
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Authors
Farah Fahim, Benjamin Hawks, Christian Herwig, James Hirschauer, Sergo Jindariani, Nhan Tran, Luca P. Carloni, Giuseppe Di Guglielmo, Philip Harris, Jeffrey Krupa, Dylan Rankin, Manuel Blanco Valentin, Josiah Hester, Yingyi Luo, John Mamish, Seda Orgrenci-Memik, Thea Aarrestad, Hamza Javed, Vladimir Loncar, Maurizio Pierini, Adrian Alan Pol, Sioni Summers, Javier Duarte, Scott Hauck, Shih-Chieh Hsu, Jennifer Ngadiuba, Mia Liu, Duc Hoang, Edward Kreinar, Zhenbin Wu
Abstract
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
Concepts
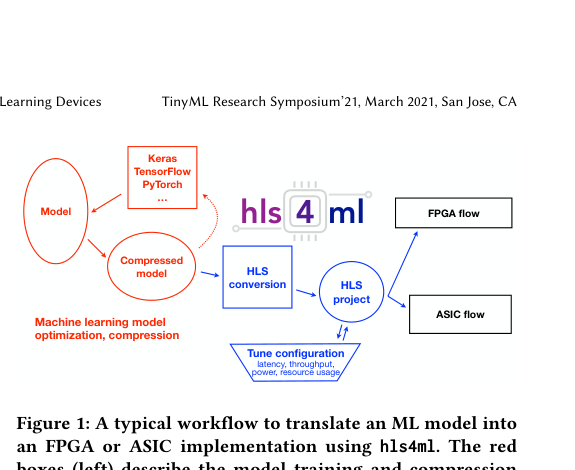
The Big Picture
Imagine you’re a physicist at CERN, staring down a firehose of data pouring out of the Large Hadron Collider at petabytes per second. Every proton collision lasts less than a nanosecond, and you have to decide, right now, whether this particular collision is interesting enough to save. You can’t send it to a cloud server. You can’t wait for a CPU to chew through it. You need a chip sitting right at the detector that can run a neural network in tens of nanoseconds and answer “keep” or “discard” before the next collision has already happened.
This is the world that hls4ml was built for. The problem isn’t just speed, though. It’s accessibility. Building custom chips for machine learning traditionally requires deep expertise in digital logic and low-level hardware programming. Most physicists have none of that. They know Python, TensorFlow, and their experiment.
hls4ml closes that distance. Developed by a consortium spanning Fermilab, CERN, MIT, and a dozen other institutions, it’s an open-source workflow that takes a trained neural network and translates it into instructions a chip can execute, ready to deploy on reconfigurable chips called FPGAs or fully custom silicon called ASICs at nanosecond latency with minimal power draw.
Key Insight: hls4ml lets domain scientists, not chip designers, deploy custom neural network accelerators on real hardware. A trained Python model becomes a running silicon implementation in a few lines of code.
How It Works
The core idea is high-level synthesis (HLS): describing hardware behavior in a high-level programming language like C++ rather than drawing out logic gates by hand. HLS tools compile that description into actual digital circuits. The results rival hand-crafted implementations, but the design cycles are far shorter.
Here’s the pipeline in practice:
- A scientist trains a neural network in TensorFlow or PyTorch, whatever they already know.
- hls4ml reads that trained model and generates an HLS description of the network’s calculations, translated into hardware terms.
- That HLS code gets compiled into a bitstream (the configuration file that programs an FPGA) or into an ASIC design ready for fabrication.
- The result runs on hardware with latencies measured in nanoseconds and power draws measured in milliwatts.
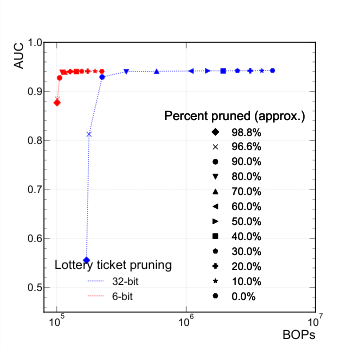
The capabilities described in this paper push hls4ml considerably further toward low-power deployments. The team introduced quantization-aware pruning (QAP), which combines two powerful compression techniques. Pruning removes weights, the learned numerical parameters inside a neural network, that contribute little to accuracy, setting them to zero and reducing computation. Quantization reduces the numerical precision of the remaining weights from full 32-bit floating-point numbers down to 8, 4, or even 2 bits.
Doing both together during training, rather than as an afterthought, lets the network learn to be compact and low-precision simultaneously. You squeeze far more performance out of constrained hardware this way.
For low-power operation, the team developed long pipeline kernels, a way of spacing out the chip’s calculations over more clock cycles rather than cramming one result out every cycle. Standard hls4ml optimizes for the shortest possible latency, but that’s power-hungry. Spreading the work across more cycles trades some speed for drastically reduced energy consumption, which matters in edge deployments where power budgets are measured in milliwatts.
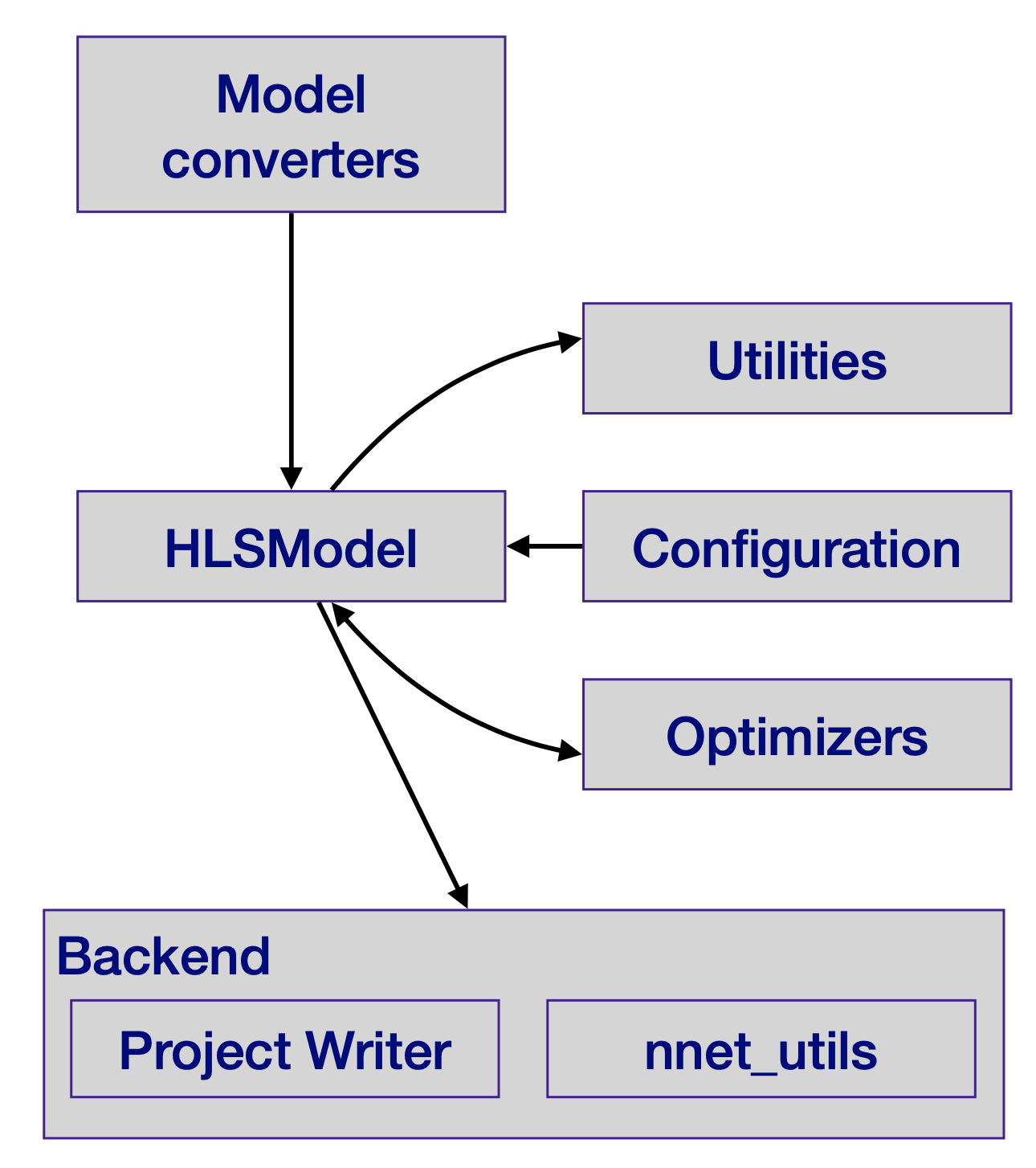
The workflow also now supports end-to-end integration with Xilinx’s Vitis Accel framework, embedding an hls4ml model directly into a complete FPGA system as part of a full data acquisition and processing chain. The team has also added an ASIC backend for custom silicon chips built for one specific job. That matters enormously for mass-deployment scenarios, like embedding tiny ML accelerators across thousands of detector readout chips simultaneously.
Why It Matters
The LHC is just one example. The Fermilab accelerator complex monitors hundreds of thousands of devices along miles of beamlines steering particle beams near the speed of light. Wildlife tracking networks deploy imaging sensors in remote environments with no power infrastructure. Agricultural sensing networks cover entire regions with battery-powered nodes. In all these contexts, the same challenge recurs: massive streams of sensor data that need local, intelligent filtering before they overwhelm bandwidth and storage.
hls4ml puts hardware-accelerated machine learning within reach of people who don’t have a chip design team on staff. The traditional path from trained model to deployed chip ran through expensive FPGA engineering groups and months of firmware development. By automating that translation and wrapping it in familiar Python APIs, hls4ml compresses that timeline to what the authors call reducing “time to science.” The framework is already used in LHC experiments for real-time trigger systems, and the extension toward low-power ASICs points toward a future where tiny, intelligent sensor nodes become a standard component of scientific instruments.
Open questions remain. The interactions between sparsity, quantization, and hardware efficiency are still being characterized, and ASIC workflows lack the mature toolchain of FPGA implementations. The distance between a trained Python model and a truly optimized chip design is narrower than it used to be, but it’s not zero. Hardware-software codesign is still an art, even if hls4ml has made it a more accessible one.
Bottom Line: hls4ml transforms trained neural networks into deployable hardware firmware with a few lines of Python, enabling real-time ML at nanosecond latency and milliwatt power budgets. It puts that capability directly in the hands of domain scientists who have never written a line of hardware description language.
IAIFI Research Highlights
hls4ml gives physicists, astronomers, and materials scientists a direct pipeline from trained neural networks to custom FPGA and ASIC implementations, no hardware engineering background required.
The framework introduces quantization-aware pruning as a first-class codesign technique for TinyML, enabling models to be jointly optimized for accuracy and hardware efficiency during training rather than after the fact.
Real-time neural network inference on hls4ml-powered hardware directly supports trigger and data acquisition systems at experiments like the LHC, where decisions about which particle collisions to record must be made in tens of nanoseconds.
Future work targets tighter ASIC integration and broader support for complex architectures like graph neural networks. The full paper is available at [arXiv:2103.05579](https://arxiv.org/abs/2103.05579) as part of the TinyML Research Symposium 2021 proceedings.