
Language Models Use Trigonometry to Do Addition
Authors
Subhash Kantamneni, Max Tegmark
Abstract
Mathematical reasoning is an increasingly important indicator of large language model (LLM) capabilities, yet we lack understanding of how LLMs process even simple mathematical tasks. To address this, we reverse engineer how three mid-sized LLMs compute addition. We first discover that numbers are represented in these LLMs as a generalized helix, which is strongly causally implicated for the tasks of addition and subtraction, and is also causally relevant for integer division, multiplication, and modular arithmetic. We then propose that LLMs compute addition by manipulating this generalized helix using the "Clock" algorithm: to solve $a+b$, the helices for $a$ and $b$ are manipulated to produce the $a+b$ answer helix which is then read out to model logits. We model influential MLP outputs, attention head outputs, and even individual neuron preactivations with these helices and verify our understanding with causal interventions. By demonstrating that LLMs represent numbers on a helix and manipulate this helix to perform addition, we present the first representation-level explanation of an LLM's mathematical capability.
Concepts
The Big Picture
Ask someone to add 47 and 38, and they’ll mention carrying digits, place values, maybe counting on fingers. Ask a large language model — the AI behind systems like ChatGPT — and, until recently, nobody really knew what was happening inside. The model just… answered. That gap between “it works” and “we know why” is one of the deepest puzzles in modern AI.
Researchers at MIT have cracked open that black box for one of the most fundamental operations in mathematics: addition. What they found is genuinely strange. Language models don’t add numbers the way we do, or the way a calculator does. They encode numbers as spiraling helices — corkscrews stretched through a space with thousands of dimensions — and then rotate those helices to find the answer, like turning a combination lock.
This isn’t a metaphor. It’s geometry. And it’s the first time anyone has produced a complete explanation of how — not just that — a large language model performs a mathematical task.
Key Insight: Large language models secretly represent numbers as helices — multi-frequency spirals in activation space — and compute addition by geometrically combining these helices using a “Clock” algorithm, a process fully verified by causal intervention experiments.
How It Works
Subhash Kantamneni and Max Tegmark analyzed three mid-sized LLMs: GPT-J (6 billion parameters), Pythia-6.9B, and Llama3.1-8B. They gave each model 10,000 addition problems — every integer from 0 to 99 paired with every other — then dug into the models’ internal activations to reverse-engineer what was happening.
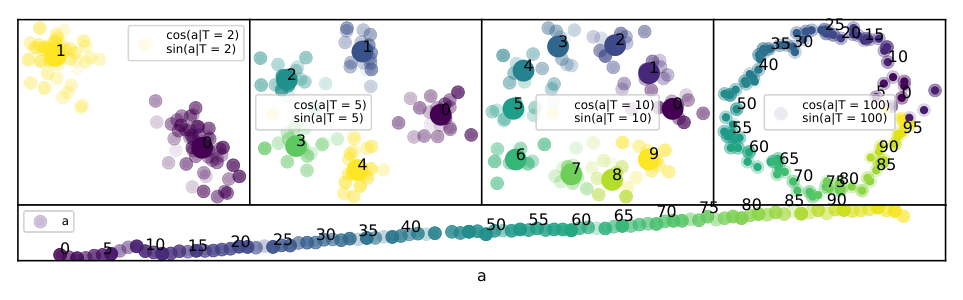
The first discovery concerned number representations: how a model stores “47” in its internal state. Each number is encoded as a pattern of activity across thousands of internal values, called activations, inside the neural network. You might expect neighboring numbers to cluster together: 1 near 2, 2 near 3. They don’t.
The activations are periodic. They repeat in cycles. Decompose a number’s representation like a musical chord into its component frequencies, and only a handful dominate. These correspond to natural repeating patterns in arithmetic: period T=10 for the units digit, T=2 for even versus odd, and so on. A linear trend layers on top.
Combine linear growth with multiple periodic oscillations, and you get a helix — a corkscrew path through high-dimensional space. The team formally characterized these as generalized helices: curves with both a linear component and sinusoidal components at multiple frequencies.
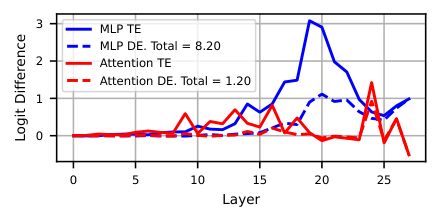
This structure isn’t a statistical curiosity. Causal interventions — experiments where the researchers surgically altered activations to point toward a different number’s helix — confirmed that redirecting the helix directly changes the model’s output. Numbers are helices. Now, how does the model add them?
The answer is the Clock algorithm, previously proposed for tiny one-layer transformers doing modular arithmetic, and now demonstrated inside billion-parameter models. The mechanism is elegant:
- The model encodes the helix for a on the token for the first number.
- It encodes the helix for b on the token for the second number.
- Through attention heads (circuits that relate different parts of the input) and MLP layers (feed-forward networks that transform those patterns), the helices are combined — rotated and composed — to produce the helix for a+b on the final token.
- That answer helix is read out to select the correct output.
Think of adding angles on a clock face: advance 4 hours from 3 o’clock and you reach 7. The model does something structurally similar, but in higher-dimensional space and simultaneously across multiple frequencies.
Individual attention heads, MLP layers, and specific neurons each play a defined role — either constructing the a+b helix or extracting the answer from it. The researchers matched the activity of individual neurons against these helix patterns and verified each step causally. The results held across all three architectures. Llama3.1-8B achieved 98.0% accuracy on test problems. The mechanism also extends beyond addition: the helix is causally implicated in subtraction, and relevant to integer division, multiplication, and modular arithmetic.
Why It Matters
This work sits at the frontier of mechanistic interpretability, the research agenda trying to reverse-engineer neural networks the way a biologist dissects an organism. Most interpretability research splits into two camps: circuits (which components are involved?) and features (how are concepts represented?). This paper bridges both, identifying the representation and showing precisely how downstream components manipulate it to complete a task.
That matters for AI safety and reliability. With a mechanistic explanation in hand, failures become investigable rather than mysterious. GPT-J’s 80.5% accuracy on two-digit addition isn’t just a benchmark number — it’s a starting point for asking why the mechanism breaks and whether it generalizes beyond the training range.
More broadly, this approach points toward verifying AI mathematical reasoning at a deep level, not merely testing outputs.
The helix finding also raises an open question: is this structure universal? The team found it independently in three different architectures. If helices are a general-purpose numerical encoding strategy that emerges from training on human text, that suggests deep constraints on how large models organize mathematical knowledge. Those constraints are worth understanding before deploying these systems in high-stakes settings.
Bottom Line: Language models encode numbers as geometric helices and add them by rotating those helices — a clean, interpretable algorithm hiding inside billions of parameters. This is the clearest window yet into how AI systems actually do math.
IAIFI Research Highlights
This work applies tools from signal processing (Fourier analysis) and differential geometry (helix parameterization) to reverse-engineer mathematical reasoning in neural networks — the kind of physics-inspired approach to AI that defines IAIFI's research agenda.
The paper delivers the first representation-level explanation of how a large language model performs arithmetic, giving mechanistic interpretability researchers a concrete foothold for understanding mathematical reasoning in billion-parameter models.
LLMs spontaneously develop structured geometric encodings of number-theoretic concepts — including periodic bases and modular symmetries — pointing toward deep connections between information processing and the emergence of mathematical structure.
Future work could extend this framework to multi-digit numbers, more complex operations, and other structured domains like logic or spatial reasoning. The paper is by Kantamneni and Tegmark at MIT: [arXiv:2502.00873](https://arxiv.org/abs/2502.00873)