
Interpretable Machine Learning for Kronecker Coefficients
Authors
Giorgi Butbaia, Kyu-Hwan Lee, Fabian Ruehle
Abstract
We analyze the saliency of neural networks and employ interpretable machine learning models to predict whether the Kronecker coefficients of the symmetric group are zero or not. Our models use triples of partitions as input features, as well as b-loadings derived from the principal component of an embedding that captures the differences between partitions. Across all approaches, we achieve an accuracy of approximately 83% and derive explicit formulas for a decision function in terms of b-loadings. Additionally, we develop transformer-based models for prediction, achieving the highest reported accuracy of over 99%.
Concepts
The Big Picture
Imagine you’re trying to understand how Lego sets combine. If you have two sets, you want to know what new sets you can build by merging them, and how many ways each resulting set can appear. Now replace “Lego sets” with abstract mathematical objects called representations (formal ways of describing how symmetries act on a mathematical structure) and you have a glimpse of one of the deepest unsolved problems in mathematics: computing Kronecker coefficients.
These numbers describe how fundamental symmetry patterns combine when layered together. They arise across mathematics and physics, with implications ranging from quantum information theory to computational complexity.
Since 1938, when Francis Murnaghan first posed the question, mathematicians have searched for a combinatorial formula (a counting recipe built from discrete patterns) to pin down these numbers. Despite nearly a century of effort, no such formula exists. Worse, simply determining whether a single Kronecker coefficient equals zero is NP-hard: it belongs to a class of problems so computationally difficult that no efficient algorithm can handle them in general, no matter how powerful the computer.
Now a team of IAIFI researchers has turned machine learning into a mathematical microscope, not just predicting these mysterious numbers but explaining the predictions, nudging open a door sealed for 87 years.
Key Insight: By combining interpretable ML with a clever geometric embedding of partitions, the researchers derived explicit mathematical formulas predicting when a Kronecker coefficient is zero, achieving 83% accuracy with fully human-readable decision rules, and over 99% accuracy with transformer models.
How It Works
The inputs to these models are triples of partitions (ways of writing a number n as an ordered sum of positive integers). A partition of 6, for example, might be (3,2,1), meaning 3+2+1=6. The Kronecker coefficient g(λ,µ,ν) is indexed by three such partitions. The binary question: is this coefficient zero or not?
Previous work showed that convolutional neural networks and gradient boosting could answer this with ~98% accuracy, impressive but opaque. This paper asks harder: why do these models work? What features are they actually using?
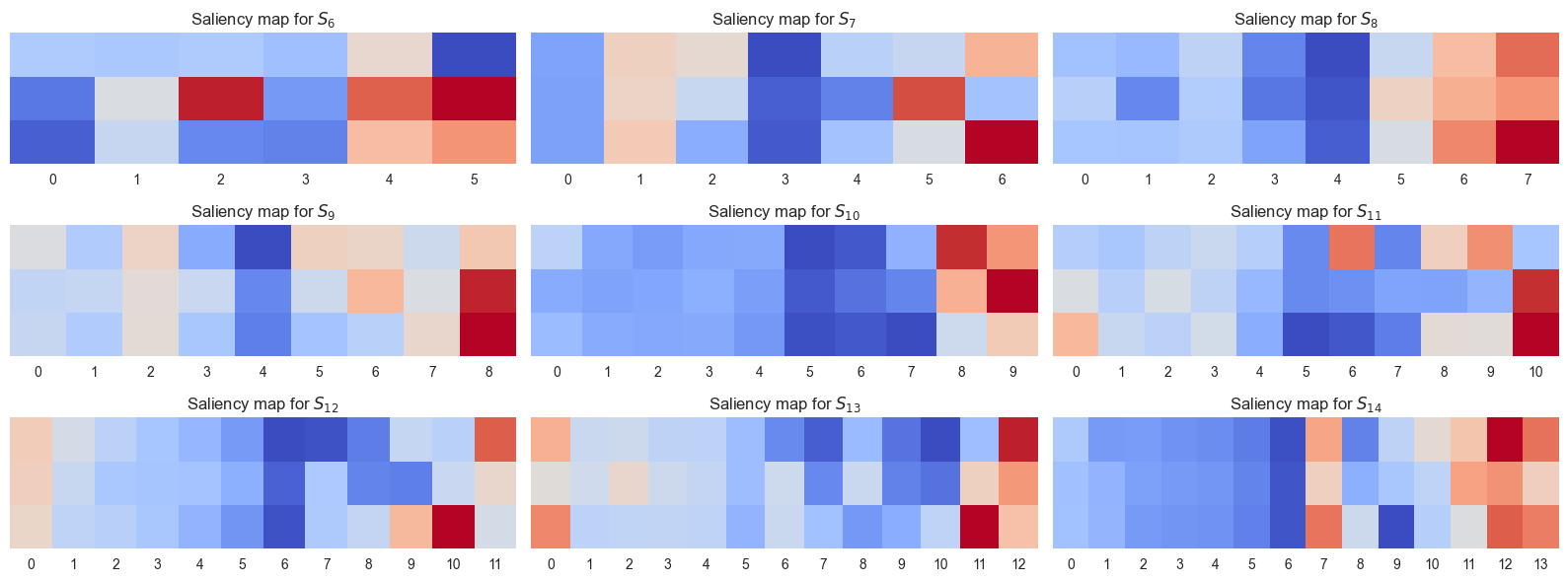
Gradient saliency analysis identifies which input features most strongly drive a network’s output. Think of it as asking the network to highlight the evidence it found most useful. When partitions are represented as n-dimensional vectors, the analysis reveals that the first few and last few entries matter far more than the middle. The “extremes” of a partition carry the signal.
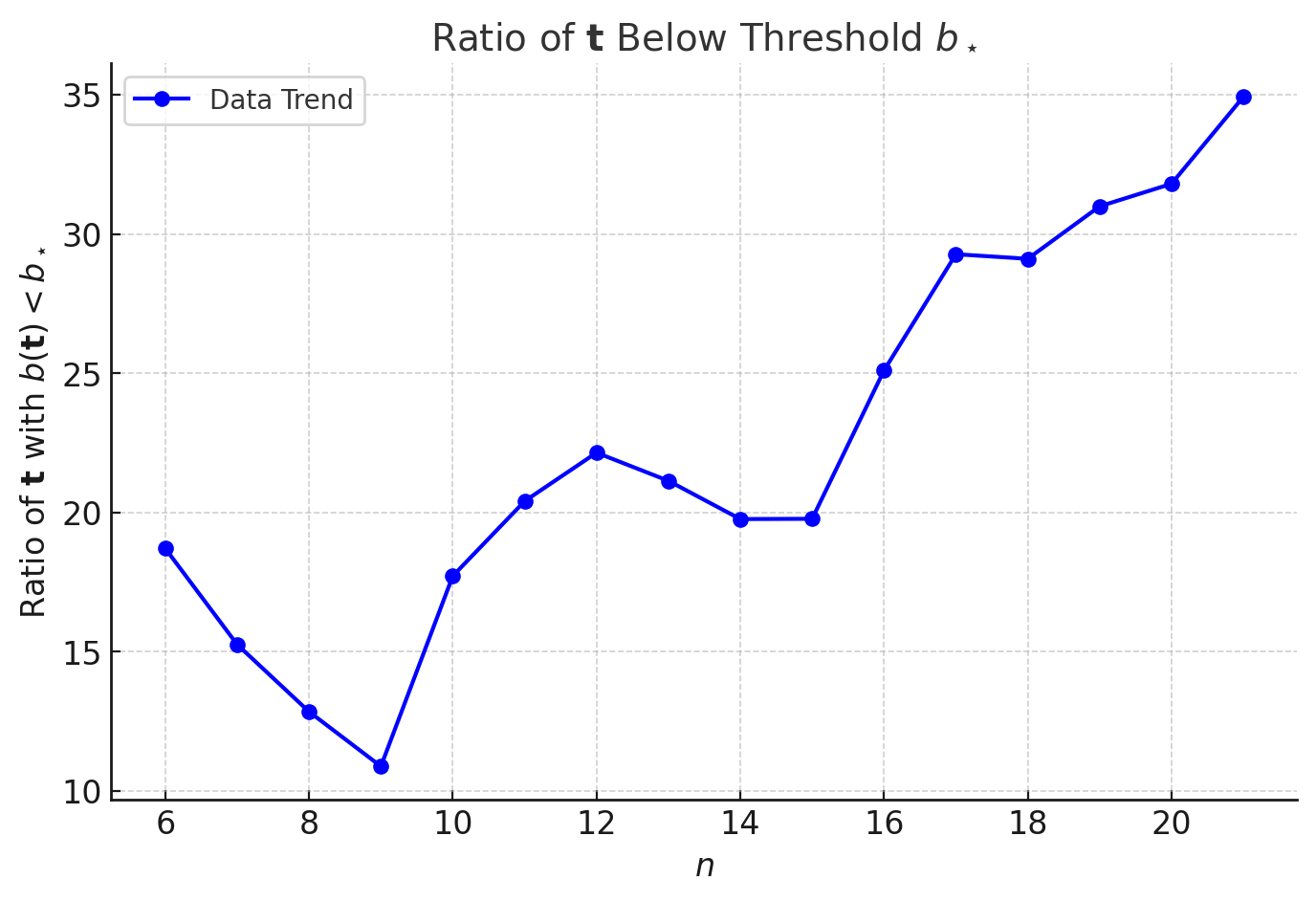
The second key ingredient is the b-loading, a single number assigned to each partition. The researchers build a matrix recording pairwise distances between every partition of n, then apply a standard linear-algebra technique to extract a ranking. Each partition lands on a one-dimensional scale, rescaled to [0, 100]. That position is its b-loading.
For a triple (λ,µ,ν), the b-loading of the triple is the sum b(λ) + b(µ) + b(ν), a single number that compresses a complex three-partition relationship into something tractable. What the researchers found:
- Histograms of summed b-loadings follow gamma distributions
- Separating distributions by whether g(λ,µ,ν) = 0 reveals a threshold
- Below a critical value b*, the coefficient is always nonzero, a provable sufficient condition
The team trained three families of interpretable models on b-loadings: Kolmogorov-Arnold Networks (KANs), which learn flexible mathematical functions expressible in explicit human-readable form; small neural networks whose parameters can be read directly; and PySR, a symbolic regression tool that searches for explicit algebraic formulas. All three converged near 83% accuracy, essentially the theoretical ceiling for what b-loadings alone can achieve (~85%).
Beyond interpretability, transformer models (the same architecture behind large language models like GPT) trained on raw partition triples achieved over 99% accuracy, the highest ever reported for this problem. Their internal reasoning remains opaque, a direction the authors flag for future work.
Why It Matters
Having explicit formulas for a decision function (even one covering 83% of cases) represents genuine structural insight into a problem that has resisted attack for nearly a century. The b-loading sufficient condition (g(t) ≠ 0 whenever b(t) < b*) is a theorem, not a heuristic. Machine learning has produced a mathematical result.
The interpretability argument is also sharp. The 99% transformer result is scientifically interesting but mathematically silent. The 83% symbolic regression result is less accurate but far more informative: it reveals what structure the data contains. As AI becomes standard in mathematical research, translating learned representations back into human-readable form will be critical for turning predictions into proofs.
The gap between 83% and 99% is a research program in miniature. What features do transformers find that b-loadings miss? Understanding how transformers represent mathematical objects in this domain could illuminate both Kronecker coefficient structure and the broader question of machine reasoning over combinatorial algebra.
Bottom Line: Interpretable ML has extracted explicit mathematical formulas for predicting Kronecker coefficients, turning a black-box classifier into a source of genuine algebraic insight. A 99%-accurate transformer model points toward even deeper structure waiting to be decoded.
IAIFI Research Highlights
This work applies interpretable ML techniques (KANs, symbolic regression, and transformer architectures) to a central open problem in combinatorial representation theory, showing that AI can generate provable mathematical insights rather than just predictions.
The paper establishes the complementary value of interpretable models alongside high-accuracy black-box approaches, deriving explicit closed-form decision functions that expose the geometric structure underlying learned classifiers.
Kronecker coefficients appear in quantum information theory and the representation theory of symmetric groups, making progress on their vanishing problem relevant to fundamental questions in mathematical physics and complexity theory.
Future work aims to decode the internal representations of the transformer models achieving >99% accuracy, potentially unlocking new conditions for Kronecker coefficient vanishing; see [arXiv:2502.11774](https://arxiv.org/abs/2502.11774) (Butbaia, Lee, Ruehle, 2025).
Original Paper Details
Interpretable Machine Learning for Kronecker Coefficients
2502.11774
["Giorgi Butbaia", "Kyu-Hwan Lee", "Fabian Ruehle"]
We analyze the saliency of neural networks and employ interpretable machine learning models to predict whether the Kronecker coefficients of the symmetric group are zero or not. Our models use triples of partitions as input features, as well as b-loadings derived from the principal component of an embedding that captures the differences between partitions. Across all approaches, we achieve an accuracy of approximately 83% and derive explicit formulas for a decision function in terms of b-loadings. Additionally, we develop transformer-based models for prediction, achieving the highest reported accuracy of over 99%.