
KAN: Kolmogorov-Arnold Networks
Authors
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, Max Tegmark
Abstract
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Concepts
The Big Picture
Imagine teaching someone to draw by giving them a single universal pencil stroke and telling them to combine it in different ways. That’s essentially how most neural networks learn. Every neuron applies the same fixed mathematical rule, a simple formula baked in from the start, and the network’s intelligence lives entirely in how those neurons connect. It works. It’s driven virtually every AI breakthrough of the past decade.
But a team of researchers from MIT, Caltech, Northeastern, and IAIFI asked a different question: what if the connections themselves could learn?
That question led them to Kolmogorov-Arnold Networks, or KANs, a fundamentally different blueprint for neural networks. In a standard network, each neuron applies a fixed rule (called an activation function, the neuron’s personal formula for transforming its input). KANs flip this: neurons become simple summation points, and the connections carry the learnable rules instead. It sounds like a subtle change. The consequences are not.
The researchers show that this architectural shift enables smaller networks to match or beat much larger conventional ones, unlocks a new ability to read and interpret a network’s internal logic, and helps scientists rediscover known mathematical and physical laws from data alone.
Key Insight: KANs replace every fixed connection formula in a neural network with a learnable function, producing networks that are more accurate, more efficient, and interpretable all at once.
How It Works
The mathematical foundation comes from a 1957 theorem by Andrey Kolmogorov and Vladimir Arnold. The Kolmogorov-Arnold representation theorem states that any function of multiple variables can be written as a finite composition of single-variable functions. No matter how complex a relationship is, you can always decompose it into nested, one-dimensional pieces.
Classical neural networks draw from a different result, the universal approximation theorem, which says you can approximate any function by stacking enough neurons with fixed nonlinearities. Both guarantee expressive power, but they suggest radically different architectures.
Here’s the practical difference:
- In a standard MLP (Multi-Layer Perceptron): neurons apply a fixed activation function (say, ReLU), and the network learns by adjusting linear weights on the connections between them.
- In a KAN: every connection carries a learnable univariate function, parametrized as a spline (a smooth, flexible curve built from adjustable mathematical segments that bend and adapt to fit the data). Nodes simply sum their incoming signals. All the learning happens on the edges.
So a KAN has no fixed linear weight matrices. Each “weight” is a flexible curve the network sculpts during training.
Why splines? They excel at approximating smooth functions in low dimensions. They adjust locally, switch resolutions gracefully, and converge fast. Their weakness is the curse of dimensionality: fitting a high-dimensional function directly with splines requires exponentially more parameters as dimensions grow. MLPs sidestep this by learning compositional structure. KANs inherit both advantages. Splines handle individual univariate pieces with high precision, while the MLP-like outer structure discovers how those pieces compose.
The authors demonstrate this on a benchmark function, a high-dimensional sum of sines wrapped in an exponential. A small KAN learns it accurately. A much larger MLP struggles because ReLU activations are poorly suited to smooth trigonometric and exponential shapes.
Why It Matters
The accuracy gains alone would justify interest in KANs, but the interpretability story matters more. After training, a KAN’s learned edge functions can be visualized directly. Each connection is a curve you can inspect, prune, or symbolically identify. The authors pair this with simplification techniques: pruning unimportant connections, matching learned functions to known mathematical operations, and collapsing redundant structure.
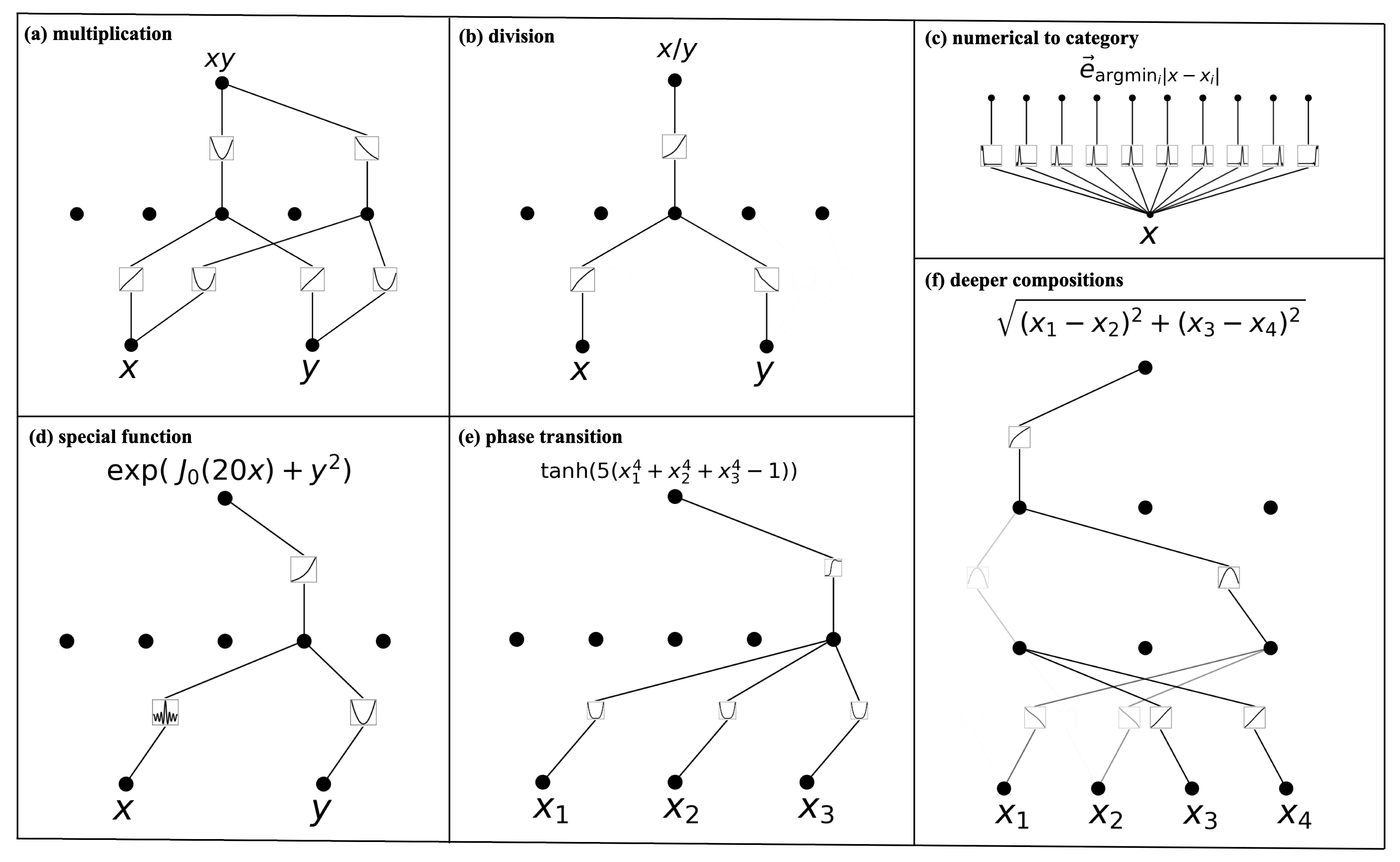
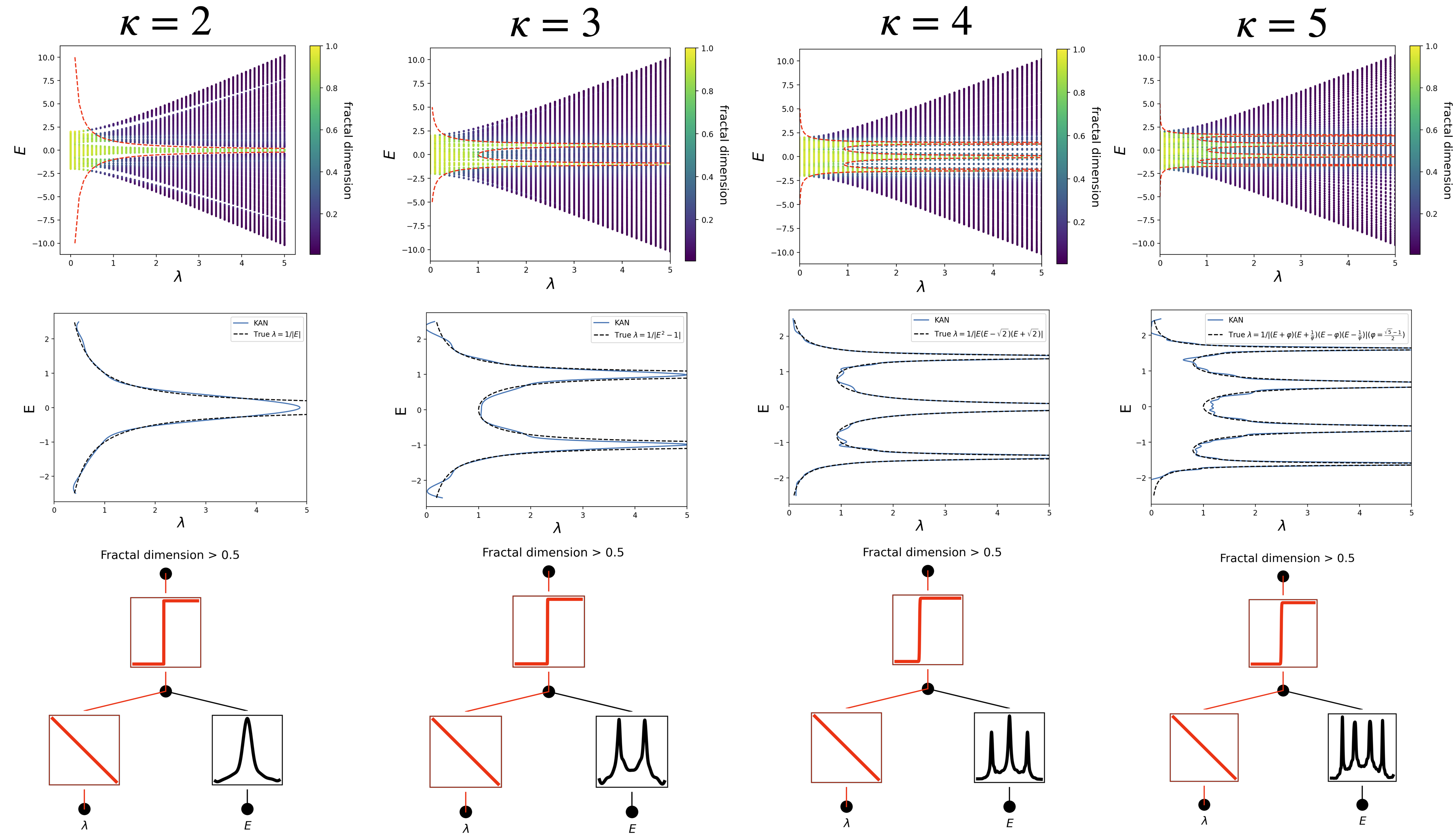
This turns KANs into scientific collaborators. In two case studies, the researchers fed experimental data to a KAN and asked it to find structure. In knot theory, a KAN recovered a known mathematical relationship between topological invariants, a result that took human mathematicians years to establish. In condensed matter physics, a KAN identified the functional form governing Anderson localization (the quantum phenomenon where electrons become trapped in disordered materials), reproducing the known scaling law from scratch. These aren’t curve-fits. They’re structured mathematical hypotheses the network generates and humans can verify.
The scaling behavior is also notable. KANs empirically exhibit faster neural scaling laws than comparable MLPs, meaning a fixed computational budget yields more accuracy. On PDE-solving tasks, small KANs match the accuracy of networks orders of magnitude larger.
There are real caveats. Current results focus on small-scale scientific tasks: function fitting, PDE solving, symbolic discovery. Whether KANs scale to the massive transformer architectures powering large language models remains open. Training can also be slower per step than MLPs due to spline evaluation overhead. The authors argue these are engineering challenges, not fundamental limits.
For AI research, KANs open a new design axis. Modern deep learning has converged on MLPs as the default nonlinear workhorse. They appear in every transformer, every graph network, every diffusion model. A principled alternative with different built-in assumptions about pattern structure and genuine interpretability could reshape how the next generation of models gets built.
For physics and mathematics, the promise goes further. Science produces more data than humans can digest, from particle colliders, gravitational wave detectors, cosmological surveys, and quantum simulators. Tools that extract symbolic, human-readable structure rather than black-box predictions could accelerate discovery in ways pure accuracy cannot. KANs represent a serious step toward neural networks that don’t just predict but explain.
Bottom Line: KANs replace fixed activations with learnable spline functions on every edge, achieving better accuracy with smaller models while producing networks whose internal structure can be read, pruned, and interpreted as mathematical laws.
IAIFI Research Highlights
KANs translate a classical theorem from pure mathematics into a working neural network architecture, then deploy it to rediscover known laws in knot theory and condensed matter physics from data alone.
KANs exhibit faster neural scaling laws than MLPs and match or exceed MLP accuracy with far fewer parameters, while producing networks whose learned functions can be directly visualized and symbolically identified.
By recovering known physical scaling laws, such as those governing Anderson localization, from experimental data without prior knowledge, KANs offer a new approach for symbolic scientific discovery in physics and mathematics.
Future work will explore whether KANs scale to large transformer architectures and whether their interpretability advantages hold in higher-dimensional regimes. The paper ([arXiv:2404.19756](https://arxiv.org/abs/2404.19756)) has open-source code available via `pip install pykan`.