
Large Language Model Driven Analysis of General Coordinates Network (GCN) Circulars
Authors
Vidushi Sharma, Ronit Agarwala, Judith L. Racusin, Leo P. Singer, Tyler Barna, Eric Burns, Michael W. Coughlin, Dakota Dutko, Courey Elliott, Rahul Gupta, Ashish Mahabal, Nikhil Mukund
Abstract
The General Coordinates Network (GCN) is NASA's time-domain and multi-messenger alert system. GCN distributes two data products - automated ``Notices,'' and human-generated ``Circulars,'' that report the observations of high-energy and multi-messenger astronomical transients. The flexible and non-structured format of GCN Circulars, comprising of more than 40500 Circulars accumulated over three decades, makes it challenging to manually extract observational information, such as redshift or observed wavebands. In this work, we employ large language models (LLMs) to facilitate the automated parsing of transient reports. We develop a neural topic modeling pipeline with open-source tools for the automatic clustering and summarization of astrophysical topics in the Circulars database. Using neural topic modeling and contrastive fine-tuning, we classify Circulars based on their observation wavebands and messengers. Additionally, we separate gravitational wave (GW) event clusters and their electromagnetic (EM) counterparts from the Circulars database. Finally, using the open-source Mistral model, we implement a system to automatically extract gamma-ray burst (GRB) redshift information from the Circulars archive, without the need for any training. Evaluation against the manually curated Neil Gehrels Swift Observatory GRB table shows that our simple system, with the help of prompt-tuning, output parsing, and retrieval augmented generation (RAG), can achieve an accuracy of 97.2 % for redshift-containing Circulars. Our neural search enhanced RAG pipeline accurately retrieved 96.8 % of redshift circulars from the manually curated database. Our study demonstrates the potential of LLMs, to automate and enhance astronomical text mining, and provides a foundation work for future advances in transient alert analysis.
Concepts
The Big Picture
Imagine a fire department that responds to every emergency in a city, but instead of radio dispatches, each incident report arrives as a handwritten note, in slightly different formats, from thousands of different writers, accumulated over thirty years. That’s roughly the situation astronomers face with the General Coordinates Network (GCN), NASA’s global alert system for astronomical explosions, colliding neutron stars, and other cosmic catastrophes.
Every time something spectacular happens in the universe (a gamma-ray burst, an extraordinarily powerful explosion briefly brighter than an entire galaxy; a gravitational wave event; a neutrino flash from a distant galaxy) observatories around the world fire off rapid reports called GCN Circulars: human-written, free-form dispatches describing what was seen, in what wavelengths, from where. Over three decades, more than 40,500 of these Circulars have piled up into a rich but unwieldy scientific archive.
The problem? They’re nearly impossible to search systematically. No standard format, no mandatory fields, no consistent vocabulary. Scientists who want to find every gamma-ray burst with a measured redshift (a number encoding how far away an explosion occurred, derived from the stretching of light by cosmic expansion) have to dig through the pile by hand.
A team led by researchers at NASA Goddard and IAIFI has now shown that large language models (AI systems trained on vast text corpora to understand and reason about language) can crack this problem, automating classification, topic organization, and precise data extraction with near-human accuracy.
Key Insight: By combining neural topic modeling, contrastive fine-tuning, and retrieval-augmented generation, this system extracts gamma-ray burst redshifts from unstructured astronomical reports with 97.2% accuracy, with no task-specific training required.
How It Works
The team built a multi-stage pipeline, each stage tackling a different layer of the Circulars’ complexity.
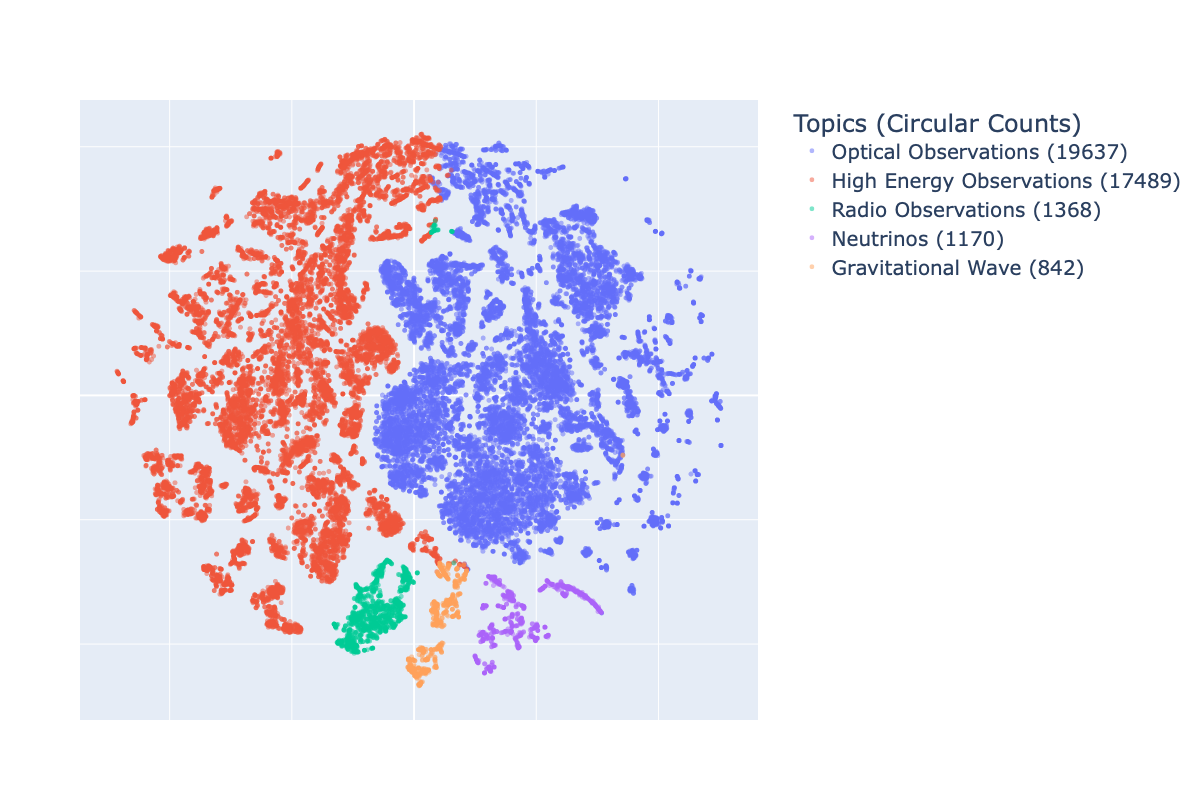
Stage 1: Neural topic modeling. First, they needed to understand what the archive is actually about. They used BERTopic, an embedding-based clustering tool that groups documents by meaning rather than keywords, to automatically discover the major themes across all 40,500 Circulars. This revealed clean clusters corresponding to gamma-ray bursts, gravitational wave events, X-ray transients, fast radio bursts, and their electromagnetic follow-up campaigns.
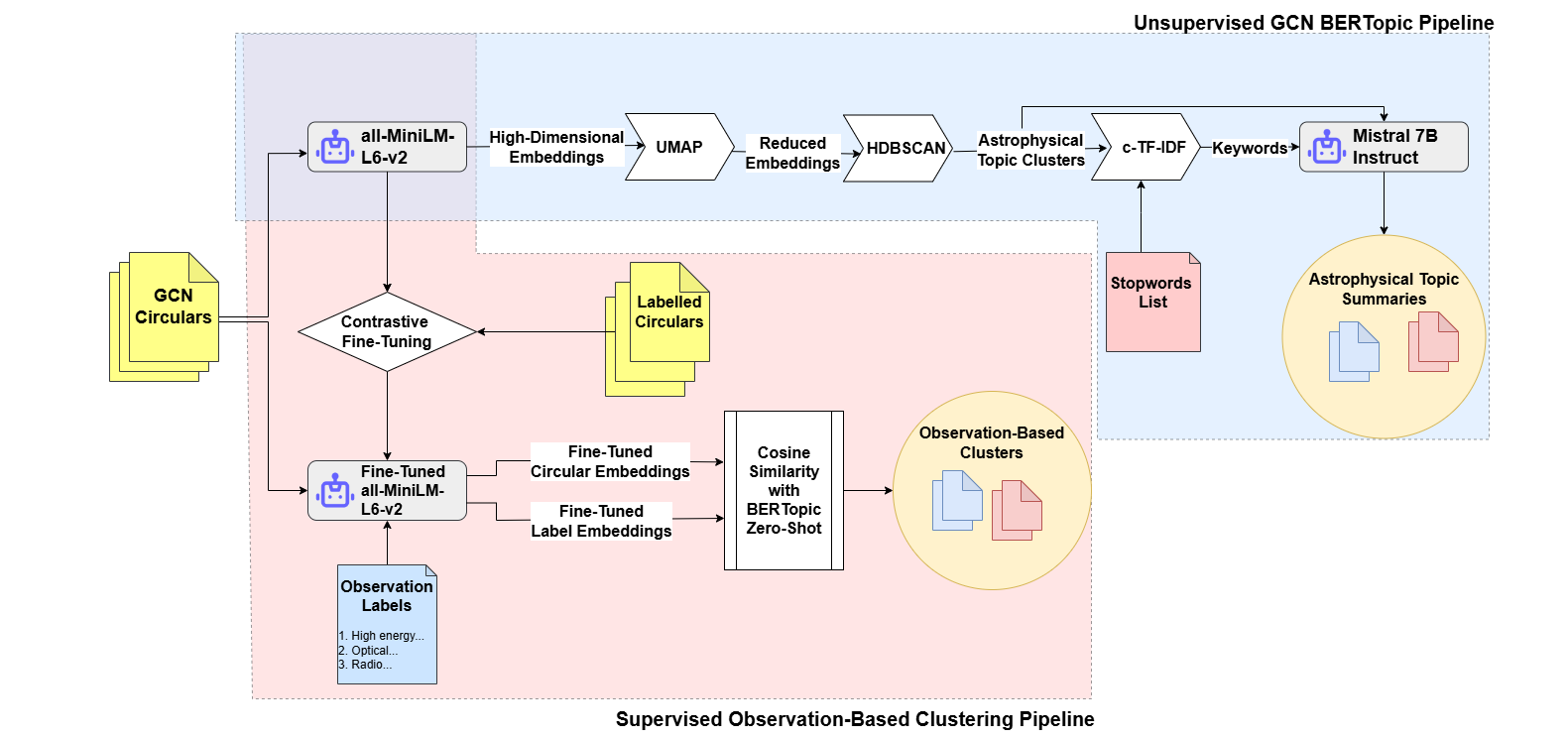
Stage 2: Waveband classification. Knowing a Circular’s topic isn’t enough; you also need to know how the event was observed. X-ray? Optical? Radio? The team used contrastive fine-tuning (a technique that trains a model by pushing similar examples closer together in embedding space and dissimilar ones apart) to classify Circulars by observation waveband and messenger type, including gravitational waves. For the first time, this made it possible to programmatically separate gravitational wave event clusters from their electromagnetic counterpart reports: the light-based follow-up observations that accompany a gravitational wave detection.
Stage 3: Redshift extraction. Redshift values are buried in prose: “The VLT spectrum shows an absorption feature at z = 1.24,” or “consistent with a host galaxy at redshift 0.35.” To pull them out, the team deployed Mistral, an open-source large language model, backed by three supporting techniques:
- Prompt tuning: carefully engineered instructions specifying exactly what format to extract data in
- Output parsing: structured post-processing that catches and corrects garbled or incomplete model responses
- Retrieval-Augmented Generation (RAG): rather than feeding every Circular to the model, the system first retrieves only the most relevant documents via a neural search index, then passes those to Mistral for extraction
None of this requires training data. No labeled examples of “here is a Circular, here is the redshift.” The model generalizes entirely from prompt instructions and retrieval context.
Results were benchmarked against the manually curated Neil Gehrels Swift Observatory gamma-ray burst (GRB) table, a gold-standard reference built by human experts over years. The LLM pipeline correctly identified redshift values in 97.2% of Circulars that contained them, and the neural RAG retrieval correctly flagged 96.8% of redshift-containing documents from the broader archive.
Why It Matters
Astronomy is entering an era of data deluge. The Rubin Observatory will generate millions of transient alerts per night, new gravitational wave detectors will multiply neutron star merger discoveries, and fast radio burst surveys are expanding rapidly. The GCN Circulars database will only grow faster. Without automation, the gap between data generated and data analyzed will widen into a chasm.
Beyond the immediate application, the paper makes a conceptually important point: LLMs can act as flexible, general-purpose scientific data extractors without retraining, as long as the retrieval and prompting infrastructure is well-designed. That’s a real proof of concept for astroinformatics, the growing effort to use AI to mine the accumulated written record of astronomy. The same approach could extend to other scientific alert networks, arXiv preprints, or observation logs buried in legacy databases.
Every field has its pile of unstructured text. This team just showed how to start reading it.
Bottom Line: A surprisingly simple combination of off-the-shelf LLMs and retrieval tools can extract structured data from 30 years of messy astronomical reports with near-perfect accuracy, pointing toward how AI can tap into science’s vast unstructured archives.
IAIFI Research Highlights
This work connects transformer-based NLP with multi-messenger astrophysics, applying modern language models to one of astronomy's most pressing data management challenges: parsing three decades of unstructured observational reports from NASA's GCN alert network.
Retrieval-augmented generation with prompt engineering achieves near-human accuracy (97.2%) on scientific information extraction without any task-specific fine-tuning, showing what's possible when deploying AI in data-rich scientific domains.
By automating gamma-ray burst redshift extraction and separating gravitational wave event clusters from electromagnetic counterpart reports, this pipeline speeds up multi-messenger astronomy, the frontier where gravitational waves and light are observed together from the same cosmic events.
Future work will extend the pipeline to other transient types and integrate it into live GCN alert streams; the paper is available at [arXiv:2511.14858](https://arxiv.org/abs/2511.14858).
Original Paper Details
Large Language Model Driven Analysis of General Coordinates Network (GCN) Circulars
2511.14858
["Vidushi Sharma", "Ronit Agarwala", "Judith L. Racusin", "Leo P. Singer", "Tyler Barna", "Eric Burns", "Michael W. Coughlin", "Dakota Dutko", "Courey Elliott", "Rahul Gupta", "Ashish Mahabal", "Nikhil Mukund"]
The General Coordinates Network (GCN) is NASA's time-domain and multi-messenger alert system. GCN distributes two data products - automated ``Notices,'' and human-generated ``Circulars,'' that report the observations of high-energy and multi-messenger astronomical transients. The flexible and non-structured format of GCN Circulars, comprising of more than 40500 Circulars accumulated over three decades, makes it challenging to manually extract observational information, such as redshift or observed wavebands. In this work, we employ large language models (LLMs) to facilitate the automated parsing of transient reports. We develop a neural topic modeling pipeline with open-source tools for the automatic clustering and summarization of astrophysical topics in the Circulars database. Using neural topic modeling and contrastive fine-tuning, we classify Circulars based on their observation wavebands and messengers. Additionally, we separate gravitational wave (GW) event clusters and their electromagnetic (EM) counterparts from the Circulars database. Finally, using the open-source Mistral model, we implement a system to automatically extract gamma-ray burst (GRB) redshift information from the Circulars archive, without the need for any training. Evaluation against the manually curated Neil Gehrels Swift Observatory GRB table shows that our simple system, with the help of prompt-tuning, output parsing, and retrieval augmented generation (RAG), can achieve an accuracy of 97.2 % for redshift-containing Circulars. Our neural search enhanced RAG pipeline accurately retrieved 96.8 % of redshift circulars from the manually curated database. Our study demonstrates the potential of LLMs, to automate and enhance astronomical text mining, and provides a foundation work for future advances in transient alert analysis.