
Harmonic Loss Trains Interpretable AI Models
Authors
David D. Baek, Ziming Liu, Riya Tyagi, Max Tegmark
Abstract
In this paper, we introduce harmonic loss as an alternative supervisory signal for training neural networks and large language models (LLMs). Harmonic loss differs from standard cross-entropy loss by (a) replacing the usual SoftMax normalization with a scale-invariant HarMax function and (b) computing logits via Euclidean distance rather than a dot product. Harmonic loss enables improved interpretability and faster convergence, owing to its scale invariance and finite convergence point by design, which can be interpreted as a class center. We first validate the performance of harmonic models across algorithmic, vision, and language datasets. Through extensive experiments, we demonstrate that models trained with harmonic loss perform better than standard models by: (a) enhancing interpretability, (b) requiring less data for generalization, and (c) reducing grokking. Moreover, we compare a GPT-2 model trained with harmonic loss to the standard GPT-2, illustrating that the harmonic model develops more interpretable representations. Looking forward, we believe harmonic loss may become a valuable tool in domains with limited data availability or in high-stakes applications where interpretability and reliability are paramount, paving the way for more robust and efficient neural network models.
Concepts
The Big Picture
Imagine trying to teach a student not by grading their exact answers, but by measuring how far off they are from the correct answer in a conceptual space. That’s the intuition behind a deceptively simple change to how neural networks learn, one that MIT researchers say could make AI models faster, more efficient, and more understandable.
Every modern neural network trained for classification relies on a mathematical function called cross-entropy loss to measure how wrong it is during training. Cross-entropy converts the model’s predictions into probabilities and compares them to the correct answer. For decades, it has been the unchallenged default, but it comes with hidden costs: models trained this way tend to be opaque, data-hungry, and prone to a frustrating quirk called grokking, where a model suddenly learns to generalize long after it appeared to memorize the training data.
A team from MIT (David Baek, Ziming Liu, Riya Tyagi, and Max Tegmark) has proposed a drop-in replacement called harmonic loss that addresses all three problems at once. The fix is elegant, grounded in geometry, and the results suggest it may be more than a marginal improvement.
Harmonic loss swaps the dot-product logits and SoftMax normalization of cross-entropy for Euclidean distances and a scale-invariant “HarMax” function, giving neural networks a geometric anchor that organizes their internal representations.
How It Works
The standard recipe for neural network classification: take the model’s final hidden representation, multiply it by a weight matrix to get “logits” (raw scores for each class), then squeeze those scores through SoftMax to produce probabilities. The problem? SoftMax is not scale-invariant: the actual size of the numbers matters, not just their relative proportions. As a result, model weights grow without bound during training, chasing an infinitely distant “perfect” answer. They keep getting bigger and never settle.
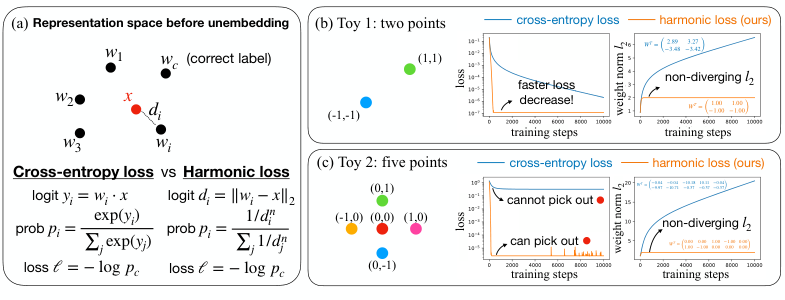
Harmonic loss makes two surgical changes:
-
Replace dot products with Euclidean distance. Instead of computing a logit as
w · x(how aligned is the weight vector with the representation?), harmonic loss computes||w - x||, the actual geometric distance between them. Smaller distance means higher predicted probability. -
Replace SoftMax with HarMax. The new normalization function assigns probability proportional to
1/d^n, wheredis the Euclidean distance andnis a tunable harmonic exponent. The recommended choice isn ≈ √D, whereDis the embedding dimension, keeping probability estimates stable as models scale up.
The payoff is real. Because harmonic loss measures distance to a finite target (the class center, the average location of all training examples for a given class in the model’s internal space), weight vectors converge to a stable location rather than growing toward infinity. The team calls this a finite convergence point: the harmonic model’s weights know when to stop.
Toy examples make this concrete. In a simple two-class problem, harmonic loss drives the loss down faster and weight magnitudes plateau while cross-entropy keeps growing unbounded. More striking: in a five-class problem where one data point sits among four others and cannot be linearly separated (no straight line can cleanly divide the classes), cross-entropy fails entirely. Harmonic loss solves it, because distance-based geometry doesn’t require linear separability.
Why It Matters
The researchers tested harmonic loss across a range of tasks (algorithmic datasets like modular arithmetic, MNIST digit classification, and a full GPT-2 language model) and found consistent advantages. Grokking shrank dramatically. Models needed fewer training examples to generalize well.
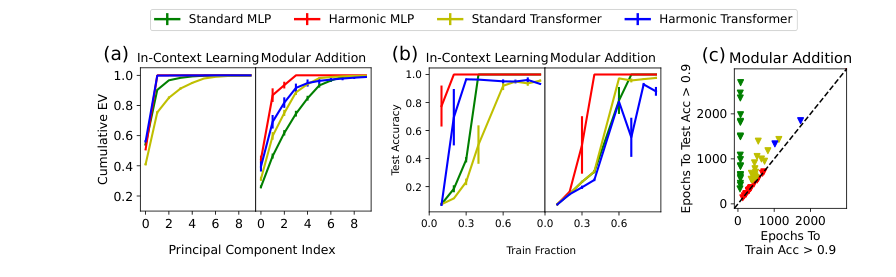
The biggest gain is interpretability. Because each weight vector converges to a class center in the model’s internal representational space, you can look at the weights and understand what they represent, without needing dedicated interpretability probes. The structure is built in, not reverse-engineered.
The AI research community has spent years trying to decode what neural networks have learned after training, a field called mechanistic interpretability. Harmonic loss suggests a different approach: build interpretability into the training objective itself. If weight vectors geometrically encode class identity, the model’s internals become a map rather than a black box.
This matters most in high-stakes domains like medicine, science, and finance, where a model that can’t explain its reasoning is fundamentally limited in how much trust it can earn.
Open questions remain. How does harmonic loss behave beyond GPT-2 scale? Does the harmonic exponent require careful tuning across different architectures? Can the geometric clarity of harmonic representations be exploited for even better interpretability tools downstream? Those are the obvious follow-up questions.
By swapping a 30-year-old default for a geometry-aware alternative, harmonic loss gives neural networks cleaner internal representations, faster generalization, and less grokking, suggesting that the choice of loss function is far more consequential than the field has assumed.
IAIFI Research Highlights
This work draws on geometric intuitions from physics (Euclidean distance, scale invariance, convergence to stable fixed points) to redesign a core component of modern machine learning, consistent with IAIFI's approach of applying physics thinking to AI.
Harmonic loss is a practical, drop-in improvement over cross-entropy that simultaneously enhances interpretability, data efficiency, and training stability across algorithmic, vision, and language tasks.
The interpretable geometric structure induced by harmonic loss could accelerate scientific discovery in domains where understanding the model's internal reasoning (not just its predictions) is essential.
Future work will explore harmonic loss at larger scales and in data-scarce scientific domains; the paper is available at [arXiv:2502.01628](https://arxiv.org/abs/2502.01628).