
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Authors
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Pai, Andrey Gromov, Daniel A. Roberts, Diyi Yang, David L. Donoho, Sanmi Koyejo
Abstract
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops proposed that such loops would lead to a phenomenon termed model collapse, under which performance progressively degrades with each model-data feedback iteration until fitted models become useless. However, those studies largely assumed that new data replace old data over time, where an arguably more realistic assumption is that data accumulate over time. In this paper, we ask: what effect does accumulating data have on model collapse? We empirically study this question by pretraining sequences of language models on text corpora. We confirm that replacing the original real data by each generation's synthetic data does indeed tend towards model collapse, then demonstrate that accumulating the successive generations of synthetic data alongside the original real data avoids model collapse; these results hold across a range of model sizes, architectures, and hyperparameters. We obtain similar results for deep generative models on other types of real data: diffusion models for molecule conformation generation and variational autoencoders for image generation. To understand why accumulating data can avoid model collapse, we use an analytically tractable framework introduced by prior work in which a sequence of linear models are fit to the previous models' outputs. Previous work used this framework to show that if data are replaced, the test error increases with the number of model-fitting iterations; we extend this argument to prove that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations, meaning model collapse no longer occurs.
Concepts
The Big Picture
Imagine a photocopier making copies of copies. The first generation looks crisp. By the tenth, the text is blurry and artifacts have crept in. By the hundredth, you can barely read it. Now imagine that happening to AI systems generating most of the text, images, and data on the internet, and then training the next generation of AI on that degraded output. This is model collapse, and for the past couple of years it has loomed as one of the most serious threats to the future of AI development.
The concern is real. As AI systems like GPT-4 and image generators like Stable Diffusion flood the web with synthetic content, that material inevitably gets scraped back into training sets for future models. Previous research suggested this creates a death spiral: each successive generation trained on noisier outputs, until the whole thing collapses into gibberish.
A new paper from researchers at Stanford, MIT, University of Maryland, and Constellation argues that this doom scenario rests on a critical, and arguably unrealistic, assumption. Fix that assumption, and model collapse goes away.
Key Insight: When AI models accumulate synthetic data alongside real data rather than replacing real data with synthetic data, model collapse does not occur, and this can be proven mathematically.
How It Works
The key flaw in previous work was assuming that each new model generation replaces its training data with freshly generated synthetic data. It’s a clean experimental setup, but it doesn’t match how AI development actually works. Meta trained Llama 1 on 1.4 trillion tokens, Llama 2 on 2 trillion, Llama 3 on 15 trillion. The dataset grows with each iteration. It doesn’t shrink.
The researchers set up a direct comparison between two regimes. In the replace setting, each new model trains only on data from the previous model, and the original real data is discarded. In the accumulate setting, each new model trains on everything: the original real corpus plus every generation of synthetic data produced so far. A small difference, but the consequences are stark.
To test this, the team ran experiments across three domains:
- Causal language modeling (predicting text word by word, as in a standard chatbot): They pretrained sequences of GPT-2 and Llama 2 models on TinyStories, a 470M-token dataset of short children’s stories, generating new synthetic datasets at each iteration and either replacing or appending.
- Molecular conformation: They used diffusion models, neural networks that learn to generate data by first adding noise to examples and then reversing that process, to generate 3D molecular structures, testing whether the same dynamics held for scientific data far removed from text.
- Image generation: They ran variational autoencoders (VAEs), neural networks trained to compress images into a compact representation and reconstruct them, on image datasets to stress-test the hypothesis in a third domain.
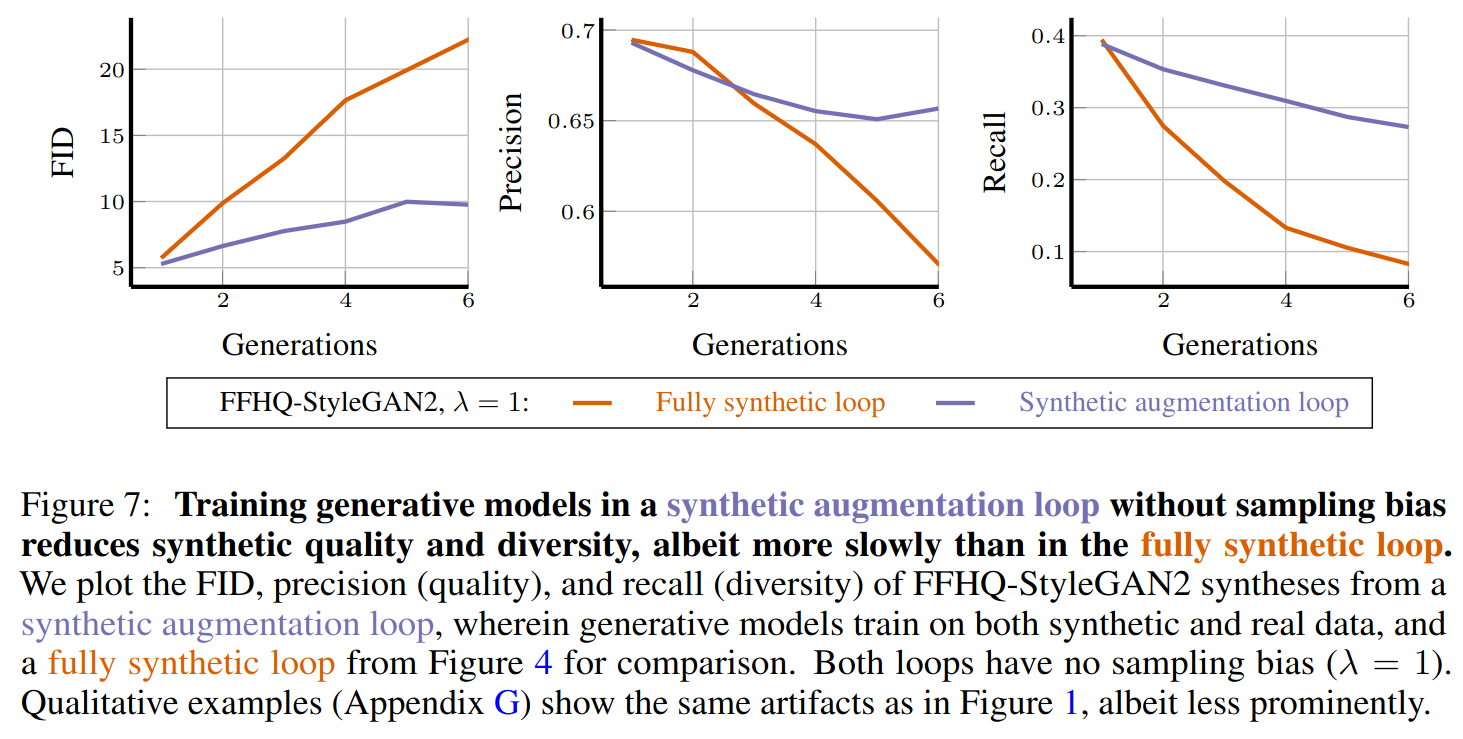
The pattern was the same across all three domains. Replace the data, and test error, how poorly a model performs on new, unseen examples, climbs steadily with each iteration. Classic model collapse. Accumulate the data, and error stabilizes. The models don’t get worse.
The researchers didn’t just show this empirically. They proved it. Using a simplified mathematical framework built around sequences of linear models, they extended prior work showing that replacement causes test error to grow linearly with iterations. Their new result: when data accumulate, test error has a finite upper bound that doesn’t depend on the number of iterations at all. No matter how many generations of synthetic data pile up, the model cannot collapse past that fixed ceiling.
The intuition is simple: the original real data never goes away. It anchors each successive model, preventing the compounding distortions that cause collapse. Synthetic data adds volume but can’t drown out the signal when the signal is always present.
Why It Matters
This reframes one of the most discussed risks in AI development. The model collapse literature has prompted genuine concern about the long-term sustainability of training on web-scraped data as synthetic content proliferates. If collapse requires a data-replacement assumption that doesn’t match real-world practice, the catastrophic failure mode may be far less likely than feared.
The paper doesn’t declare total victory, though. The accumulation result holds under one condition: that some real data is always present in the training mix. It doesn’t address scenarios where real human-generated content becomes genuinely scarce, or where synthetic data is systematically biased in ways real data can’t correct.
The researchers also studied a “maximally pessimistic” scenario: uncontrolled synthetic data flooding the internet and being indiscriminately scraped. Even there, collapse doesn’t occur. But questions about data quality, filtering, and the ratio of real to synthetic data remain open.
The results extend beyond text. The molecular conformation experiments show that scientific AI systems, models trained on chemistry, biology, or physics simulations, face the same feedback dynamics. Understanding when collapse can and cannot occur matters for the integrity of AI-assisted scientific discovery.
Bottom Line: Model collapse is not inevitable. Keeping real data in the training mix as synthetic data accumulates is sufficient to prevent it, proven across language, molecular, and image domains, and backed by rigorous mathematical theory.
IAIFI Research Highlights
This work connects foundational machine learning theory, the stability of iterative training loops, to practical data dynamics across physics-adjacent domains like molecular conformation generation, combining rigorous mathematical proofs with large-scale empirical experiments.
The paper provides the first theoretical proof that data accumulation prevents model collapse, overturning a widely held assumption and establishing a concrete, actionable principle for sustainable AI training at scale.
The diffusion model experiments on 3D molecular conformation generation show these systems are immune to collapse under data accumulation, supporting the reliability of AI tools used in computational chemistry and physics.
Future work should explore how data quality, filtering strategies, and real-to-synthetic ratios affect the tightness of the error bound; the paper is available at [arXiv:2404.01413](https://arxiv.org/abs/2404.01413).
Original Paper Details
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
2404.01413
["Matthias Gerstgrasser", "Rylan Schaeffer", "Apratim Dey", "Rafael Rafailov", "Henry Sleight", "John Hughes", "Tomasz Korbak", "Rajashree Agrawal", "Dhruv Pai", "Andrey Gromov", "Daniel A. Roberts", "Diyi Yang", "David L. Donoho", "Sanmi Koyejo"]
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops proposed that such loops would lead to a phenomenon termed model collapse, under which performance progressively degrades with each model-data feedback iteration until fitted models become useless. However, those studies largely assumed that new data replace old data over time, where an arguably more realistic assumption is that data accumulate over time. In this paper, we ask: what effect does accumulating data have on model collapse? We empirically study this question by pretraining sequences of language models on text corpora. We confirm that replacing the original real data by each generation's synthetic data does indeed tend towards model collapse, then demonstrate that accumulating the successive generations of synthetic data alongside the original real data avoids model collapse; these results hold across a range of model sizes, architectures, and hyperparameters. We obtain similar results for deep generative models on other types of real data: diffusion models for molecule conformation generation and variational autoencoders for image generation. To understand why accumulating data can avoid model collapse, we use an analytically tractable framework introduced by prior work in which a sequence of linear models are fit to the previous models' outputs. Previous work used this framework to show that if data are replaced, the test error increases with the number of model-fitting iterations; we extend this argument to prove that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations, meaning model collapse no longer occurs.