
Investigating Representation Universality: Case Study on Genealogical Representations
Authors
David D. Baek, Yuxiao Li, Max Tegmark
Abstract
Motivated by interpretability and reliability, we investigate whether large language models (LLMs) deploy universal geometric structures to encode discrete, graph-structured knowledge. To this end, we present two complementary experimental evidence that might support universality of graph representations. First, on an in-context genealogy Q&A task, we train a cone probe to isolate a tree-like subspace in residual stream activations and use activation patching to verify its causal effect in answering related questions. We validate our findings across five different models. Second, we conduct model stitching experiments across models of diverse architectures and parameter counts (OPT, Pythia, Mistral, and LLaMA, 410 million to 8 billion parameters), quantifying representational alignment via relative degradation in the next-token prediction loss. Generally, we conclude that the lack of ground truth representations of graphs makes it challenging to study how LLMs represent them. Ultimately, improving our understanding of LLM representations could facilitate the development of more interpretable, robust, and controllable AI systems.
Concepts
The Big Picture
Imagine teaching a child about family trees. You draw a diagram: grandparents at the top, parents in the middle, children below. The spatial layout is the knowledge. Now ask: when an AI language model answers questions about who is whose ancestor, does it build something like that diagram inside its own head?
That question sounds almost philosophical. But researchers at MIT have turned it into a concrete experimental program, and the answers are surprisingly orderly. A new study from David Baek, Yuxiao Li, and Max Tegmark asks whether large language models (LLMs), the AI systems powering modern chatbots, consistently use the same geometric patterns to store family relationships, regardless of which model you examine.
The deeper motivation is safety and reliability. If different AI models independently arrive at the same internal structures for the same concepts, that consistency is something we can study, verify, and eventually trust. If every model invents its own private internal language, understanding AI becomes a hopeless task, like trying to read books when every author uses a different secret alphabet.
The paper presents the first systematic evidence that relationship-based knowledge (facts like “Alice is a descendant of Bob”) may have a universal geometric fingerprint inside AI language models.
Key Insight: LLMs appear to represent ancestral relationships using a geometric structure called a cone embedding, and this structure recurs across models with wildly different architectures and sizes, hinting at a deep form of representational universality.
How It Works
The researchers began with a deceptively simple toy problem: train a small neural network to learn the descendant-of relationship on a 15-node tree. What geometric structure does the network learn?
When you visualize the learned embeddings, the coordinates that place each node in the network’s internal mathematical space, the nodes arrange themselves into a tree-like shape. Not metaphorically. The parent always sits at a position from which all its descendants lie within a geometric cone pointing downward.
The researchers call this a cone embedding: node j is a descendant of node i if and only if j’s position falls inside a fixed cone emanating from i’s position.
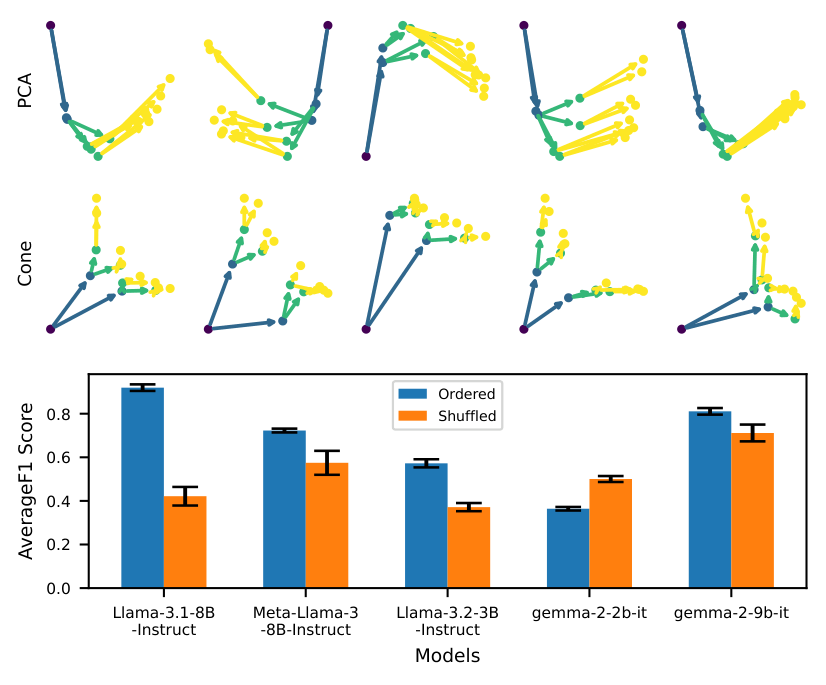
This cone structure emerged spontaneously across nine random seeds and two different tree shapes (balanced binary trees and irregular general trees). The network was never told to produce a geometric hierarchy. It discovered one anyway, because the two-dimensional constraint forced it to find the most compact encoding of all parent-child relationships at once.
Next came the real LLMs. The team’s methodology had three steps:
- Build a testbed. They created an in-context genealogy Q&A task, presenting a model with a fictional family history, then asking relationship questions.
- Detect the geometry. They trained a cone probe, a pattern-detection algorithm that scans the model’s internal activations (the numerical signals generated as the network processes text), to check whether the residual stream (the running “memory” that carries information through the model’s layers) resembles a cone embedding. The probe worked across five different models.
- Verify causality. They used activation patching, replacing internal signals from one model run with those from a different run, to confirm that the cone geometry is causally responsible for the model’s answers. When they patched in activations from a different family tree, the model’s answers changed accordingly. The geometry isn’t decorative; it’s doing real computational work.
The second experiment tackled universality through model stitching. If two models encode family relationships in geometrically similar ways, you should be able to glue the front half of one onto the back half of another and still get sensible outputs. A thin trainable linear adapter connected the early layers of one model to the late layers of another, tested across OPT, Pythia, Mistral, and LLaMA, spanning 410 million to 8 billion parameters.
Results were mixed but informative. Some pairs stitched together with little degradation in prediction performance, suggesting genuinely compatible internal representations. Models of similar architectural lineage aligned better, but cross-family alignments were possible too. The stitching experiments also provided a quantitative handle on representational similarity, one that doesn’t require knowing in advance what the “correct” internal representation should look like.
Why It Matters
This work touches on two pressing questions in AI research: what do neural networks actually compute, and can we trust them? The cone embedding result offers a small but concrete answer to the first. For one class of relational knowledge, LLMs build geometric structures that are both mathematically elegant and functionally causal.
The second question has longer-term implications. If representations are universal, tools built to inspect one model’s internals can potentially transfer to others. Correcting factual errors, removing biases, or detecting deceptive behavior could become more portable. Think less bespoke surgery on each individual model, more general anatomical knowledge applied across the board. The paper points to deception detection, bias correction, and removal of dangerous knowledge as areas where better representational understanding would pay off.
There are honest limitations. Genealogy is a clean, well-structured domain, arguably one of the easiest relationship-based problems imaginable. Real knowledge graphs (medical relationships, legal dependencies, physical causal chains) are vastly messier. The lack of ground-truth representations for arbitrary graphs makes it hard to move beyond case studies, and future work will need to test whether cone-like universality holds up in more complex, noisier relational structures.
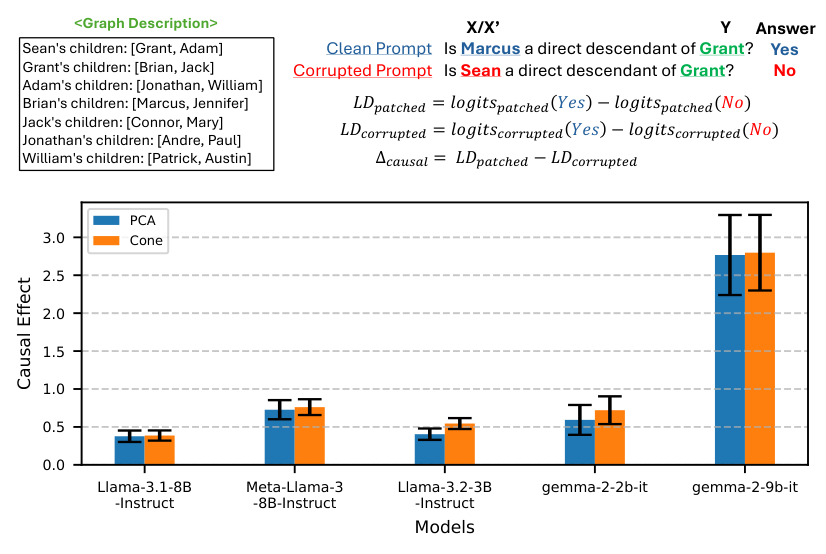
Bottom Line: LLMs appear to converge on cone-shaped geometric encodings for tree-structured relationships, and these encodings are causally active, not merely correlational. This is early but real evidence that very different AI systems may share a common representational language.
IAIFI Research Highlights
This work applies geometric and topological intuitions from mathematics to the black box of neural network internals, in line with IAIFI's mission to bring physics-style reasoning to AI systems.
The cone probe and model stitching methodology provide new interpretability tools that work across diverse architectures, advancing our ability to audit and correct what LLMs know and how they encode it.
By framing knowledge representation as a geometric structure problem, analogous to how physicists seek invariant descriptions of physical systems, the work points toward a more principled science of AI representations.
Future work will extend these methods to more complex knowledge graphs and noisier relational domains; see the paper by Baek, Li, and Tegmark ([arXiv:2410.08255](https://arxiv.org/abs/2410.08255)).