and the arrival of multi-messenger observations they enabled. Transformed by the first detection of binary black hole and binary neutron star mergers, computational demands in gravitational-wave astronomy are expected to grow by at least a factor of two over the next five years as the global network of kilometer-scale interferometers are brought to design sensitivity. With the increase in detector sensitivity, real-time delivery of gravitational-wave alerts will become increasingly important as an enabler of multi-messenger followup. In this work, we report a novel implementation and deployment of deep learning inference for real-time gravitational-wave data denoising and astrophysical source identification. This is accomplished using a generic Inference-as-a-Service model that is capable of adapting to the future needs of gravitational-wave data analysis. Our implementation allows seamless incorporation of hardware accelerators and also enables the use of commercial or private (dedicated) as-a-service computing. Based on our results, we propose a paradigm shift in low-latency and offline computing in gravitational-wave astronomy. Such a shift can address key challenges in peak-usage, scalability and reliability, and provide a data analysis platform particularly optimized for deep learning applications. The achieved sub-millisecond scale latency will also be relevant for any machine learning-based real-time control systems that may be invoked in the operation of near-future and next generation ground-based laser interferometers, as well as the front-end collection, distribution and processing of data from such instruments.
Concepts
The Big Picture
Imagine you’re a lifeguard watching an ocean of noise, trying to spot a single ripple from a catastrophic cosmic event: two black holes colliding a billion light-years away. Now imagine you have milliseconds to sound the alarm before telescopes around the world lose their chance to catch the fading afterglow. That’s the challenge facing gravitational-wave astronomers every time LIGO and Virgo’s detectors pick up a signal buried in mountains of noise.
The stakes are real. When a pair of neutron stars spiraled together in 2017, the gravitational-wave alert triggered a global scramble of optical, X-ray, and gamma-ray telescopes that collectively changed our understanding of how heavy elements like gold are forged. The faster that alert goes out, the more of the story astronomers get to read.
The instruments making this possible, kilometer-scale laser interferometers vibrating at the level of a thousandth the diameter of a proton, are drowning in data. As LIGO and Virgo push toward their maximum design sensitivity and new detectors like KAGRA join the network, the computational load is expected to at least double over the next five years.
A team at MIT, the University of Minnesota, and Fermi National Accelerator Laboratory has built a new computing architecture that cuts the time needed to turn raw detector data into actionable astronomical alerts, using AI inference running on dedicated hardware accelerators (specialized chips designed to run AI calculations far faster than ordinary processors), delivered as a networked service.
Key Insight: By treating AI inference like a cloud service rather than a local computation, this team achieved sub-millisecond latency for gravitational-wave signal processing, fast enough to matter for multi-messenger astronomy and future detector operations.
How It Works
The core innovation is a shift in how the computing infrastructure is organized, not just how fast the chips run. Traditional gravitational-wave pipelines run neural networks directly on local CPU clusters. This team instead implemented an Inference-as-a-Service (IaaS) model. Think of it like a weather forecast API: instead of running weather models on your own computer, you send a request to a central server that does the heavy lifting and sends results back. Trained AI models live on a centralized server equipped with GPUs (graphics processors repurposed for AI) or FPGAs (programmable chips optimized for specific rapid calculations). Client software sends input data over HTTP or gRPC (standard network protocols, similar to how your browser requests a webpage), gets predictions back, and never has to manage the hardware directly.
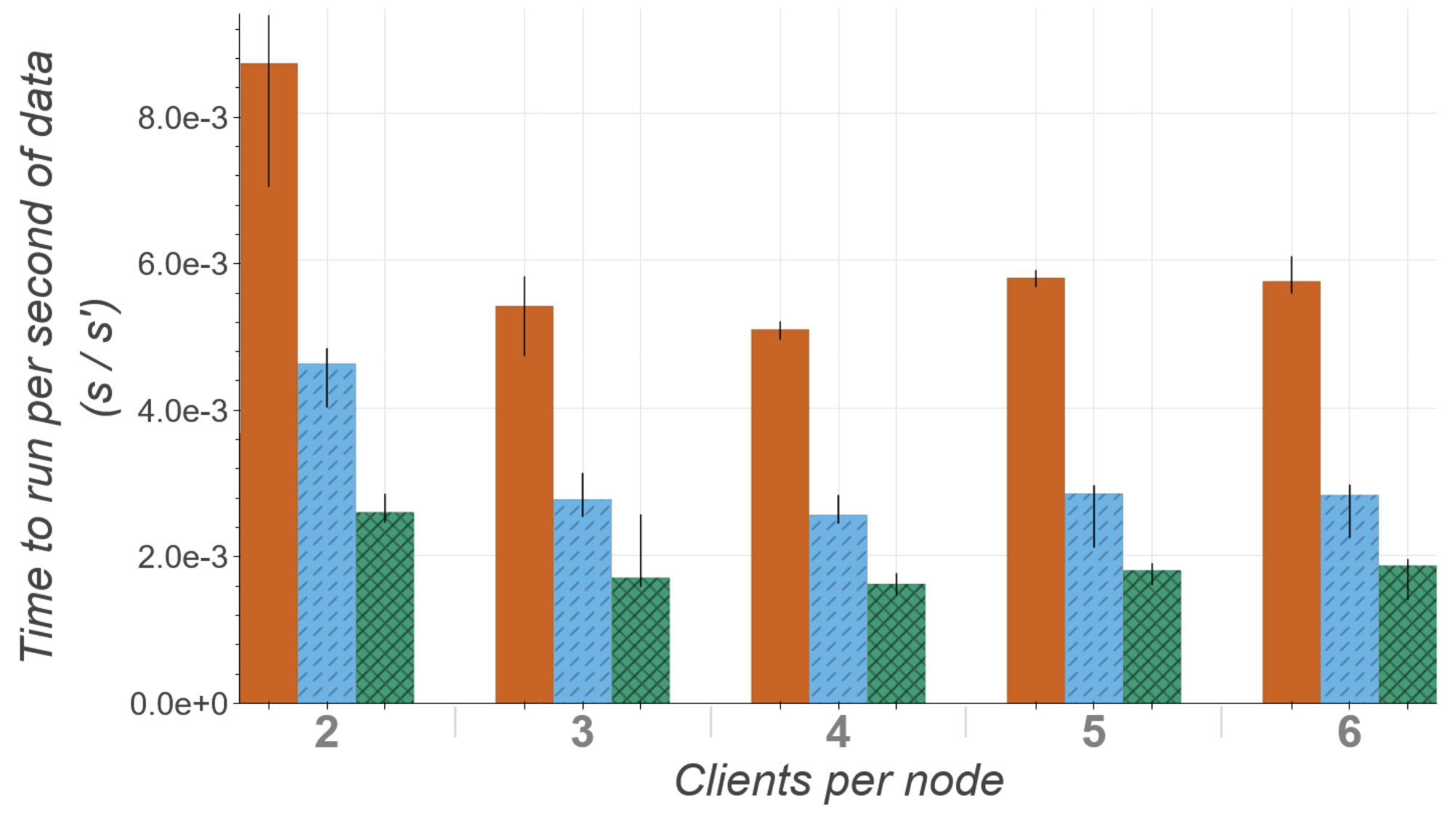
To test the system, the team ran two distinct deep learning models, each handling a different part of the detection problem:
- DeepClean — a 1D convolutional autoencoder (a neural network trained to identify and strip out repeating noise patterns) that removes instrumental noise from the data stream. LIGO instruments record data from roughly 200,000 auxiliary channels monitoring everything from seismic vibrations to power-line harmonics. DeepClean ingests 21 of these “witness” channels, sensors that pick up environmental disturbances but not gravitational waves, and learns to predict and subtract the noise they introduce into the main signal.
- BBHnet — a 1D convolutional neural network (a signal-processing AI that scans time-series data for characteristic patterns) trained to distinguish genuine binary black hole mergers from detector noise in the cleaned data. In a real observatory workflow, this is the classifier that would trigger an alert.
Running these models through the IaaS framework, the team measured end-to-end inference latency at the sub-millisecond scale. That’s fast enough for real-time control loops inside the detectors themselves, something conventional CPU-based approaches struggle to match.
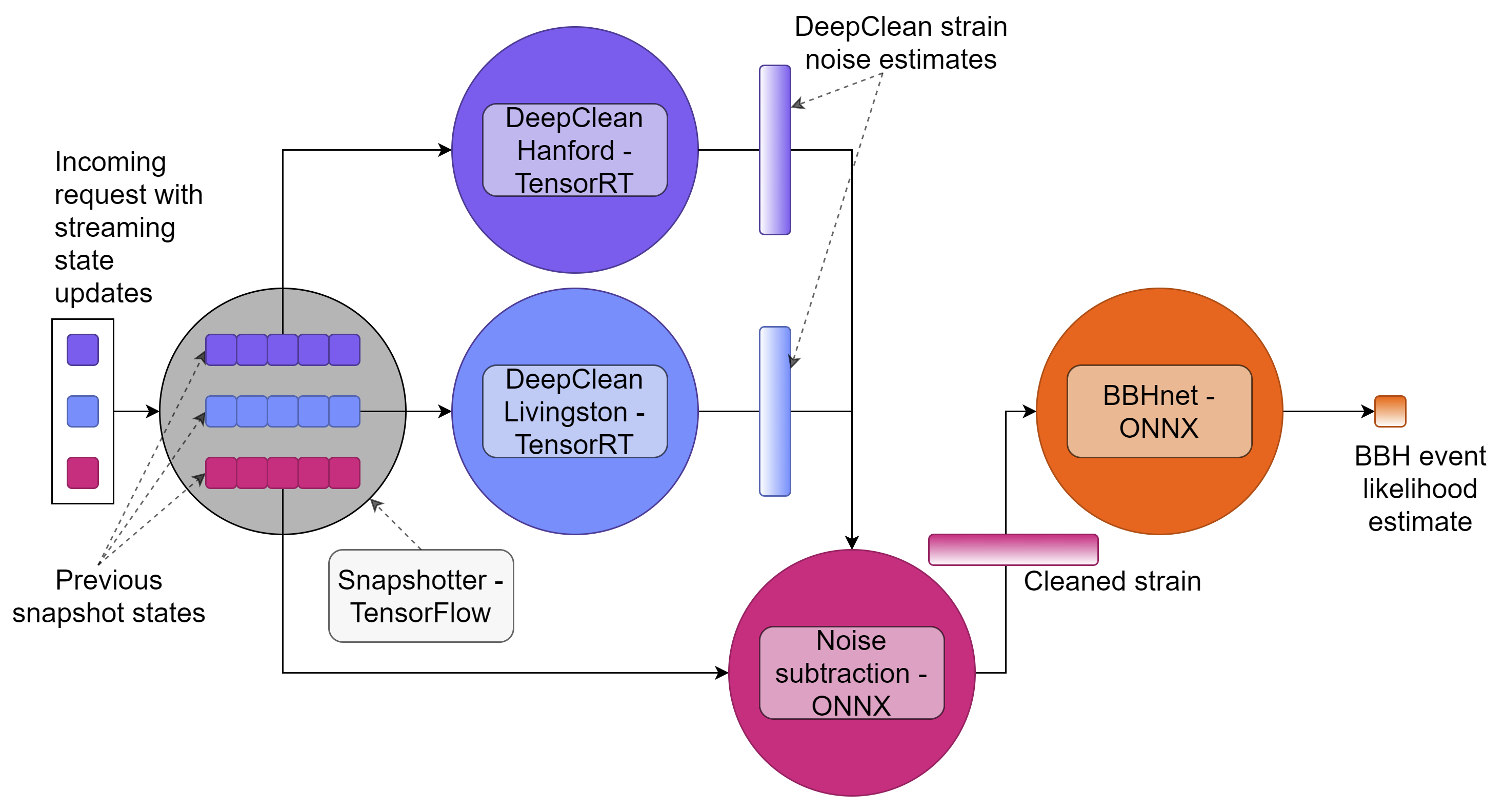
The architecture also solves a practical headache: peak-load management. Gravitational-wave analyses are bursty. During a candidate event, multiple pipelines simultaneously demand heavy computation. With IaaS, a shared pool of GPU resources serves all of them asynchronously, absorbing spikes that would overwhelm a fixed local cluster. The same server can be a commercial cloud instance during a surge or a dedicated on-premises machine during normal operations; the client pipelines don’t care either way.
Why It Matters
The immediate payoff is speed for multi-messenger astronomy, the practice of observing the same cosmic event simultaneously with gravitational waves and light across the spectrum. Every second between a detection and an alert is a second of fading kilonova light that astronomers don’t get back. (A kilonova is the brief, gold-forging glow produced when neutron stars collide.) Sub-millisecond AI inference shrinks that gap to negligible levels compared to other bottlenecks in the detection chain, like human review or network communication delays.
The deeper impact is architectural. As detector networks grow and neural network models become more complex (handling larger parameter spaces, spin effects, and sub-solar-mass objects), the IaaS model scales naturally. A new model gets deployed to the inference server; existing pipelines start using it without modification.
Decoupling model development from pipeline infrastructure could speed up machine learning adoption across gravitational-wave astronomy the way containerization (software packaging that lets programs run consistently anywhere) transformed software deployment. The framework also has next-generation detectors in mind, where real-time ML-based control systems may be essential for keeping instruments operating stably at design sensitivity.
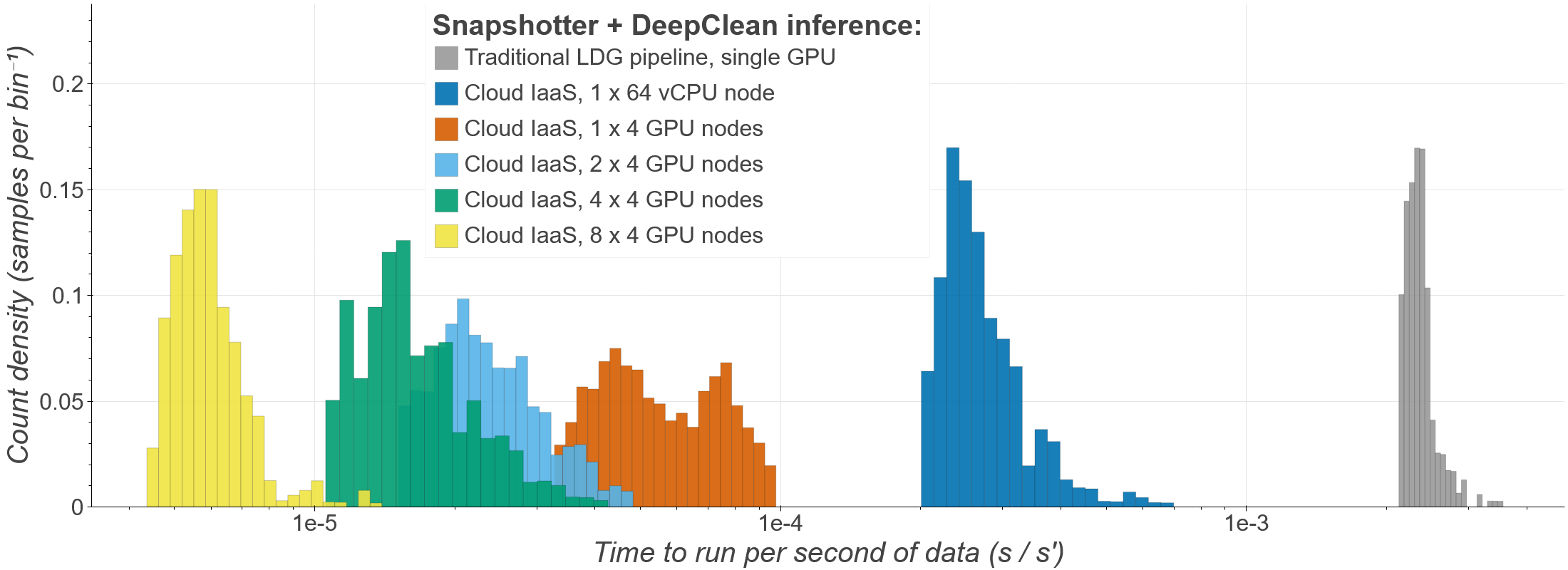
Bottom Line: Hardware-accelerated Inference-as-a-Service delivers sub-millisecond AI inference for gravitational-wave astronomy, providing a scalable, hardware-agnostic platform that could set the standard for how the next generation of detectors processes data in real time.
IAIFI Research Highlights
This work connects modern AI infrastructure (GPU-accelerated deep learning served as a networked API) with the operational demands of kilometer-scale laser interferometers, showing that cloud-computing paradigms can meet the precision timing requirements of gravitational-wave physics.
The IaaS deployment model enables heterogeneous hardware acceleration and asynchronous inference at sub-millisecond latency. The same approach applies to any latency-sensitive scientific computing context where real-time ML inference is needed.
Faster, scalable processing of LIGO/Virgo data directly supports multi-messenger astronomy, the observational strategy most likely to reveal new physics in compact object mergers, from neutron star equations of state to tests of general relativity.
Future work includes extending the IaaS framework to additional detector networks and next-generation instruments like the Einstein Telescope and Cosmic Explorer. The full paper is available at [arXiv:2108.12430](https://arxiv.org/abs/2108.12430).