
Implicit Augmentation from Distributional Symmetry in Turbulence Super-Resolution
Authors
Julia Balla, Jeremiah Bailey, Ali Backour, Elyssa Hofgard, Tommi Jaakkola, Tess Smidt, Ryley McConkey
Abstract
The immense computational cost of simulating turbulence has motivated the use of machine learning approaches for super-resolving turbulent flows. A central challenge is ensuring that learned models respect physical symmetries, such as rotational equivariance. We show that standard convolutional neural networks (CNNs) can partially acquire this symmetry without explicit augmentation or specialized architectures, as turbulence itself provides implicit rotational augmentation in both time and space. Using 3D channel-flow subdomains with differing anisotropy, we find that models trained on more isotropic mid-plane data achieve lower equivariance error than those trained on boundary layer data, and that greater temporal or spatial sampling further reduces this error. We show a distinct scale-dependence of equivariance error that occurs regardless of dataset anisotropy that is consistent with Kolmogorov's local isotropy hypothesis. These results clarify when rotational symmetry must be explicitly incorporated into learning algorithms and when it can be obtained directly from turbulence, enabling more efficient and symmetry-aware super-resolution.
Concepts
The Big Picture
Imagine trying to teach a student to recognize a cat, but you only ever show them cats lying on their sides. They’ll struggle to identify a cat sitting upright. Train them instead on billions of photographs from every conceivable angle, and they develop rotational understanding almost automatically. Not because you drilled it in, but because the data itself was the teacher.
Something similar is happening inside AI models trained to simulate turbulence. Turbulence, the chaotic swirling motion of fluids that governs everything from jet engine combustion to ocean currents, is one of the most computationally expensive phenomena in physics to simulate. Capturing it accurately requires supercomputers running for weeks.
Machine learning offers a shortcut: train a neural network to upscale a coarse, cheap simulation into a fine-grained one. But these networks face a deep challenge. Physics doesn’t care which direction you’re looking. A swirling eddy looks identical whether you rotate your view 90 or 180 degrees, yet standard AI models don’t automatically know this. Models that ignore rotational symmetry produce physically inconsistent results.
A team from MIT has now shown that for turbulent flows, you may not need to engineer rotational awareness into your model at all. The physics does it for you.
Key Insight: Turbulence’s statistical isotropy acts as natural data augmentation, teaching standard convolutional neural networks rotational equivariance without any explicit engineering, but only when and where the turbulence is sufficiently isotropic.
How It Works
The researchers focused on super-resolution (SR): reconstructing a high-resolution turbulent velocity field from a coarse, low-resolution version. Their model is a compact multi-scale convolutional neural network (CNN), a standard image-processing architecture with layers that analyze patterns at multiple spatial scales. It progressively upsamples 3D velocity fields using trilinear interpolation and convolutional refinement stages. No exotic architecture. No special symmetry-aware design.
The property under investigation is rotational equivariance: if you rotate an input, the output should rotate by the same amount. A perfectly equivariant model satisfies f(g·U) = g·f(U) for any rotation g. The team measured violations using equivariance error: the average pointwise difference between rotating-then-predicting versus predicting-then-rotating, computed across all 24 rotations of the octahedral symmetry group (the distinct ways to rotate a cube onto itself).
What gives this result its force is the experimental design. The team sampled 3D subdomains from a turbulent channel-flow simulation in the Johns Hopkins Turbulence Database, targeting two regions:
- Boundary-layer subdomains near the channel walls, where turbulence is strongly anisotropic (the flow has a clear preferred direction)
- Mid-plane subdomains at the channel center, where turbulence is more isotropic (statistically similar in all directions)
If isotropy genuinely acts as implicit rotational augmentation, models trained on mid-plane data should develop better equivariance even without seeing explicitly rotated examples.
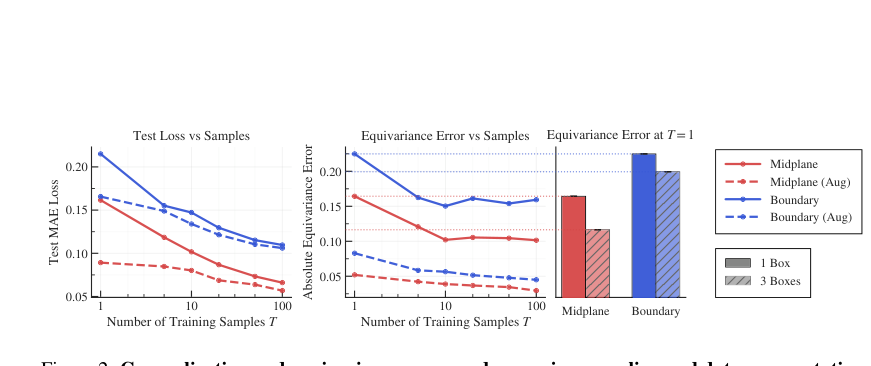
That’s exactly what happened. Mid-plane models consistently achieved lower equivariance error than boundary-layer models. The more training data used (more timesteps or more spatial subdomains), the lower the error fell. More data means more rotational variety encountered during training, which means better implicit symmetry learning.
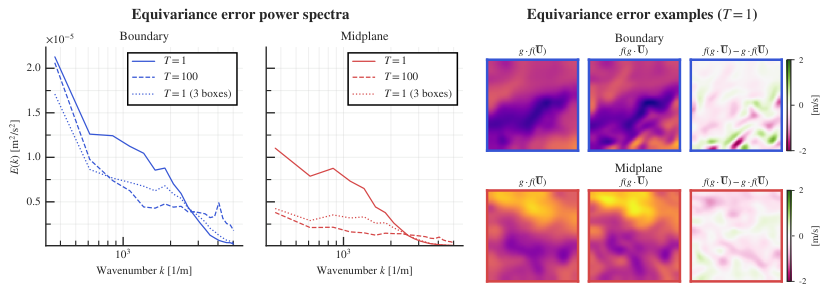
The third finding may be the most striking. Equivariance error is scale-dependent: the network makes larger rotational errors at large spatial scales than at small ones, regardless of training data source. This directly mirrors Kolmogorov’s local isotropy hypothesis, which predicts that small-scale eddies behave isotropically even when large-scale flow is strongly directional. The physics of turbulence is literally visible in the network’s error structure.
Why It Matters
The machine learning community has invested heavily in equivariant neural networks with symmetry mathematically baked in, guaranteeing rotational consistency regardless of the input. These are powerful, but they add architectural complexity and computational overhead.
This paper’s message is more pragmatic: if your training data is already statistically symmetric, your model will learn the symmetry implicitly. You don’t always need the extra machinery.
The practical payoff is real. Turbulence super-resolution is increasingly used in climate modeling, aerodynamics, and plasma physics. In all of these, high-resolution simulation is essential but expensive. Knowing when you need a symmetry-aware architecture (strongly anisotropic boundary flows) versus when a standard CNN suffices (isotropic bulk turbulence) lets practitioners make smarter design choices.
The results also sharpen a theoretical point: to generalize to rotated inputs, you need either explicit augmentation or naturally isotropic training data. There is no third option.
Open questions remain. The study used a specific channel-flow geometry and a fixed architecture. Whether the findings extend to more complex flows like combustion, magnetohydrodynamics, or atmospheric turbulence has yet to be tested. The connection between Kolmogorov’s hypothesis and learned equivariance also invites deeper theoretical treatment.
Bottom Line: Standard neural networks quietly learn the rotational symmetry of turbulence when training data is sufficiently isotropic. The result connects a 1941 physics hypothesis to modern machine learning practice and tells practitioners exactly when they can skip expensive symmetry-aware architectures.
IAIFI Research Highlights
The work connects Kolmogorov's classical local isotropy hypothesis to equivariance properties of learned neural networks, showing that statistical physics principles govern how AI models internalize symmetry.
The study provides a principled basis for deciding when symmetry-equivariant architectures are necessary versus when standard CNNs suffice, enabling more computationally efficient models for physical simulation tasks.
By quantifying where and how rotational symmetry emerges in data-driven turbulence models, the paper improves physical consistency of ML-based super-resolution for fluid dynamics, with direct relevance to fusion energy, climate science, and aerodynamics.
Future work will likely extend these findings to more complex geometries and stronger anisotropy regimes. The paper is available at [arXiv:2509.20683](https://arxiv.org/abs/2509.20683).
Original Paper Details
Implicit Augmentation from Distributional Symmetry in Turbulence Super-Resolution
2509.20683
["Julia Balla", "Jeremiah Bailey", "Ali Backour", "Elyssa Hofgard", "Tommi Jaakkola", "Tess Smidt", "Ryley McConkey"]
The immense computational cost of simulating turbulence has motivated the use of machine learning approaches for super-resolving turbulent flows. A central challenge is ensuring that learned models respect physical symmetries, such as rotational equivariance. We show that standard convolutional neural networks (CNNs) can partially acquire this symmetry without explicit augmentation or specialized architectures, as turbulence itself provides implicit rotational augmentation in both time and space. Using 3D channel-flow subdomains with differing anisotropy, we find that models trained on more isotropic mid-plane data achieve lower equivariance error than those trained on boundary layer data, and that greater temporal or spatial sampling further reduces this error. We show a distinct scale-dependence of equivariance error that occurs regardless of dataset anisotropy that is consistent with Kolmogorov's local isotropy hypothesis. These results clarify when rotational symmetry must be explicitly incorporated into learning algorithms and when it can be obtained directly from turbulence, enabling more efficient and symmetry-aware super-resolution.