
Inferring Transition Dynamics from Value Functions
Authors
Jacob Adamczyk
Abstract
In reinforcement learning, the value function is typically trained to solve the Bellman equation, which connects the current value to future values. This temporal dependency hints that the value function may contain implicit information about the environment's transition dynamics. By rearranging the Bellman equation, we show that a converged value function encodes a model of the underlying dynamics of the environment. We build on this insight to propose a simple method for inferring dynamics models directly from the value function, potentially mitigating the need for explicit model learning. Furthermore, we explore the challenges of next-state identifiability, discussing conditions under which the inferred dynamics model is well-defined. Our work provides a theoretical foundation for leveraging value functions in dynamics modeling and opens a new avenue for bridging model-free and model-based reinforcement learning.
Concepts
The Big Picture
Imagine you’ve spent months studying a chess grandmaster’s game notes: the annotations, the evaluations, the “this position is worth +2.3” marks scattered across every move. Now imagine you could reconstruct the rules of chess itself just from those notes, without ever watching a single game. That’s roughly what this paper pulls off, but for AI agents learning to navigate unknown environments.
In reinforcement learning, AI agents learn by doing: they explore an environment, collect rewards, and gradually figure out the best strategy. There are two main camps. Model-free methods learn by experience alone, building up a sense of which situations are good or bad, treating the environment as a black box. Model-based methods go further, learning an explicit model of how the environment works, which lets the agent plan ahead, simulate futures, and generally learn more from less experience.
The catch? Building that world model is hard, expensive, and error-prone.
Jacob Adamczyk, a physicist at UMass Boston working with IAIFI, noticed something hiding in plain sight. The value function (a score sheet that model-free agents build up, tracking how good each situation is expected to be) might secretly contain everything needed to reconstruct how the environment works. This paper turns that intuition into a rigorous method for extracting a world model directly from a fully trained value function, with no separate model-learning required.
Key Insight: A fully trained value function doesn’t just tell you what’s valuable. It implicitly encodes how the world works. By rearranging the Bellman equation, you can read that world model back out.
How It Works
The foundation of nearly all RL algorithms is the Bellman equation, a recursive relationship stating that the value of a state today equals the immediate reward plus the discounted value of wherever you end up tomorrow: V(s) = r(s,a) + γ·V(s’). Every time an agent trains, it’s essentially solving this equation until the value function stabilizes.
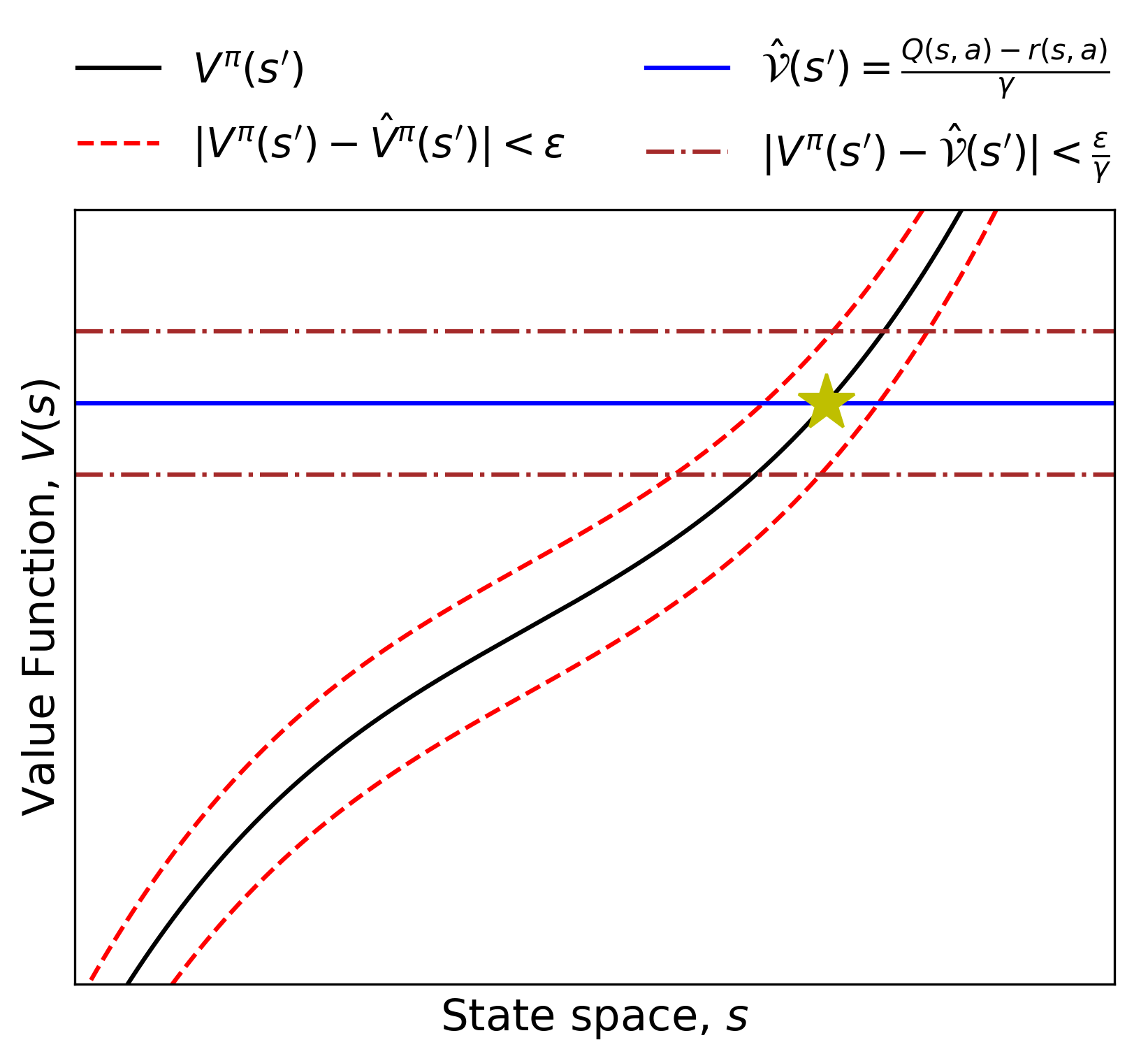
Adamczyk’s key move is algebraic but profound: flip the equation around. If you know V(s), r(s,a), and γ, and want to find s’ (the next state), you’re looking for the state whose value satisfies V(s’) = [V(s) - r(s,a)] / γ. The next state is whichever state the value function maps to that specific target number. The dynamics model falls out of a simple inversion.
This leads to a clean inference procedure:
- Train a value function using any standard model-free RL algorithm until convergence.
- Compute the target value for the next state: V_target = (V(s) - r(s,a)) / γ, using the known reward and discount factor.
- Invert the value function to find the state s’ that achieves this target value (the predicted next state).
- Use the inferred dynamics to plan, transfer to new tasks, or initialize further training.
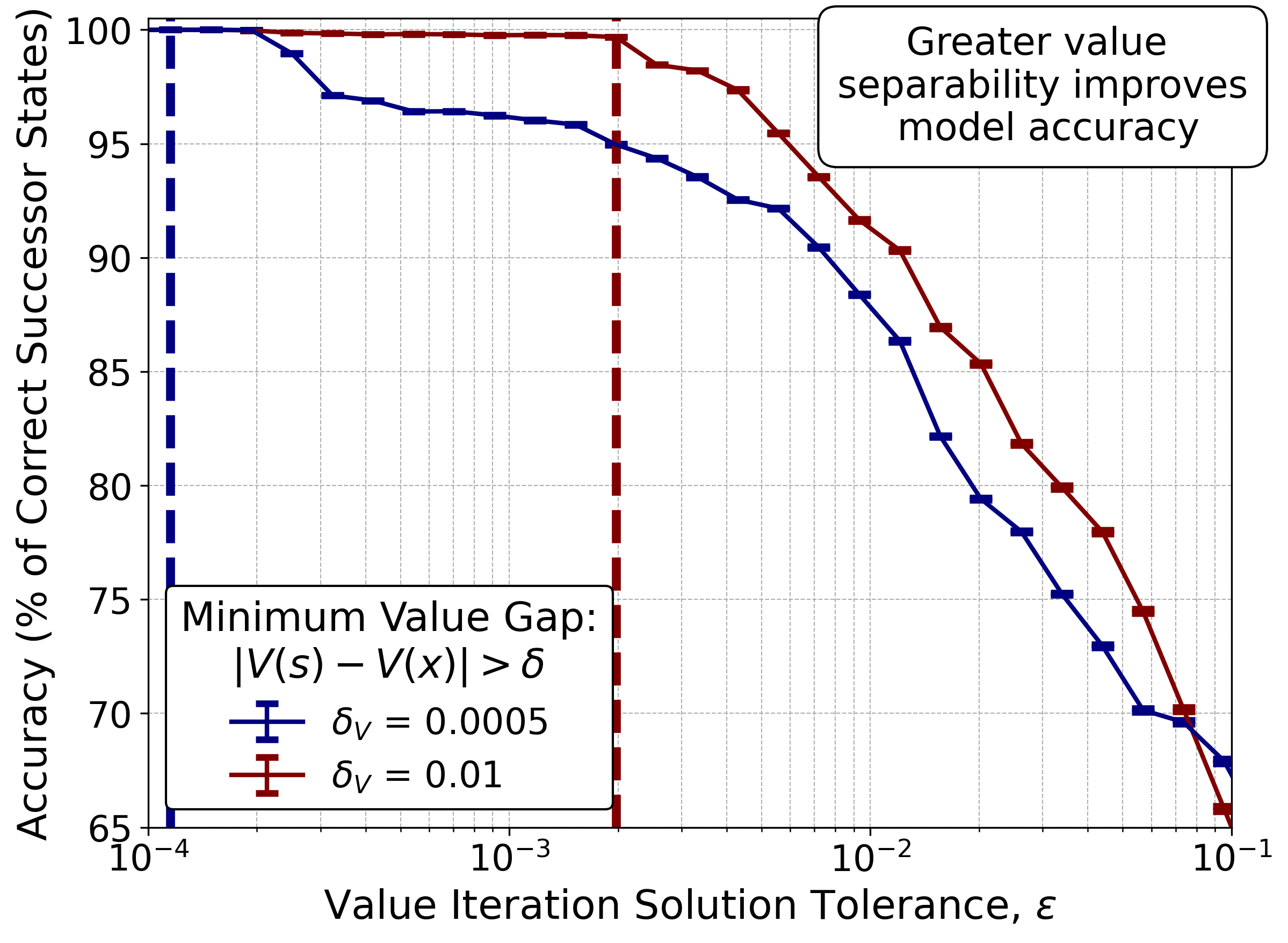
The hard part is step 3, where the paper gets mathematically careful. Inverting a function requires it to be injective (one-to-one): no two different states should map to the same value. If they do, you can’t tell which state is the real next state.
Adamczyk formalizes this through reverse Lipschitz continuity, requiring the value function to have steep enough gradients that nearby states always produce distinguishably different values. A larger reverse Lipschitz constant means sharper discrimination and more accurate dynamics recovery.
The paper also derives error bounds: if your value function has approximation error (as all practical neural network approximations do), how far off will your inferred dynamics be? The answer depends on the reverse Lipschitz constant. Steeper value functions tolerate more approximation error before the inferred dynamics degrade.
Why It Matters
This work quietly dissolves a boundary that has organized RL research for decades. Model-free and model-based methods have largely developed as separate communities, with different algorithms, different intuitions, and different tradeoffs. Showing that model-free solutions already contain model-based information suggests the divide may be artificial, or at least more porous than assumed.
The practical implications are significant for multi-task and offline RL. In robotics, the physical dynamics of a robot arm stay constant across tasks; only the goal changes. If you’ve trained a value function for “pick up the red block,” Adamczyk’s method could extract a dynamics model and immediately apply it to “pick up the blue block,” without any additional environment interaction.
In offline RL, where an agent must learn from a fixed dataset with no further exploration, this provides a path to extracting more utility from pre-collected solutions, analogous to online finetuning but without touching the real environment at all.
Open questions remain. The current framework assumes deterministic dynamics: a single next state for every state-action pair. Real environments are stochastic, and extending inversion to probability distributions over next states requires density modeling, a significantly harder problem. The identifiability conditions also assume the value function is sufficiently injective, which may not hold in environments with large flat regions or symmetries.
Bottom Line: A trained value function secretly holds a map of the world that created it. This paper shows how to read that map, opening a new path toward more adaptable, sample-efficient AI agents that don’t need to learn the rules from scratch every time the game changes.
IAIFI Research Highlights
This work brings the physicist's instinct for elegant reformulation (rearranging equations to reveal hidden structure) directly to bear on a core AI problem, treating the Bellman equation as a source of dynamical information rather than just a training target.
The paper provides a theoretical bridge between model-free and model-based reinforcement learning, showing that value functions implicitly encode environment dynamics and offering a rigorous method for extracting them.
By establishing formal identifiability conditions and error bounds for dynamics inference, this work contributes mathematical tools, particularly reverse Lipschitz analysis, that could inform how AI systems model physical processes in scientific domains.
Future work must tackle stochastic environments and the density-modeling challenge they pose. The paper is available at [arXiv:2501.09081](https://arxiv.org/abs/2501.09081), by Jacob Adamczyk (IAIFI/UMass Boston).