
How to build a consistency model: Learning flow maps via self-distillation
Authors
Nicholas M. Boffi, Michael S. Albergo, Eric Vanden-Eijnden
Abstract
Flow-based generative models achieve state-of-the-art sample quality, but require the expensive solution of a differential equation at inference time. Flow map models, commonly known as consistency models, encompass many recent efforts to improve inference-time efficiency by learning the solution operator of this differential equation. Yet despite their promise, these models lack a unified description that clearly explains how to learn them efficiently in practice. Here, building on the methodology proposed in Boffi et. al. (2024), we present a systematic algorithmic framework for directly learning the flow map associated with a flow or diffusion model. By exploiting a relationship between the velocity field underlying a continuous-time flow and the instantaneous rate of change of the flow map, we show how to convert any distillation scheme into a direct training algorithm via self-distillation, eliminating the need for pre-trained teachers. We introduce three algorithmic families based on different mathematical characterizations of the flow map: Eulerian, Lagrangian, and Progressive methods, which we show encompass and extend all known distillation and direct training schemes for consistency models. We find that the novel class of Lagrangian methods, which avoid both spatial derivatives and bootstrapping from small steps by design, achieve significantly more stable training and higher performance than more standard Eulerian and Progressive schemes. Our methodology unifies existing training schemes under a single common framework and reveals new design principles for accelerated generative modeling. Associated code is available at https://github.com/nmboffi/flow-maps.
Concepts
The Big Picture
Imagine navigating from New York to Los Angeles. One approach: follow every turn of the road, tracking your position moment by moment. Another: just know the answer (you end up in Los Angeles) and jump there directly.
Modern AI image generators work like the first driver. They simulate a physical process step by step, nudging random noise into a coherent picture through hundreds of tiny increments. Each step requires running the entire neural network again. The results look great, but generation is painfully slow.
For years, researchers have tried to teach AI models to take shortcuts, predicting the destination without tracing every mile of the journey. These consistency models can generate images 10 to 100 times faster. The catch: nobody had figured out a clean, unified way to train them.
Competing methods sprang up with different mathematical foundations and contradictory design choices. Many required expensive “teacher” networks, complete generative models trained first, then used to coach the faster student. The field was fragmented, and practitioners had no clear principles for building better models.
A team from Carnegie Mellon, Harvard, and the Courant Institute has changed that. Their paper lays out a unified training framework for consistency models and, in doing so, discovers a new class of training algorithms that outperforms all prior approaches.
Key Insight: By uncovering a geometric relationship called the “tangent condition,” the authors show how to train a fast, one-step generative model entirely from scratch (no pre-trained teacher required) and identify why a previously overlooked approach called Lagrangian self-distillation is the key to stable, high-quality training.
How It Works
The starting point is a flow model: a neural network trained to simulate how pure random noise gradually transforms into realistic data (images, proteins, weather patterns) over time. This transformation follows a differential equation, a rule specifying how each point moves at every instant. Solving it from start to finish requires many sequential steps, which is the computational bottleneck.
A flow map skips the step-by-step calculation entirely. Instead of tracking every infinitesimal step, the flow map directly maps any point at time $t$ to where it will be at time $s > t$. Learn this map well, and you can generate a sample in a single neural network call.
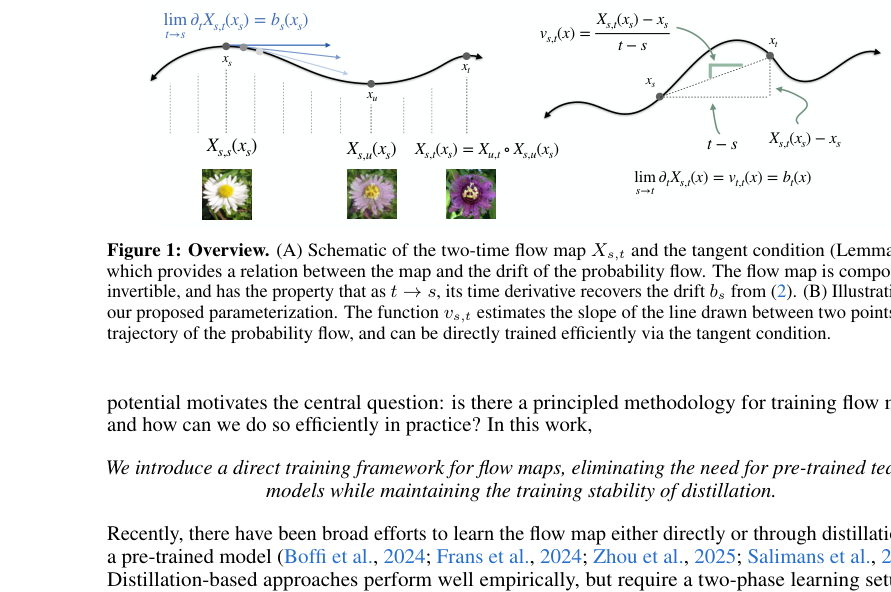
The central idea is the tangent condition, a mathematical relationship between the velocity field governing the flow and the rate of change of the flow map. If you know how fast a river flows at every point, you can deduce how a leaf’s downstream position changes as you nudge its starting point. The tangent condition is exactly this relationship, made rigorous for the probability flows used in generative modeling.
The tangent condition means you don’t need a separately trained teacher model: the flow map’s own implied velocity can serve as its own teacher. The authors call this self-distillation.
This insight yields three algorithmic families:
- Eulerian Self-Distillation (ESD): Computes the training target by measuring how the map changes across neighboring points in space. Closely related to existing consistency training methods.
- Progressive Self-Distillation (PSD): Builds up the map iteratively, starting with small steps and using each as a stepping stone to larger ones. Encompasses prior methods like shortcut models and mean flow.
- Lagrangian Self-Distillation (LSD): Follows the trajectory itself, tracking how the map changes along the path a particle actually takes, rather than across neighboring points in space.

The Lagrangian approach is the paper’s standout result. ESD amplifies noise by measuring spatial variation. PSD creates feedback loops that can spiral out of control. LSD dodges both failure modes by following actual trajectories instead.
On standard benchmarks (CIFAR-10, CelebA-64, AFHQ-64, and a synthetic checkerboard dataset), LSD consistently achieves lower error and more stable optimization than either alternative. The authors also show formally that both ESD and LSD have the correct unique minimizer: at convergence, they recover the true flow map, not an approximation.

This also solves a practical problem that has nagged the field. Earlier consistency models needed a pre-trained teacher, expensive to build and imposing a hard ceiling on what the student could learn. Self-distillation eliminates the teacher entirely, training from scratch with a loss function as simple as standard flow matching.
Why It Matters
The implications go well beyond image generation. Flow and diffusion models have become the backbone of scientific machine learning: protein structure prediction, climate modeling, drug discovery, real-time robotic control. In every case, slow inference is a real bottleneck.
A robot arm planning its next move cannot wait for a hundred network evaluations. A weather model running ensemble forecasts needs to generate thousands of scenarios quickly. Faster generative models with solid mathematical grounding could make these applications practical.
The paper’s deeper contribution is conceptual: it gives the field a map of the territory. By showing that every known training scheme for consistency models (consistency training, progressive distillation, shortcut models, mean flow, align your flow) is a special case of one unified framework, the authors reveal what the design space actually looks like.
Which combinations of Eulerian, Lagrangian, and Progressive ideas work best for which data types? Can Lagrangian methods extend to discrete domains like language? These are now tractable questions, not shots in the dark.
Bottom Line: This paper tackles the “how do you actually train a consistency model?” problem with a clean mathematical framework and a new class of algorithms (Lagrangian self-distillation) that beats existing methods on every standard benchmark, offering both a practical recipe for faster AI generators and the theoretical foundation the field has needed.
IAIFI Research Highlights
The paper draws on the Lagrangian vs. Eulerian distinction from fluid mechanics to resolve a core algorithmic problem in generative AI, a direct example of IAIFI's goal: applying physics intuition to machine learning problems.
The unified self-distillation framework provides the first principled foundation for training consistency models without pre-trained teachers, and the new Lagrangian algorithms set state-of-the-art results on multiple image generation benchmarks.
Faster, more principled generative models directly benefit scientific simulation tasks (from particle physics event generation to protein folding) where flow models are increasingly used as surrogate simulators.
Code is available at [github.com/nmboffi/flow-maps](https://github.com/nmboffi/flow-maps); future work may extend Lagrangian self-distillation to discrete modalities like text and to conditional generation settings. See [arXiv:2505.18825](https://arxiv.org/abs/2505.18825) by Boffi, Albergo, and Vanden-Eijnden (2025).