
Heterosynaptic Circuits Are Universal Gradient Machines
Authors
Liu Ziyin, Isaac Chuang, Tomaso Poggio
Abstract
We propose a design principle for the learning circuits of the biological brain. The principle states that almost any dendritic weights updated via heterosynaptic plasticity can implement a generalized and efficient class of gradient-based meta-learning. The theory suggests that a broad class of biologically plausible learning algorithms, together with the standard machine learning optimizers, can be grounded in heterosynaptic circuit motifs. This principle suggests that the phenomenology of (anti-) Hebbian (HBP) and heterosynaptic plasticity (HSP) may emerge from the same underlying dynamics, thus providing a unifying explanation. It also suggests an alternative perspective of neuroplasticity, where HSP is promoted to the primary learning and memory mechanism, and HBP is an emergent byproduct. We present simulations that show that (a) HSP can explain the metaplasticity of neurons, (b) HSP can explain the flexibility of the biology circuits, and (c) gradient learning can arise quickly from simple evolutionary dynamics that do not compute any explicit gradient. While our primary focus is on biology, the principle also implies a new approach to designing AI training algorithms and physically learnable AI hardware. Conceptually, our result demonstrates that contrary to the common belief, gradient computation may be extremely easy and common in nature.
Concepts
The Big Picture
Imagine you’re trying to teach someone to ride a bike, but you’re not allowed to tell them they’re leaning too far left. You can only nudge muscles they weren’t using at the moment they fell. Somehow, they still learn. This is roughly the puzzle neuroscientists have wrestled with for decades: how does the brain learn so effectively without the clean, explicit error signals that power modern AI?
Backpropagation, the algorithm behind virtually every deep learning system, works by measuring exactly how much each connection contributed to an error, then sending those precise signals backward through every layer. The brain almost certainly doesn’t do this. It can’t. Neurons only see local information: signals from their neighbors, not a global picture of what went wrong.
And yet biological brains master tasks that humble the most powerful AI systems, remain functional after injury, and generalize across conditions no engineer anticipated.
A new paper from MIT researchers Liu Ziyin, Isaac Chuang, and Tomaso Poggio proposes a striking answer: the brain might be performing gradient descent, the process of repeatedly nudging every connection in the direction that reduces errors, all along, through a mechanism no one fully appreciated. Their theory shows that heterosynaptic plasticity, a well-documented but underappreciated form of synaptic change, is sufficient to implement a broad class of gradient-based learning algorithms universally.
Key Insight: Almost any biological circuit that uses heterosynaptic plasticity, where synapses are modulated by signals from other pathways, can implement gradient descent without ever explicitly computing a gradient.
How It Works
The central character is heterosynaptic plasticity (HSP): a synapse changes strength not because of its own activity, but because of signals arriving from a different pathway. This contrasts with Hebbian plasticity (HBP), the classic “neurons that fire together, wire together” rule, where updates depend on correlated activity between the neurons a synapse directly connects.
The key architectural ingredient is deceptively simple: a neuron that receives two distinct signals at two different times. The authors call this a heterosynaptic circuit, and in its minimal form it’s just a neuron with two incoming pathways, one carrying sensory input and one carrying a learning or error signal. This two-signal structure appears throughout the brain.
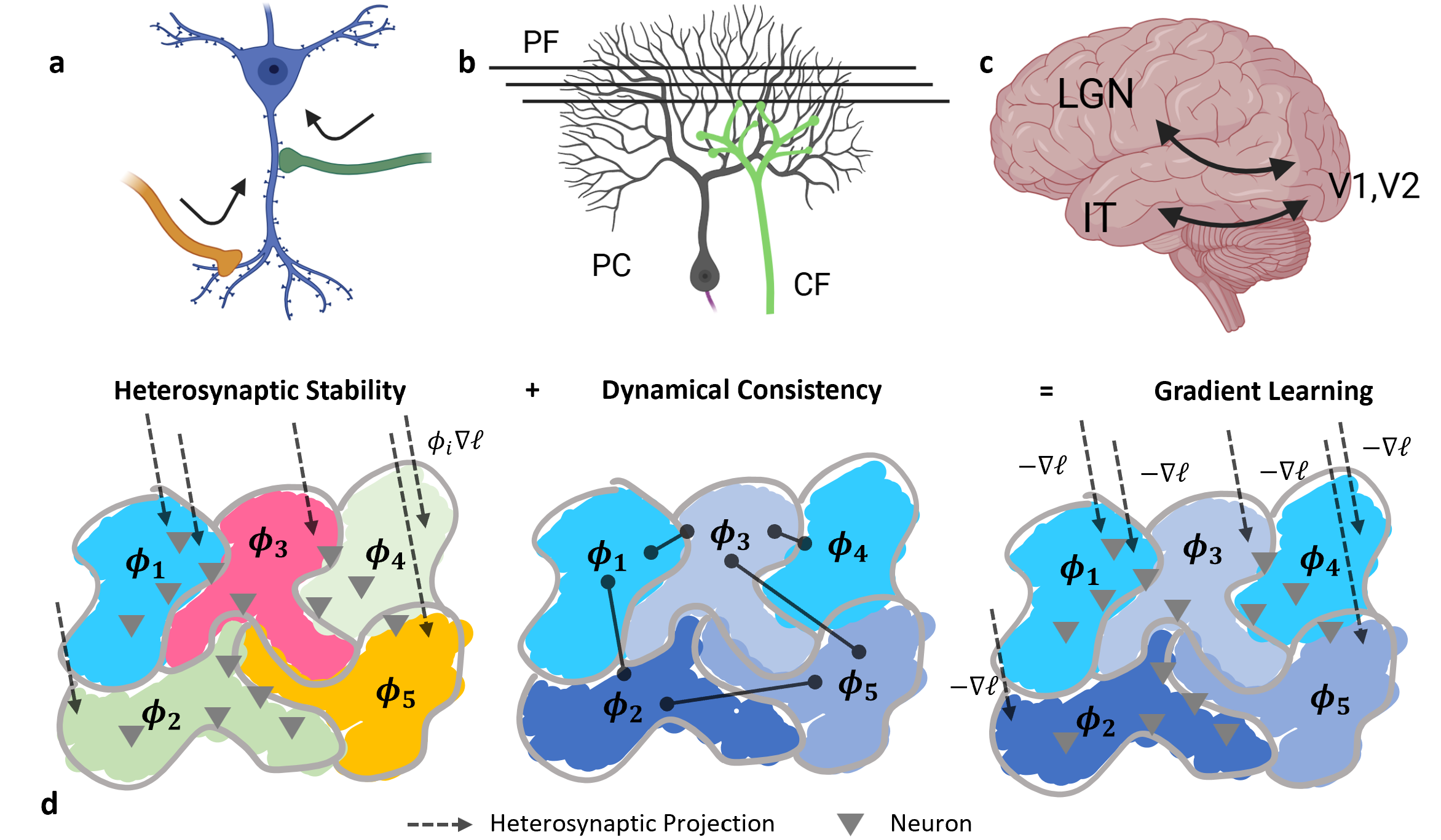
The cerebellum is a textbook example. Purkinje cells receive input from parallel fibers (sensory data) and climbing fibers (error or teaching signals), two separate pathways converging on the same neuron. The feedforward-feedback loops between visual cortex regions like V1 and V2 form the same motif at larger scale.
The theoretical machinery rests on two conditions:
- Heterosynaptic Stability (HS): One set of incoming connection strengths stabilizes, giving rise to a local quantity at each neuron called the consistency score (φ). Think of φ as a locally generated signal telling each neuron whether its recent updates are helping or hurting, and how aggressively to keep adjusting.
- Dynamical Consistency (DC): These local consistency scores propagate across the network, forcing global alignment in sign. A positive φ means “keep going”; a negative one means “flip.” When DC holds, the patchwork of local scores collectively implements a coherent, network-wide gradient signal.
Together, HS and DC are sufficient: the network performs gradient descent without any neuron ever computing a gradient. The gradient emerges from local interactions.
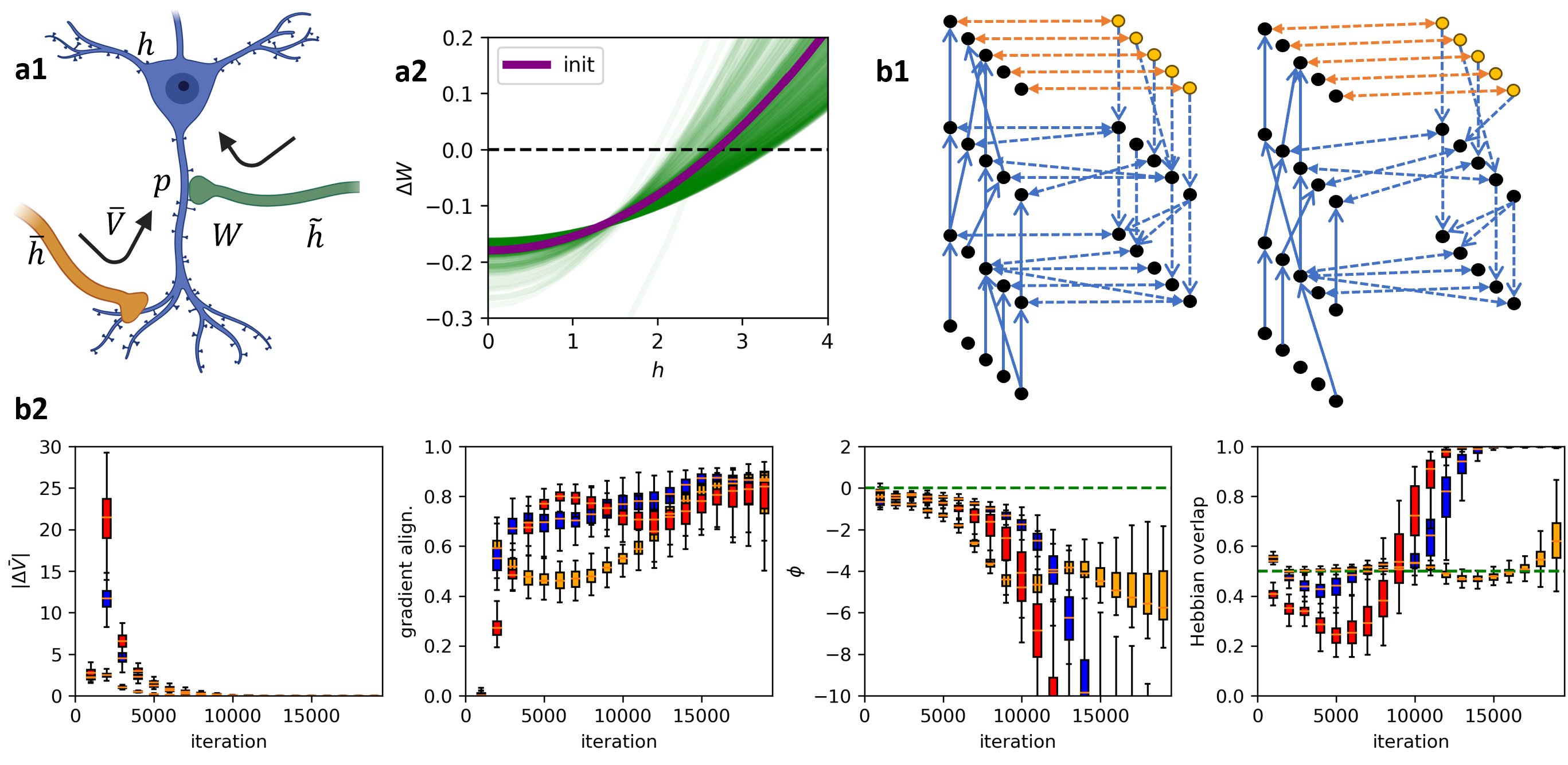
The authors demonstrate this across a wide range of architectures: structured networks inspired by the Kolen-Pollack algorithm, random amorphous networks, and everything in between. Standard gradient descent turns out to be the special case where the two pathways start symmetric, a natural initialization condition rather than a special design requirement.
Three simulation results reinforce the theory’s reach:
- HSP naturally explains metaplasticity (the observation that a neuron’s plasticity depends on prior experience, because the consistency score itself evolves with history).
- HSP explains the flexibility of biological circuits across radically different network topologies, from tightly structured to essentially random.
- Gradient-like learning can evolve from scratch via simple evolutionary dynamics, without any agent computing an explicit gradient, suggesting the brain may have stumbled onto gradient descent as a convergent solution.
Why It Matters
This result reframes a long-standing debate. The dominant assumption has been that gradient descent requires carefully engineered architecture and global information flow, making it implausible for biology. This paper argues the opposite: gradient computation may be “extremely easy and common in nature,” an almost inevitable consequence of the two-signal heterosynaptic motifs that evolution settled on for other reasons.
The unification is conceptually powerful. Four apparently distinct phenomena (Hebbian plasticity, anti-Hebbian plasticity, heterosynaptic plasticity, and metaplasticity) all emerge from the same underlying dynamics. Rather than treating them as separate mechanisms, the theory shows they are different faces of a single learning principle. Heterosynaptic plasticity is primary; Hebbian rules are an emergent byproduct.
The implications extend beyond neuroscience. If physical circuits implementing two-signal updates naturally perform gradient descent, this opens a path to physically learnable AI hardware, systems where learning emerges from material dynamics rather than digital simulation of backpropagation. It also points toward new training algorithms that are more robust to architectural variation and potentially more efficient.
Bottom Line: Heterosynaptic circuits, found throughout the brain from individual synapses to large cortical loops, are universal gradient machines. This discovery bridges biological and artificial learning in a single framework, suggesting that nature discovered gradient descent long before we did.
IAIFI Research Highlights
This work bridges theoretical neuroscience and machine learning by showing that biologically observed synaptic plasticity rules are mathematically equivalent to gradient-based optimization, grounding AI training in biology and vice versa.
The theory provides a principled foundation for gradient-free and physically implemented learning algorithms, potentially enabling AI hardware where learning emerges from circuit dynamics rather than explicit backpropagation.
By demonstrating that gradient computation can arise from local synaptic rules and evolutionary dynamics, the paper offers a new mechanistic explanation for how biological intelligence emerged and operates at the circuit level.
Future work may focus on neuromorphic hardware exploiting heterosynaptic motifs for energy-efficient learning; the full framework and proofs are available at [arXiv:2505.02248](https://arxiv.org/abs/2505.02248) (Ziyin, Chuang, Poggio, 2025).