
I-Con: A Unifying Framework for Representation Learning
Authors
Shaden Alshammari, John Hershey, Axel Feldmann, William T. Freeman, Mark Hamilton
Abstract
As the field of representation learning grows, there has been a proliferation of different loss functions to solve different classes of problems. We introduce a single information-theoretic equation that generalizes a large collection of modern loss functions in machine learning. In particular, we introduce a framework that shows that several broad classes of machine learning methods are precisely minimizing an integrated KL divergence between two conditional distributions: the supervisory and learned representations. This viewpoint exposes a hidden information geometry underlying clustering, spectral methods, dimensionality reduction, contrastive learning, and supervised learning. This framework enables the development of new loss functions by combining successful techniques from across the literature. We not only present a wide array of proofs, connecting over 23 different approaches, but we also leverage these theoretical results to create state-of-the-art unsupervised image classifiers that achieve a +8% improvement over the prior state-of-the-art on unsupervised classification on ImageNet-1K. We also demonstrate that I-Con can be used to derive principled debiasing methods which improve contrastive representation learners.
Concepts
The Big Picture
Imagine you’re a cartographer handed dozens of hand-drawn maps of the same territory — each made by a different explorer, each with its own symbols, projections, and scales. Some show mountains, some rivers, some roads. They all describe the same landscape, but they look nothing alike. Your job is to prove they’re the same map.
That’s roughly the situation machine learning researchers have faced for the past decade. The field of representation learning — teaching computers to extract meaningful structure from raw data — has produced a zoo of competing algorithms.
Some methods teach a model to recognize that two versions of the same image are “the same thing,” even when one is flipped, cropped, or color-shifted — a technique called contrastive learning. Others compress complex data into something you can actually visualize — dimensionality reduction. Still others sort data into groups automatically — clustering algorithms. And then there’s supervised learning, the everyday workhorse, where a model learns to match each image to a human-provided label.
Each approach was invented separately, justified on its own terms, and still occupies its own corner of the literature. Connecting them felt almost hopeless.
A new paper from MIT, Google, and Microsoft argues that all these maps describe the same territory — and that a single equation draws all of them at once. The researchers call their framework I-Con, short for Information Contrastive Learning. It doesn’t just unify existing methods theoretically: it uses those connections to build state-of-the-art unsupervised image classifiers.
Key Insight: I-Con reveals that over 23 major machine learning algorithms — from t-SNE to CLIP to k-Means — are all secretly minimizing the same underlying objective: a divergence between two probability distributions, one learned and one provided as supervision.
How It Works
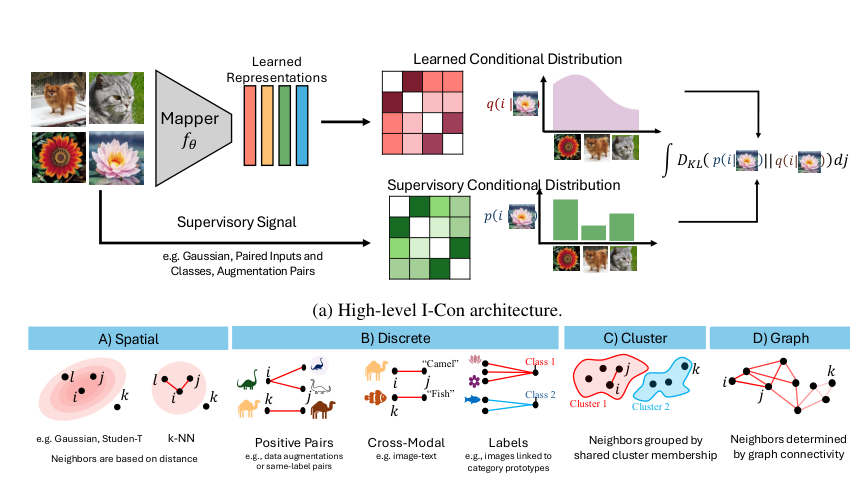
The central mathematical object in I-Con is deceptively simple. Given a data point, you can ask: which other data points is it related to, and how strongly? That question defines a conditional probability distribution — a ranked list of neighbors with scores for how closely related each one is. I-Con proposes that every representation learning method does one of three things with such distributions:
- Builds a supervisory distribution q based on external signals — class labels, image augmentations, graph structure, or nearest neighbors
- Builds a learned distribution p based on the model’s current embeddings — the compact numerical descriptions a neural network assigns to each data point
- Minimizes the KL divergence — a measure of dissimilarity between two distributions — between p and q, integrated across all data points
That’s it. One equation.
The flexibility is in how those distributions are defined. A Gaussian neighborhood — a smooth bell-curve of similarity scores — gives you SNE. A heavy-tailed Student-T distribution, which spreads scores more broadly to better separate distant points, gives you t-SNE. Uniform distributions over augmentation pairs give you SimCLR. Uniform distributions over class prototypes give you cross-entropy loss. Clustering-based distributions give you k-Means or spectral clustering.
Each choice of distribution snaps a different well-known algorithm into place like a puzzle piece.
The authors describe the result as a “periodic table” of representation learning — a grid where rows correspond to different learned distributions and columns to different supervisory signals. Every cell is a real, named algorithm. Some cells were previously unnamed, suggesting undiscovered methods live in the gaps.
The team proved 15 formal theorems connecting specific algorithms to I-Con, spanning from Pearson’s PCA (1901) to CLIP (2021). Then they used the framework to design something new. By treating image clusters as the learned distribution and contrastive pairs as the supervisory signal — a combination the table exposes as natural but previously unexplored — they built a novel unsupervised classification pipeline.
The results are striking. On ImageNet-1K, one of computer vision’s hardest benchmarks, their method achieves an 8 percentage point improvement over the previous state of the art in unsupervised classification — no labels used during training. The same approach also delivered gains of +3% on CIFAR-100 and +2% on STL-10.
I-Con also exposes a subtle flaw in contrastive learning: representation bias, where a model over-represents frequent patterns at the expense of rare ones. Because I-Con makes the loss structure explicit, the researchers derived a principled debiasing correction directly from the math — not a heuristic patch, but a natural consequence of the framework.
Why It Matters
Unification papers are rare in machine learning. The field moves fast and pragmatically — a new trick works, researchers use it, another trick appears, they use that too. Asking why a trick works, and whether it shares DNA with something from a different subfield, takes a different kind of patience. When it succeeds, the payoff is enormous.
I-Con’s immediate contribution is clarity. Researchers comparing contrastive learning to clustering, or dimensionality reduction to supervised classification, now share a common language. The framework turns “what happens if I borrow this supervisory signal and that learned distribution?” from guesswork into a systematic search — and as the +8% ImageNet result shows, the gaps in the table contain real treasures.
The longer-term implications run deeper. Physics has benefited enormously from unification: Maxwell’s equations unified electricity and magnetism; general relativity unified space, time, and gravity. Each unification didn’t just simplify textbooks; it revealed new phenomena and enabled new predictions. I-Con suggests that representation learning may be entering a similar moment, where the apparent diversity of techniques was always masking a simpler underlying structure.
Bottom Line: I-Con proves that 23+ machine learning algorithms are all doing the same thing in disguise — and by making that structure explicit, it achieves an 8% breakthrough on unsupervised ImageNet classification while opening a systematic path to inventing better algorithms.
IAIFI Research Highlights
I-Con's information-geometric framework echoes the kind of unification sought in theoretical physics — finding a single principle beneath apparent diversity — and applies it directly to the mathematical foundations of modern AI.
By unifying over 23 representation learning algorithms under one KL-divergence objective, I-Con gives researchers a principled basis for designing new loss functions, achieving state-of-the-art unsupervised ImageNet accuracy with an 8% gain over prior methods.
The framework's information-theoretic foundation draws on concepts from statistical mechanics and information geometry, revealing deep mathematical connections between learned representations and physical theories of inference.
Future work may systematically explore the "empty cells" in I-Con's periodic table to discover novel training objectives; the paper appeared at ICLR 2025 and the project page is at [arXiv:2504.16929](https://arxiv.org/abs/2504.16929).