
L$^2$M: Mutual Information Scaling Law for Long-Context Language Modeling
Authors
Zhuo Chen, Oriol Mayné i Comas, Zhuotao Jin, Di Luo, Marin Soljačić
Abstract
We present a universal theoretical framework for understanding long-context language modeling based on a bipartite mutual information scaling law that we rigorously verify in natural language. We demonstrate that bipartite mutual information captures multi-token interactions distinct from and scaling independently of conventional two-point mutual information, and show that this provides a more complete characterization of the dependencies needed for accurately modeling long sequences. Leveraging this scaling law, we formulate the Long-context Language Modeling (L$^2$M) condition, which lower bounds the necessary scaling of a model's history state -- the latent variables responsible for storing past information -- for effective long-context modeling. We validate the framework and its predictions on transformer and state-space models. Our work provides a principled foundation to understand long-context modeling and to design more efficient architectures with stronger long-context capabilities, with potential applications beyond natural language.
Concepts
The Big Picture
Imagine trying to follow a complex novel when you can only remember the last few sentences. You might track individual words, but you’d lose the plot threads, the character motivations, the slow-building tension. Something similar happens inside AI language models processing long documents, and until now, we’ve lacked the mathematical language to describe exactly what gets lost, and how much memory a model needs to avoid losing it.
Most modern AI is built around two competing architectures. Transformers handle long contexts by storing a detailed record of every past word’s context, a key-value (KV) cache whose memory cost scales quadratically: double the text, quadruple the memory. State-space models (SSMs) take the opposite approach, compressing everything into a fixed-size running summary of past context. SSMs are cheap to run, but that summary might be too compact to hold what the model actually needs. Both families have been designed without any principled theory of how much memory long-context modeling requires.
A team from MIT, Harvard, UCLA, and the Polytechnic University of Catalonia has now built that theory. Their framework, L²M, derives a concrete mathematical lower bound on how a model’s memory must grow with document length to capture the statistical structure of real language.
Key Insight: Natural language follows a consistent power-law pattern in how distant words depend on each other, and the L²M condition translates this directly into a minimum memory growth rate, giving architects a principled target rather than a rule of thumb.
How It Works
The key move is replacing conventional mutual information with bipartite mutual information. Standard mutual information measures how much knowing one word tells you about another, a two-point relationship. But language is richer than that. The meaning of a word depends on entire preceding passages, not just its nearest neighbor.
Bipartite mutual information, written I(X; Y), measures statistical dependence between two blocks of words, say the first half and second half of a document, capturing the full long-range structure that two-point measures miss entirely.
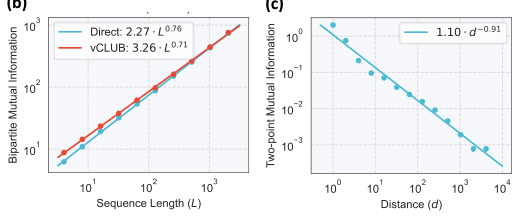
The team’s first empirical finding: bipartite mutual information in natural language scales as a power law of the form I(X; Y) ∝ L^α, with exponent α < 1. This “sub-volume” scaling means dependency grows steadily but more slowly than the document itself. They verified this across diverse text corpora using large language models to estimate text probability distributions, and confirmed that bipartite scaling is statistically independent of ordinary two-point mutual information. It captures genuinely new structure.
From this empirical law, they derive the L²M condition in two steps:
- Expressivity bound: The maximum bipartite mutual information any autoregressive model can express is bounded above by the dimensionality of its history state, the internal variables storing past information. In a transformer, this is the KV cache; in a recurrent or state-space model, it’s the recurrent hidden state.
- Necessary condition: For a model to reproduce the power-law growth of bipartite mutual information in natural language, its history state dimension must grow at least as fast as the data’s power law. A fixed-size state is provably insufficient beyond a certain context length; a quadratically-growing KV cache is sufficient but potentially wasteful.
The team validated these predictions on both transformer and SSM architectures, on synthetic datasets with known ground truth and on natural language benchmarks of varying lengths. The theory’s predictions matched observed behavior across architectures.
Why It Matters
Prior scaling laws described how model performance changes with parameters and compute at fixed context lengths. They didn’t say what the architecture itself must do as context grows longer. L²M answers that question.
Fixed-state models are provably inadequate for truly long contexts. Transformers’ quadratically-growing KV cache is sufficient but not minimal. There’s room for architectures that grow their state sub-quadratically while still satisfying the L²M condition, a concrete design target the field has lacked until now.
The framework reaches beyond language too. Any sequence domain where bipartite mutual information follows a power law, including genomic sequences, physical simulations, and audio, could yield to the same analysis. The physics community has long used mutual information and entanglement entropy to characterize complexity in quantum systems. L²M runs that logic in reverse, pulling those tools into AI architecture theory. The sub-volume power-law scaling the authors measure in natural language is the same mathematical structure as entanglement entropy scaling in quantum many-body systems, a parallel with concrete theoretical implications for both fields.
Bottom Line: L²M is the first rigorous, empirically-validated theory specifying how much memory a language model must have to handle long contexts, a compass for designing the next generation of efficient, long-range AI architectures.
IAIFI Research Highlights
This work applies information-theoretic tools from quantum physics, including mutual information, entanglement scaling, and sub-volume laws, to derive provable constraints on AI architecture. That's a direct expression of IAIFI's mission to move ideas between physics and AI.
The L²M condition provides the first principled lower bound on history state scaling for long-context language models, giving architects a concrete theoretical target for designing efficient alternatives to quadratic-cost transformers.
The sub-volume power-law scaling of bipartite mutual information in natural language mirrors entanglement entropy scaling in quantum many-body systems, revealing deep structural parallels between language statistics and physical complexity measures.
Future directions include applying L²M to genomic and physical simulation data and designing architectures that achieve the power-law scaling minimum rather than the quadratic maximum. The paper appeared at NeurIPS 2025 and is available at [arXiv:2503.04725](https://arxiv.org/abs/2503.04725).